本文主要是介绍深度学习的舌象诊断:从舌头上了解系统性疾病!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先
深度学习算法能否解决东方医学中依靠医生经验的诊断问题?而要实现这个目标,需要什么呢?
用舌头诊断被称为口腔健康的指标,但在东方医学中,舌头也被用来评估全身的状况。换句话说,通过分析舌头的图像,不仅可以发现特定的疾病,还可以同时发现多种疾病。因此,通过提取医生的经验作为特征和学习模型来普及非语言知识的深度学习的引入备受关注。另一方面,有人指出,这些舌象存在一个问题,就是这些舌象有冗余,无法从图像中把握整体特征。
在这项工作中,使用高方差和局部响应归一化来实现多尺度特征分析。所提出的方法可以学习高层次的特征,提供更多的分类信息。因此,它达到了很高的分类性能。
什么是东方医学、中医和舌诊?
东方医学是以中药、针灸为主的东方传统医学。西医是直接用药物或手术治疗身体不好的部分,而东方医学的目的是着眼于整个身体,而不是只治疗不好的部分,方法有针灸、中医等。此外,它还有自己的"密约"概念。"密约"的意思是还没有生病,但还没有健康,目的是防止因疲劳和积累的抵抗力而引起的疾病。
东方医学的诊断方法有"四诊",其中"望闻问切"是从面部表情、外貌等外在特征来把握身体状态的。其中,舌诊可以从舌头的状态中把握身体的状态,以无创的方式高准确度地找出病症点。千百年来,中医通过观察舌头的颜色、形状和质地来判断患者的健康状况。
但是,这种诊断方法主要是根据医生的经验,有主观的一面,所以很难向陌生人推广诊断方法。在此背景下,利用深度学习积累舌头图像并提取特征以简化诊断方法,受到了人们的关注。
传统方法的问题
虽然已经提出了很多基于颜色、形状、纹理等单一特征的模型,并取得了很好的效果,但这些模型只使用了低级特征,很难获得一定的表现力。特别是在舌头图像的异常检测中,需要整个图像的特征来获得高性能。因此,在检测舌头图像的异常时,提取多方面的综合特征,并将这些特征进行高精度整合的方法被认为是有效的。在我们之前的研究-PCANet中,我们从舌头图像中提取了这样复杂的特征。它基于PCA算法和CNN,可以适用于各种数据和任务,微调所需参数少。此外,据报道,当与机器学习分类算法相结合时,它在分类任务中表现良好。据报道,当与机器学习分类算法如K-最近邻(KNN)、SVM和随机森林(RF)相结合时,它的表现也很好。
另一方面,这种方法有两个问题:“数据处理的冗余"和"处理有偏差的样本时不准确”。关于前者,由于PCA的特性,特征值容易膨胀,导致复杂特征图的数据冗余。此外,PCANet假设样本的分布是很均衡的,数据集中的样本数量很大,所以它可能不能很好地应对不均衡的样本。
本研究的目的
在这项工作中,我们解决了这些问题,并提出CHDNet从舌头图像中提取合适的复合整体特征。它是一种监督学习模型,从无监督的临床数据中学习有用的特征,并利用获得的特征学习如何将患者的健康状态分为正常和异常。
本文提出的探索正常和异常舌头图像特征表示的方法采用了四个关键要素:非线性变换、多尺度特征分析、高方差和局部归一化。该方法可以为预测具有偏态分布的健康状况提供稳健的特征表示。
技巧
建议的方法
对于每张图像,我们从图像中去除背景,提取舌体,并应用CHDNet学习图1中正常和异常舌体的特征。然后将图像归一化为一定的高度和重量。
然后将舌头图像分为训练轮和测试轮,并训练卷积核来生成特征表示,将舌头样本分为正常或异常,并对k-folds交叉验证进行评估,对相应的k轮得到的结果进行平均。
