本文主要是介绍信息学奥赛初赛天天练-23-CSP-J2023基础题-指针、链表、哈夫曼树与哈夫曼编码的实战应用与技巧大揭秘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PDF文档公众号回复关键字:20240608

单项选择题(共15题,每题2分,共计30分:每题有且仅有一个正确选项)
4 假设有一个链表的节点定义如下:
struct Node {int data; Node* next;
};
现在有一个指向链表头部的指针:Node* head。如果想要在链表中插入一个新节点,其成员data的值为42,并使新节点成为链表的第一个节点,下面哪个操作是正确的?( )
A Node* newNode = new Node; newNode->data = 42; newNode->next = head; head = newNode;
B Node* newNode = new Node; head->data = 42; newNode->next = head; head = newNode;
C Node* newNode = new Node; newNode->data = 42; head->next = newNode;
D Node* newNode = new Node; newNode->data = 42; newNode->next = head;
10 假设有一组字符{a,b,c,d,e,f},对应的频率分别为5%,9%,12%,13%,16%,45%。请问以下哪个选项是字符a,b,c,d,e,f分别对应的一组哈夫曼编码?( )
A 1111,1110,101,100,110,0
B 1010,1001,1000,011,010,00
C 000,001,010,011,10,11
D 1010,1011,110,111,00,01
2 相关知识点
1 指针
指针是 C++语言中广泛使用的一种数据类型,运用指针编程是 C++语言最主要的风格之一
指针是一个变量,其值为另一个变量的地址,即,内存位置的直接地址
基础数据类型指针
#include <iostream>
using namespace std;
