本文主要是介绍【Modelground】个人AI产品MVP迭代平台(4)——Mediapipe视频处理网站介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 介绍
- 模型配置
- 输入输出
- 核心实现(源码)
- 总结
介绍
这篇文章我将硬核介绍Modelground的第一个产品——Mediapipe视频处理!网站入口为https://tryiscool.space/ml-video/,如图所示,欢迎体验。

tip: 由于服务器带宽较小,初次加载模型需要一定的等待时间。
Mediapipe视频处理的目标是:在线生成Mediapipe各类模型处理后的视频,支持导出视频和自定义样式。 效果如下图所示。
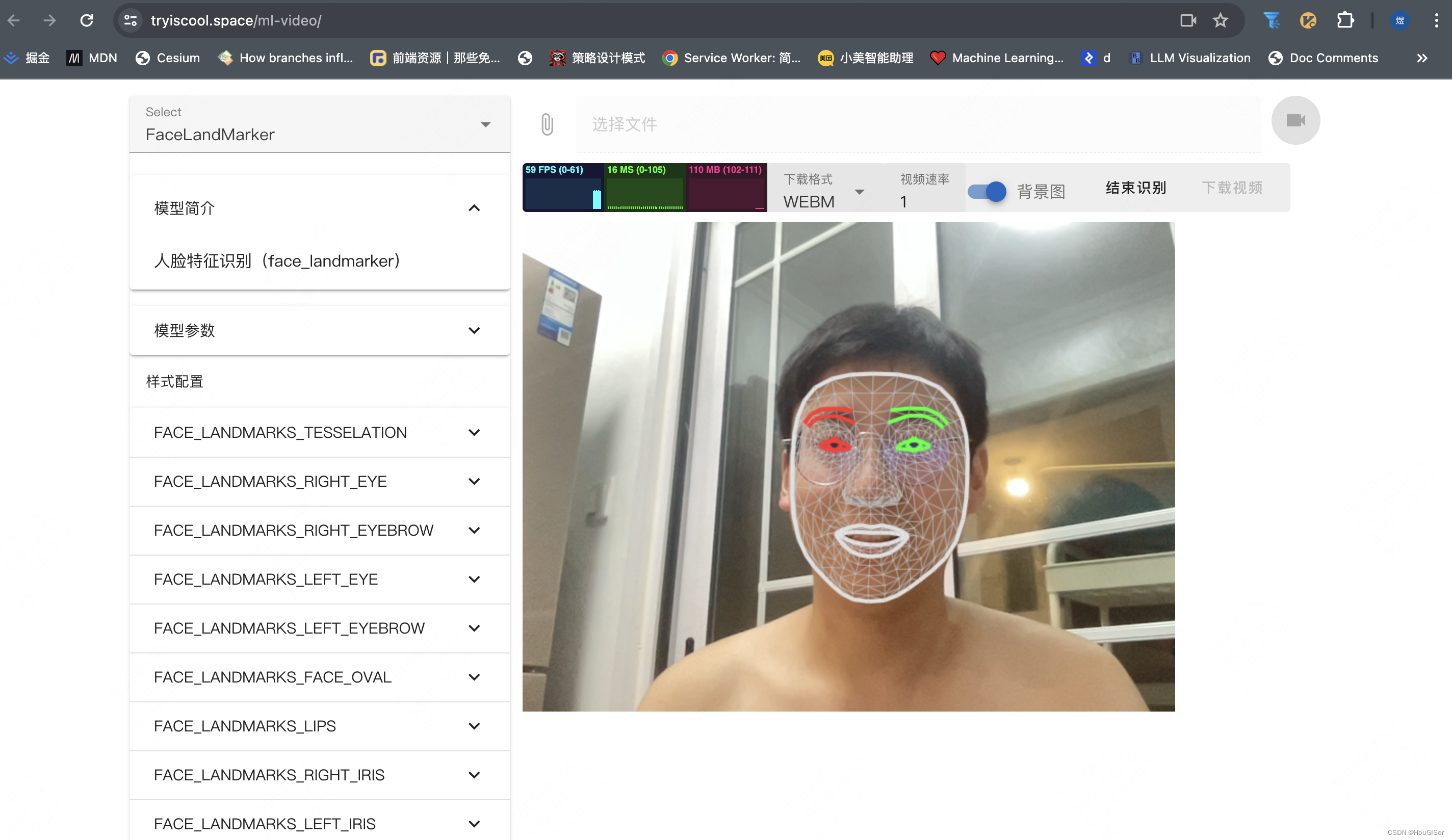
整个网站分为两部分,左侧为模型选择器和模型配置模块,右侧上部分为视频流选择及导出选项,右侧下部分为视频处理效果。
模型配置
目前支持5个模型,投篮命中识别模型、脸部识别、姿态识别、手部识别和对象检测。

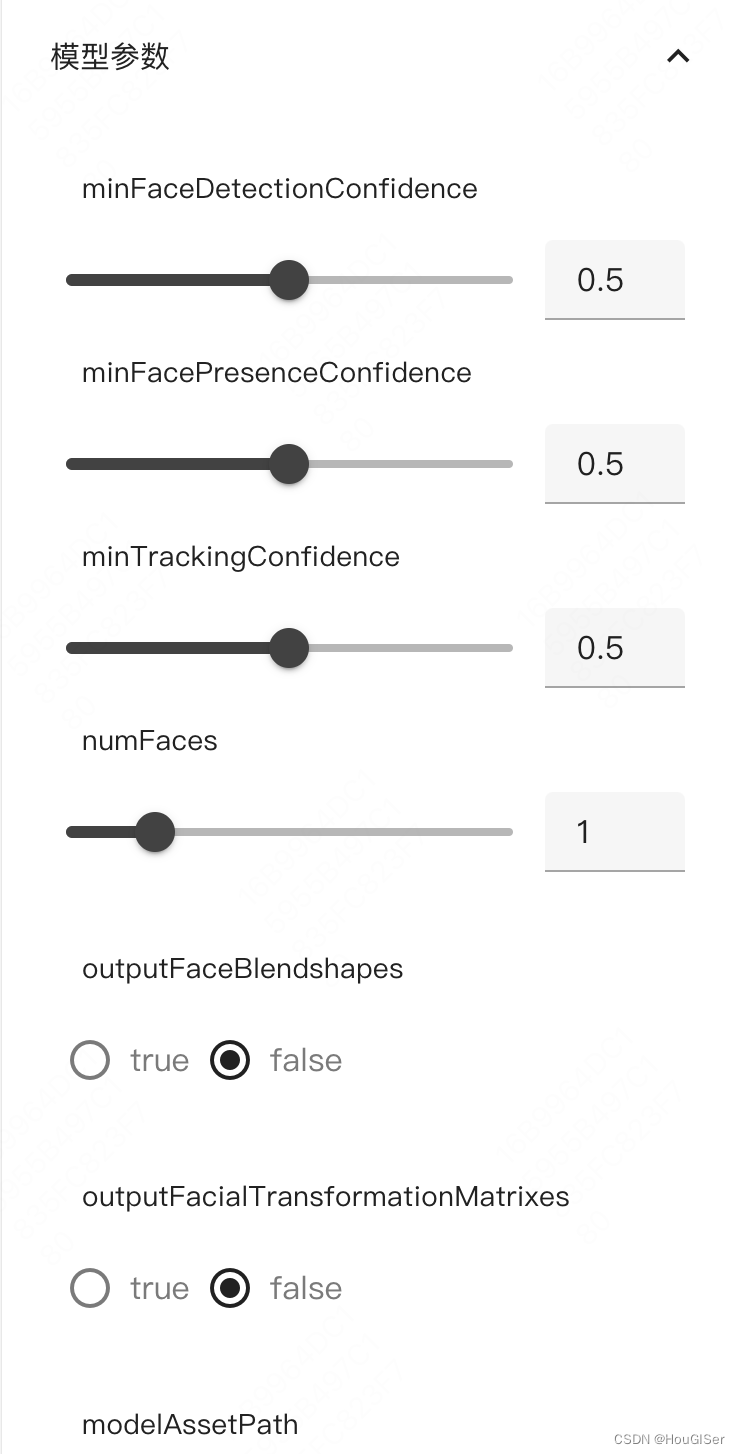
模型参数配置,暴露出模型的所有参数,供使用者自行调整,找出最佳配置。另外,每个模型提供了部分可选预训练模型,体积不同,效果也不一样。具体可参考官网。
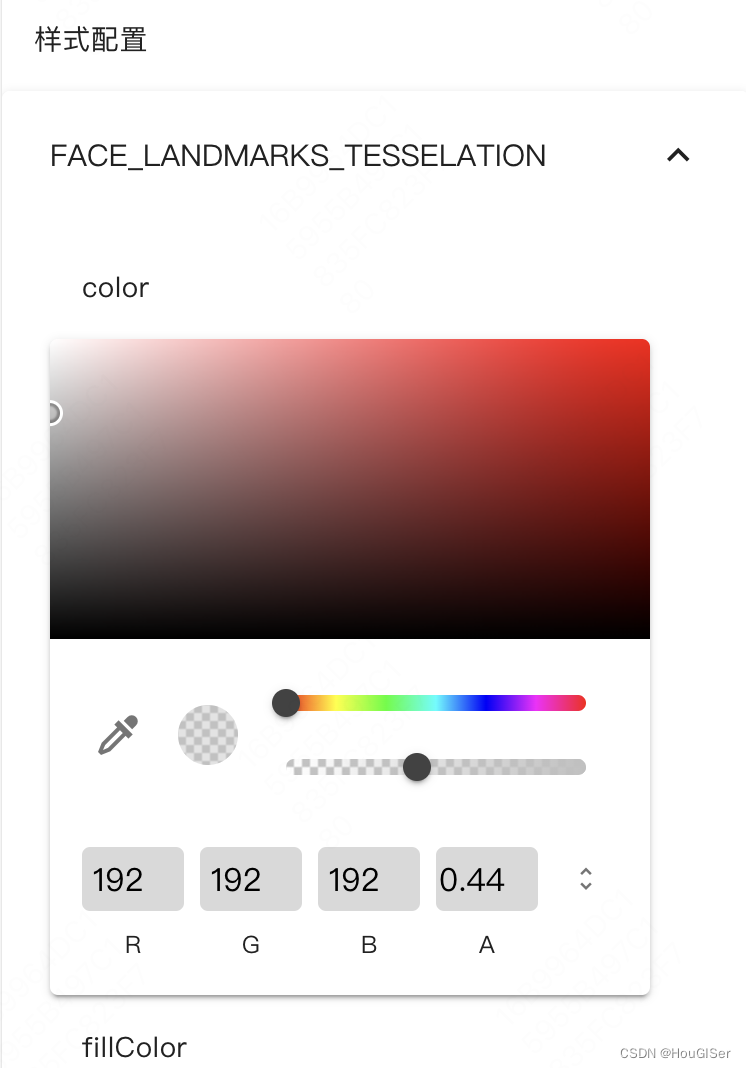
样式配置可以对模型的输出做自定义的配置,例如脸部识别结果包括左眼、左眉毛、左瞳孔、嘴唇、脸廓等,你都可以修改配置。
输入输出
输入有两种形式,一种是视频/图片文件,另一种是摄像头。
下方左侧是视频处理性能监控组件。下载格式分为webm/gif,默认webm,如果选择gif,录制时间不宜太长,否则gif文件过大。视频速率是视频原速度的倍数,默认原速度(1倍),可调整。背景图开关决定输出图片/视频是否包含原图/视频。

点击开始识别后,可点击结束识别,输出结果即可下载。以下是一个简短的人脸识别gif结果。是不是挺酷炫?

核心实现(源码)
首先,前一章我们说过,Modelground的工程架构是monorepo多项目架构。其公共模型库被提取到了单独的项目中,供其余项目通过workspace的方式直接引用,而不需要再发包。那么这个公共模型库,我命名为mediapipe-model-core。(当然,这个npm包是publish过的,不过近期并没有更新,也没有很好的说明文档,后期如果大家感兴趣,我可以继续维护,但请告知我。)其项目结构如下图所示。

封装后的模型放在model文件夹下,base.ts是模型的抽象基类,所有具体模型都继承该基类,代码如下:
// model/bast.tsimport { FilesetResolver } from "@mediapipe/tasks-vision";
import _cloneDeep from "lodash-es/cloneDeep";
import { getModelName } from ".";
import { IParams, WasmFileset } from "./type";let vision: WasmFileset;/*** 封装模型基类*/
export abstract class MediaPipeModal {public _modelInstance: any;public params: any[] = [];public config: Record<string, unknown> = {};public styleConfig: Record<string, unknown> = {};public model: any;constructor() {}/*** 初始化及加载模型*/async init(baseUrl: string = "/") {this.initConfig(baseUrl);const vision = await this.initVison(baseUrl);this._modelInstance = await this.model.createFromOptions(vision,this.config);}// wasm只加载一次async initVison(baseUrl: string) {if (vision) {return vision;}vision = await FilesetResolver.forVisionTasks(baseUrl + "wasm");return vision;}getOptions() {return _cloneDeep(this.config);}getStyle() {return _cloneDeep(this.styleConfig);}/*** 参数初始化*/initConfig(baseUrl: string) {this.params.forEach((item) => {if (item.name === "modelAssetPath") {this.config.baseOptions = {[item.name]: baseUrl + item.default,};} else {this.config[item.name] = item.default;}});}initParams() {console.log("init params");}/*** 参数修改* @param config*/async setOptions(config: any) {this.config = { ...this.config, ...config };await this._modelInstance.setOptions(this.config);this.initParams();}setStyle(config: any) {this.styleConfig = _cloneDeep(config);localStorage.setItem(getModelName(), JSON.stringify(this.styleConfig));}detect(image: HTMLImageElement) {return this._modelInstance.detect(image);}detectForVideo(video: HTMLVideoElement, timestamp: number) {return this._modelInstance.detectForVideo(video, timestamp);}/*** 子类实现各自模型的输出处理*/abstract processResults(image: HTMLImageElement | undefined,canvas: HTMLCanvasElement,res: any,options: IParams): void;abstract processVideoResults(video: HTMLVideoElement | undefined,canvas: HTMLCanvasElement,res: any,options: IParams): void;
}
由于Mediapipe模型是通过url加载的,而npm包无法发包成可访问的静态资源,因此具体的模型,都由各个引用项目自行提供,只需要在init时传入模型路径即可。
子类以人脸识别为例,代码如下:
// model/face-land-marker/index.tsimport { MediaPipeModal } from "../base";
import { FaceLandmarker, DrawingUtils } from "@mediapipe/tasks-vision";
import { IParams } from "../type";/*** @see https://developers.google.com/mediapipe/solutions/vision/face_landmarker*/
