本文主要是介绍【Python机器学习】NMF——模拟数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
与使用PCA不同,我们需要保证数据是正的,NMF能够对数据进行操作。这说明数据相对于原点(0,0)的位置实际上对NMF很重要。因此,可以将提取出来的非负向量看作是从(0,0)到数据的方向。
举例:NMF在二维玩具数据上的结果:
import mglearn.plots
import matplotlib.pyplot as pltmglearn.plots.plot_nmf_illustration()
plt.show()
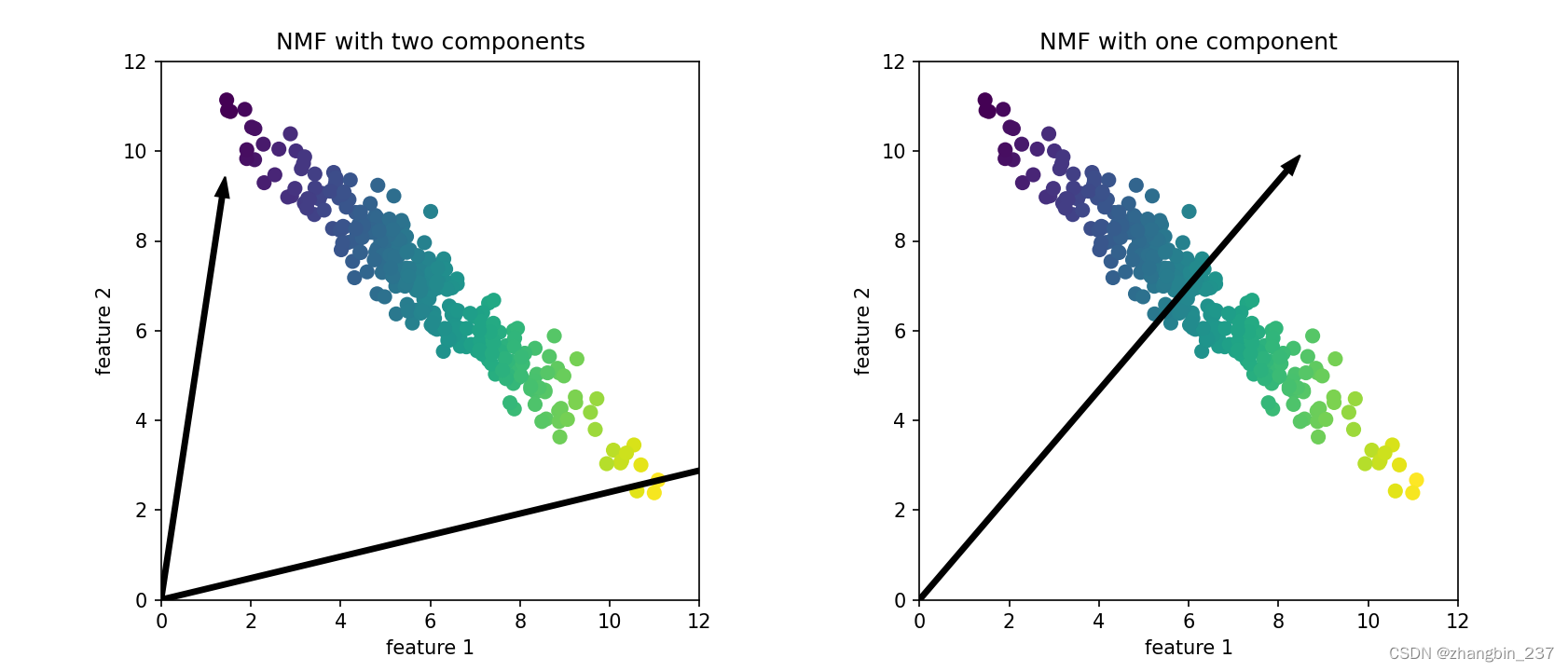
对于两个分量的NMF(左图),显然所有数据点都可以写成这两个分量的正数组合。如果有足够多的分量能够完美的重建数据(分量个数与特征个数相同),那么算法会选择指向数据极值的方向。
如果我们仅使用一个分量,那么NMF会创建一个指向平均值的分量,因为指向这里可以对数据做最好的解释。可以看到,与PCA不同,减少分量个数不仅会删除一些方向,而且会创建一组完全不同的分量。NMF的分量也没有按照任何特定方法排序,所以不存在“第一分量”,所有分量的地位平等。
NMF使用了随机初始化,根据随机种子的不同可能会产生不同的结果。在相对简单的情况下(比如两个分量的模拟数据),所有数据都可以被完美的解释,那么随机性的影响很小。在更加复杂的情况下,影响可能会很大。
这篇关于【Python机器学习】NMF——模拟数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