int main (){int a = 20; // 实际变量的声明int *ip; // 指针变量的声明ip = &a; // 在指针变量中存储 a 的地址cout << "指针对应变量的值: ";cout << a << endl;// 输出在指针变量中存储的地址cout << "指针变量的值,指针指向的变量的地址: ";cout << ip << endl;// 访问指针中地址的值cout << "指针指向地址对应变量的值(a的值): ";cout << *ip << endl;return 0;
}
结构体指针
#include<bits/stdc++.h>
using namespace std;
/*定义一个结构体,包括姓名和年龄
*/
struct student{string name;int age;
};
int main(){student stu1;//声明 student stu1stu1.name="张三";// 张三赋值 namestu1.age=21;// 21赋值 agestudent *p1=&stu1;//声明指针p1 指向 &stu1//指针去结构体内成员需要用 -> cout<<"姓名:"<<p1->name<<",年龄:"<<p1->age; return 0;
}
2) 链表的插入
指针指向地址的变换
在newNode1前插入newNode2
/*1 刚开始head指针指向newNode12 需要newNode2的next指向newNode13 head指向newNode2
*/
#include<bits/stdc++.h>
using namespace std;struct Node{int No;Node* next;
}; int main(){Node* newNode1=new Node;//newNode1 地址0xbe3ea0 指向 No=1变量 newNode1->No=1;Node* head=newNode1;//指针head 指向 newNode1地址0xbe3ea0Node* newNode2=new Node;//newNode2 地址0xbe3ee0 指向 No=2变量 newNode2->No=2;newNode2->next=head;//newNode2->next 指针指向指针head对应地址0xbe3ea0 head=newNode2;//指针head指向 0xbe3ee0cout<<head->No<<" "<<head->next->No;return 0;
}
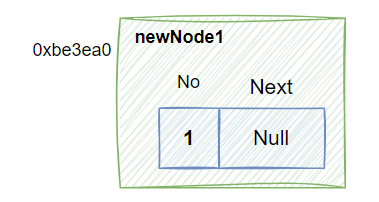
创建newNode1
Node* newNode1=new Node;//newNode1 地址0xbe3ea0 指向 No=1变量 C++