export class FaceLandMarker extends MediaPipeModal {// 模型名static modelName = "FaceLandMarker";// 模型列表modelPath = [{path: "models/FaceLandMarker/face_landmarker.task",size: 3758596,},];// 模型描述description = "人脸特征识别(face_landmarker)";// 模型参数params = [{name: "minFaceDetectionConfidence",type: "float",range: [0, 1],default: 0.5,},{name: "minFacePresenceConfidence",type: "float",range: [0, 1],default: 0.5,},{name: "minTrackingConfidence",type: "float",range: [0, 1],default: 0.5,},{name: "numFaces",type: "integer",range: [0, 5],default: 1,},{name: "outputFaceBlendshapes",type: "boolean",range: [true, false],default: false,},{name: "outputFacialTransformationMatrixes",type: "boolean",range: [true, false],default: false,},{name: "modelAssetPath",type: "enum",range: this.modelPath.map((item) => item.path),default: this.modelPath[0].path,},{name: "runningMode",type: "enum",range: ["IMAGE", "VIDEO"],default: "VIDEO",},];// 识别结果样式styleConfig = {FACE_LANDMARKS_TESSELATION: { color: "#C0C0C070", lineWidth: 1 },FACE_LANDMARKS_RIGHT_EYE: { color: "#FF3030" },FACE_LANDMARKS_RIGHT_EYEBROW: { color: "#FF3030" },FACE_LANDMARKS_LEFT_EYE: { color: "#30FF30" },FACE_LANDMARKS_LEFT_EYEBROW: { color: "#30FF30" },FACE_LANDMARKS_FACE_OVAL: { color: "#E0E0E0" },FACE_LANDMARKS_LIPS: { color: "#E0E0E0" },FACE_LANDMARKS_RIGHT_IRIS: { color: "#FF3030" },FACE_LANDMARKS_LEFT_IRIS: { color: "#30FF30" },};constructor() {super();this.model = FaceLandmarker;const storage = localStorage.getItem(FaceLandMarker.modelName);this.styleConfig = storage ? JSON.parse(storage) : this.styleConfig;}processResults(image: HTMLImageElement | HTMLVideoElement | undefined,canvas: HTMLCanvasElement,res: any,options: IParams) {const ctx = canvas.getContext("2d")!;ctx.clearRect(0, 0, canvas.width, canvas.height);if (!!options?.renderImage) {ctx.drawImage(image!, 0, 0, canvas.width, canvas.height);}const drawingUtils = new DrawingUtils(ctx);for (const landmarks of res.faceLandmarks) {drawingUtils.drawConnectors(landmarks,FaceLandmarker.FACE_LANDMARKS_TESSELATION,this.styleConfig.FACE_LANDMARKS_TESSELATION);drawingUtils.drawConnectors(landmarks,FaceLandmarker.FACE_LANDMARKS_RIGHT_EYE,this.styleConfig.FACE_LANDMARKS_RIGHT_EYE);drawingUtils.drawConnectors(landmarks,FaceLandmarker.FACE_LANDMARKS_RIGHT_EYEBROW,this.styleConfig.FACE_LANDMARKS_RIGHT_EYEBROW);drawingUtils.drawConnectors(landmarks,FaceLandmarker.FACE_LANDMARKS_LEFT_EYE,this.styleConfig.FACE_LANDMARKS_LEFT_EYE);drawingUtils.drawConnectors(landmarks,FaceLandmarker.FACE_LANDMARKS_LEFT_EYEBROW,this.styleConfig.FACE_LANDMARKS_LEFT_EYEBROW);drawingUtils.drawConnectors(landmarks,FaceLandmarker.FACE_LANDMARKS_FACE_OVAL,this.styleConfig.FACE_LANDMARKS_FACE_OVAL);drawingUtils.drawConnectors(landmarks,FaceLandmarker.FACE_LANDMARKS_LIPS,this.styleConfig.FACE_LANDMARKS_LIPS);drawingUtils.drawConnectors(landmarks,FaceLandmarker.FACE_LANDMARKS_RIGHT_IRIS,this.styleConfig.FACE_LANDMARKS_RIGHT_IRIS);drawingUtils.drawConnectors(landmarks,FaceLandmarker.FACE_LANDMARKS_LEFT_IRIS,this.styleConfig.FACE_LANDMARKS_LEFT_IRIS);}}processVideoResults(video: HTMLVideoElement | undefined,canvas: HTMLCanvasElement,res: any,options: IParams) {this.processResults(video, canvas, res, options);}
}
引用也十分简单,mediapipe-model-core导出了setModelName、getModelName和getModelIns三个方法,代码如下:
// model/index.tsimport { FaceLandMarker } from "./face-land-marker";
import { PoseLandMarker } from "./pose-land-marker";
import { HandLandMarker } from "./hand-land-marker";
import { BasketballGoalDetection } from "./basketball-goal-detection";
import { ObjectDetection } from "./object-detection";export * from "./basketball-goal-detection";
export * from "./face-land-marker";
export * from "./hand-land-marker";
export * from "./object-detection";
export * from "./pose-land-marker";/*** 支持的模型列表*/
export const ModelList = {[BasketballGoalDetection.modelName]: BasketballGoalDetection,[FaceLandMarker.modelName]: FaceLandMarker,[PoseLandMarker.modelName]: PoseLandMarker,[HandLandMarker.modelName]: HandLandMarker,[ObjectDetection.modelName]: ObjectDetection,