newNode1->No=1;
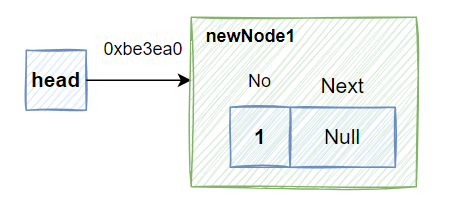
head指针指向newNode1
Node* head=newNode1;//指针head 指向 newNode1地址0xbe3ea0
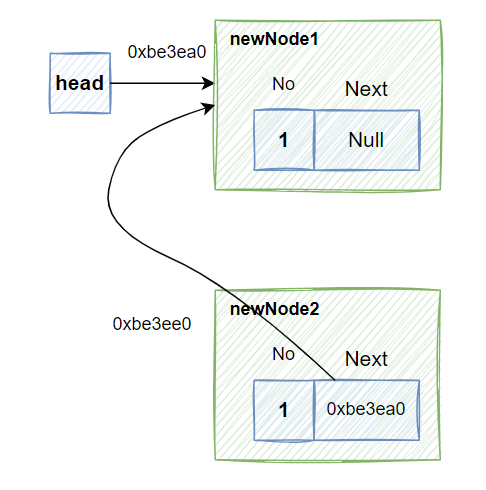
创建newNode2
Node* newNode2=new Node;//newNode2 地址0xbe3ee0 指向 No=2变量
newNode2->No=2;

newNode2的next指向head指针对应地址
newNode2->next=head;//newNode2->next 指针指向指针head对应地址0xbe3ea0
head指针指向newNode2
head=newNode2;//指针head指向 0xbe3ee0
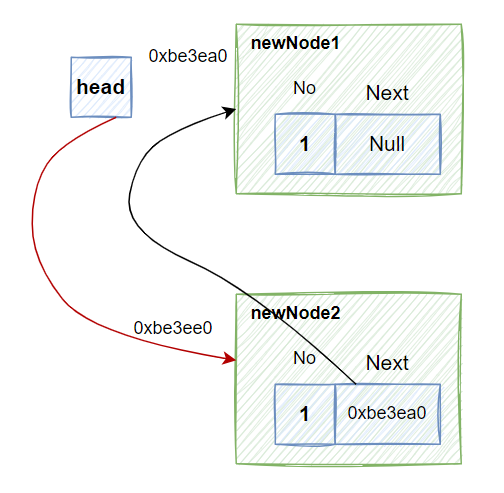
上述操作在头指针head后和newNode1之间插入了newNode2
3) 哈夫曼编码
哈夫曼树
哈夫曼树是带权路径长度WPL最短的二叉树(最优二叉树)
构造哈夫曼树的WPL为35是最小的
哈夫曼树的构造
1 选剩下的两棵根权值最小的树合并成一棵新树
2 新树的根权值等于两棵合并前树的根权值和
3 重复1和2
例题
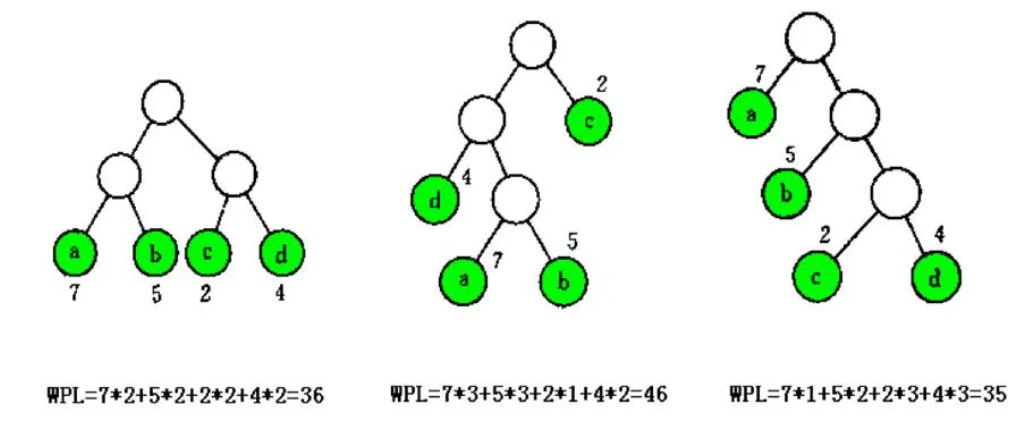
4个点,a、b、c、d,权值分别为7、5、2、4
选根权值最小的两棵树2(c)和4(d)合并,新树的根节点为6
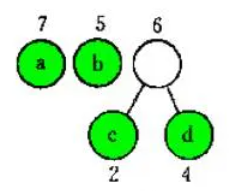
选根权值最小的两棵树5(b)和6合并,新树的根节点为11
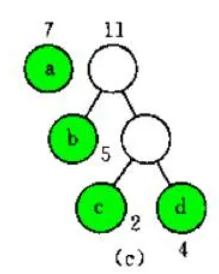
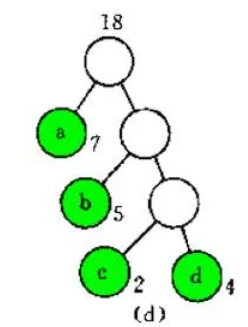
选根权值最小的两棵树7(a)和11合并,新树的根节点为18
哈夫曼编码
对哈夫曼树的左右孩子进行编码称为哈夫曼编码,通常左边为0,右边为1
例题
有5个字母E,M,C,A,D
这5个字母的使用频度分别为{E,M,C,A,D}={1,2,3,3,4}
分析
构造哈夫曼树,并进行编码
用频度为权值生成哈夫曼树,并在叶子上标注对应的字母,在树枝上标注分配码“0”或“1”
对应字母的哈夫曼是编码从根节点开始,每条路径到达叶子结点的01代码排列起来