};const modelInstance: Record<string,| PoseLandMarker| FaceLandMarker| HandLandMarker| ObjectDetection| BasketballGoalDetection
> = {};let modelName: string = PoseLandMarker.modelName;let baseUrl: string = "/";/*** 获取加载好的模型实例* @returns 模型实例*/
export async function getModelIns() {if (!modelInstance[modelName]) {modelInstance[modelName] = new ModelList[modelName]();await modelInstance[modelName].init(baseUrl);}return modelInstance[modelName];
}/*** 获取当前的模型名称* @returns 模型名称*/
export function getModelName() {return modelName;
}/*** 切换当前模型* @param name 模型名称*/
export async function setModelName(name: string, url: string = "/") {baseUrl = url || "/";if (Object.keys(ModelList).includes(name)) {modelName = name;const model = await getModelIns();model.initParams();} else {console.error("未知模型名");}
}
以上都是mediapipe-model-core仓库的核心代码,那么其他项目要引用这个包,如何使用呢?
以人脸检测模型为例,具体用法如下:
import { FaceLandMarker, setModelName } from 'mediapipe-model-core';async function init() {// 设置模型await setModelName(FaceLandMarker.modelName, '/');// 获取模型实例const model = await getModelIns();// 模型识别const res = model.detectForVideo(video, startTimeMs);// 模型结果渲染await model.processVideoResults(video, canvas, res);
}
其中,设置模型需要在比较早的生命周期就调用,例如vue的mounted,因为模型的加载时间较久。
后续的模型识别、和结果渲染,都是基于requestAnimationFrame循环调用的,本质上,就是调用model.detectForVideo传入视频在startTimeMs时刻的图片,模型识别,结果绘制在传入的canvas上。
值得一提的是,目前mediapipe-model-core中有部分模型内部采用了web worker和离屏canvas技术,渲染性能较高。此外,为了解决模型缓存问题,网站采用了service worker技术,以缓存模型。
其余技术细节我就不赘述,并不难。
总结
Mediapipe视频处理是Modelground的第一个孵化MVP产品。其最初是为了mediapipe-model-core库提供可视化效果,后期经过一定的设计,产出了这么一个不错的产品。其功能丰富,且特点鲜明:可导出处理后的视频,完全免费。
Mediapipe视频处理还具有很大的优化空间,例如,集成视频的编辑能力、音效等等。
如果你喜欢这篇文章,请给我一些收藏、点赞。你的支持是我创作的动力!
这篇关于【Modelground】个人AI产品MVP迭代平台(4)——Mediapipe视频处理网站介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