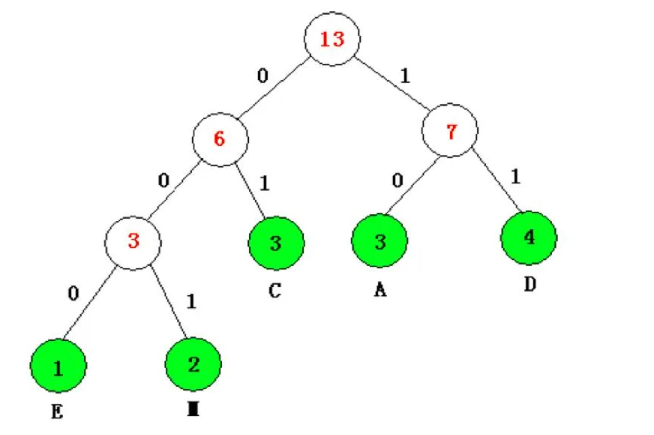
对应的哈夫曼编码
E:000
M:001
C:01
A:10
D:11
哈夫曼编码性质
只对叶子节点进行编码/解码,编码唯一
哈夫曼编码是前缀编码,任何一个字符的编码都不是另一个字符编码的前缀(只有叶子节点编码)
哈夫曼编码左边为0,右边为1是通常规定,也可以左边为1右边为0,但确定后编码是唯一的
3 思路分析
4 假设有一个链表的节点定义如下:
struct Node {int data; Node* next;
};
现在有一个指向链表头部的指针:Node* head。如果想要在链表中插入一个新节点,其成员data的值为42,并使新节点成为链表的第一个节点,下面哪个操作是正确的?( )
A Node* newNode = new Node; newNode->data = 42; newNode->next = head; head = newNode;
B Node* newNode = new Node; head->data = 42; newNode->next = head; head = newNode;
C Node* newNode = new Node; newNode->data = 42; head->next = newNode;
D Node* newNode = new Node; newNode->data = 42; newNode->next = head;
答案 A
插入一个新节点
A
假设head开始指向tmp节点,具体需要如下步骤
//1 创建一个Node节点指针 newNodeNode* newNode = new Node;
//2 通过newNode指针给newNode成员data 赋值为42
newNode->data = 42;
//3 通过newNode指针给newNode成员next 赋值为head指针地址,指向head后续节点tmp
newNode->next = head;
//4 步骤3中新节点已经指向head后续节点tmp,head指向newcode完成插入tmp前
head = newNode;
B
head->data = 42;//和要求不符,要求是对插入节点的data为42
C
//假设head开始指向tmp节点,缺少下面为新节点指向下个节点,tmp被从链表中剔除newNode->next = head;
D
//新节点没有插入到链表中,需要加入如下语句
head = newNode;
10 假设有一组字符{a,b,c,d,e,f},对应的频率分别为5%,9%,12%,13%,16%,45%。请问以下哪个选项是字符a,b,c,d,e,f分别对应的一组哈夫曼编码?( )
A 1111,1110,101,100,110,0
B 1010,1001,1000,011,010,00
C 000,001,010,011,10,11
D 1010,1011,110,111,00,01
答案 A
根据出现的频率对a,b,c,d,e,f构造一棵哈夫曼树
1 频率最小的a和b合并构造1个节点 5+9=14
2 剩下频率最小的2个字符,c和d合并构造1个节点,12+13=25
3 剩下频率最小的2个字符,14和e(16)合并构造1个节点14+16=30
4 剩下频率最小的2个字符,25和30合并构造1个节点,25+30=55
5 剩下频率最小的2个字符,f(45)和55合并构造一个节点45+55=100
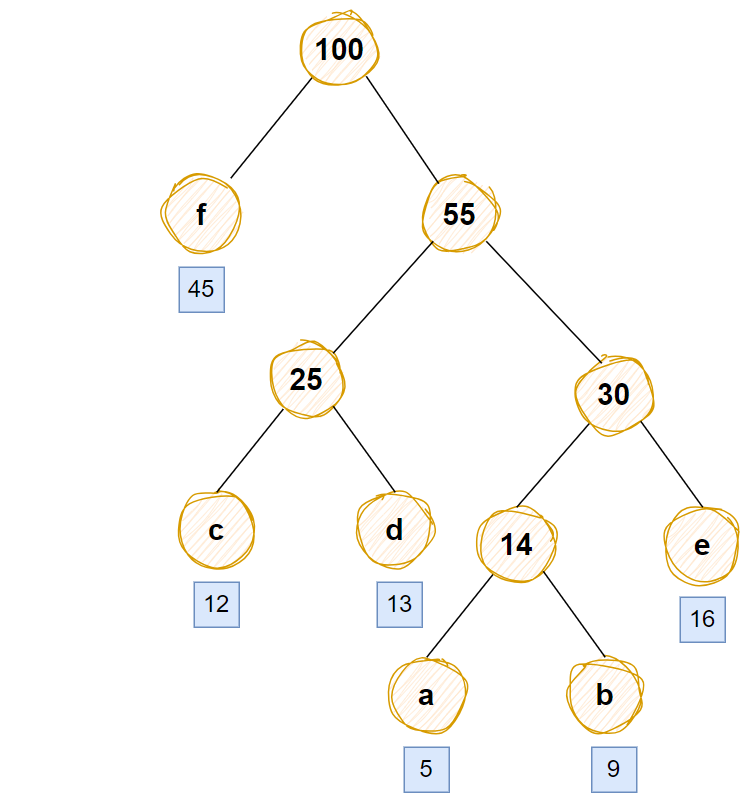
对哈夫曼数进行编码
通常对哈夫曼数上的边左边为0,右边为1进行编码,编码后如下图所示
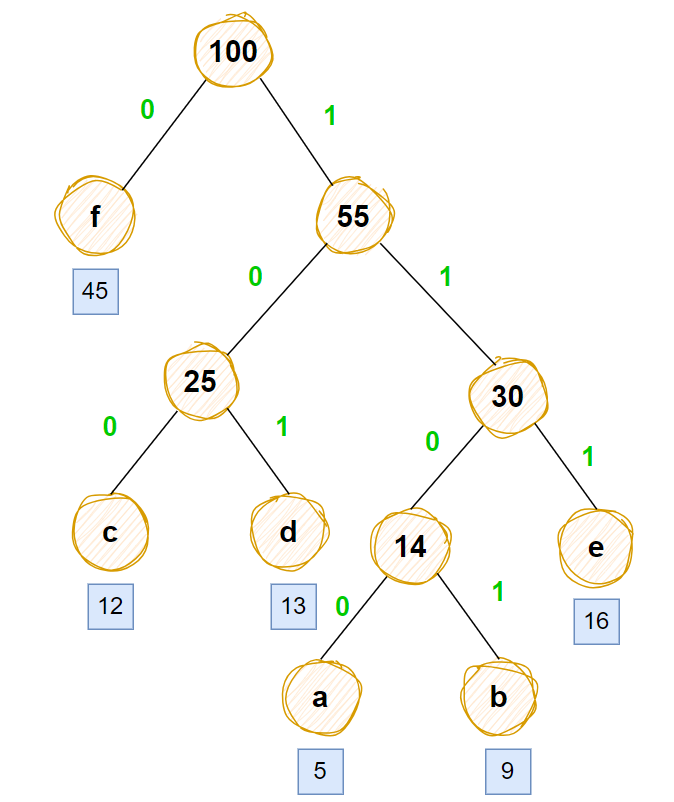
根据上图哈夫曼编码对选项进行分析
有1个1位的哈夫曼编码,选项中只有A有1个1位的哈夫曼编码,其余都没用1位的哈夫曼编码
核对一下A是否正确
A选项abcdef
1111,1110,101,100,110,0
构造哈夫曼树的abcdef
1100,1101,100,101,111,0
由于左右边规定的0和1是可交换的
我们发现c和d最后1位是相反,所以c和d对应边交换一下即可
e也是最后1为是相反的,并且a和b的倒数第2位也都需要交换,所以14和e对应边也可以交换一下
a和b最后1位也都是相反的,所以a和b对应边也可以交换一下
上述操作后对应下图
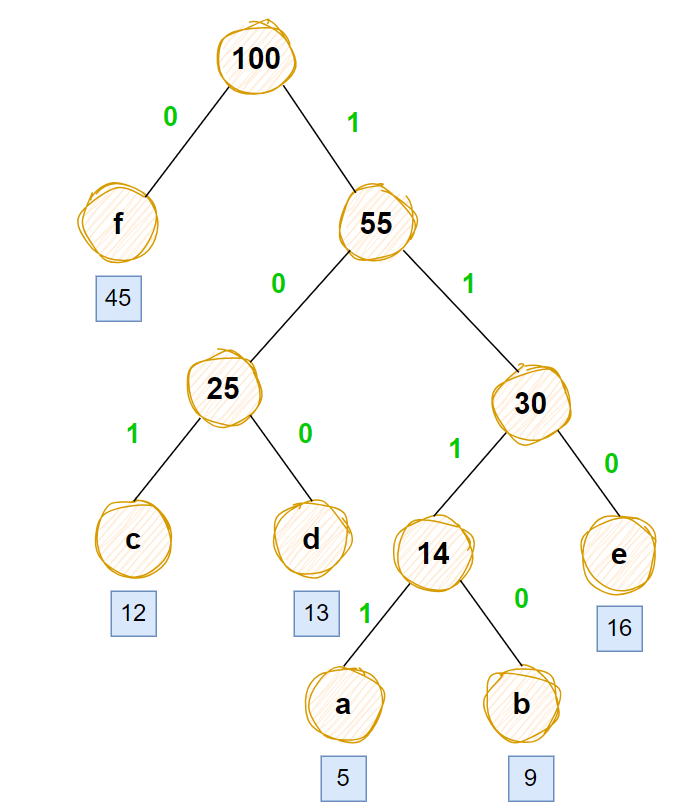
对应abcdef的哈夫曼树
构造哈夫曼树的abcdef
1111,1110,101,100,110,0
和选项A一致
A选项abcdef
1111,1110,101,100,110,0
这篇关于信息学奥赛初赛天天练-23-CSP-J2023基础题-指针、链表、哈夫曼树与哈夫曼编码的实战应用与技巧大揭秘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