本建议有四个重要内容高分散处理实现了每个特征图中的特征分布无冗余的特性。在对局部响应进行归一化和高分散处理后,不同特征图中同一位置的特征仍有冗余。这样我们就可以解决这个问题。
非线性变换层,主成分分析主要集中在线性分类上,所以存在因冗余而降低精度的问题。特别是当它们被用作不平衡数据的异常检测特征时,这个问题就会出现。为了解决这一问题,引入非线性分析,采用多尺度特征分析,提取精度较高的特征。此外,为了提高对变形的响应,在高方差和局部响应归一化之前,引入多尺度特征分析。
CHDNet由三部分组成:PCA滤波器卷积层、非线性变换层和特征池层,如图2所示。
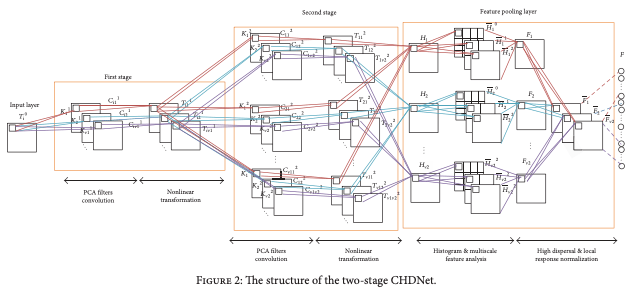
非线性变换
在这一层,除了传统的批量转换过程和PCA转换外,还进行了非线性转换,以减少PCA分类中出现的冗余。在这个PCA过程中,对每幅图像应用非线性,以消除以下方程线性变换中的检测精度的粗糙。
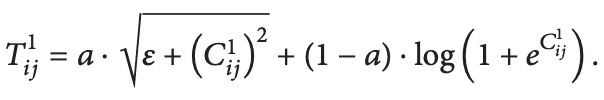
其中T为图像,C1为第一主成分,a和ε为超参数。
此外,由于tanh(x)用于特征的卷积层,存在负值,这与视觉系统的原理相矛盾。因此,在每个卷积层后增加一个非线性变换层,其效果是将这个负值作为噪声处理。
功能池
除上述非线性变换外,该层的其他功能还包括"直方图–将像素转换为[0,255]的整数"、“多尺度特征分析–将每个直方图中的图像按分辨率汇总为特征”、“高方差–避免退化状态,增加特征间的竞争”、“局部响应归一化–不同的特征。在地图中同一位置的每个特征之间进行归一化处理,以防止冗余”。通过对输入图像进行这一系列处理,正常和异常特征比以前的方法更加突出。转化公式请参考论文。
实验准备
共收集医院267名胃炎患者和48名健康志愿者的315张图片。在特征提取步骤的训练阶段,随机选取40个正常对象和44个异常对象作为训练集,约占总图像的26.67%,用于训练卷积核和确定参数。然后,学习的内核和参数被用于提取其余231个样本的特征。结果平均为10次,交叉验证运行5次。为了评价所提出的方法和传统方法的性能,几个评价指标(精度。灵敏度、特异性、准确性和回收率)。
结果
与传统方法的比较
本次评估的目的是确定所提出的方法与之前的方法PCANet相比是否提高了性能。在本次评估中,我们使用LIBLINEAR SVM作为分类器。
结果表明,提出的高分散(HD)、局部响应归一化(LRN)、多尺度特征分析(MFA)和非线性变换(NT)的组合与PCANet相比,提高了识别率:从84.77%提高到91.44%(约7%)。另外,在样品不平衡方面,所提出的方法使灵敏度略有下降,但特异性有所提高。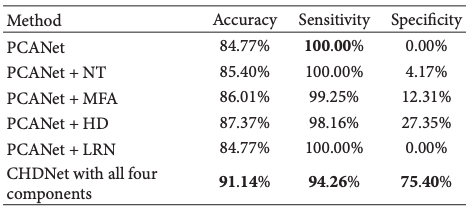
分类器的比较
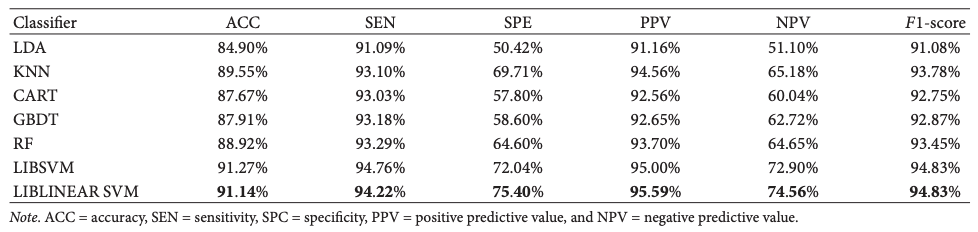
本次评估的目的是确定哪个分类器在检测异常图像时表现最好。
我们比较了使用LIBLINEAR SVM和其他分类器–LDA、KNN、CART、GBDT和RF作为分类器代替LIBSVM的CHDNet的性能–当样本数远小于特征数时,LIBLINEAR SVM的性能优于LIBSVM。比特征数更多–当样本数远小于特征数时,LIBLINEAR SVM的表现比LIBSVM更好。样本数为315个,每个样本中的特征数为43008个,说明LIBLINEAR SVM表现较好。
从精度、特异性、准确度、召回率和F1得分来看,LIBLINEAR SVM的整体性能在下表6种分类器中是最好的,精度91.14%–比LDA高6.24%。同时,与基于距离的模型和树形结构模型相比,特异性从3%提高到25%。通过对比可以看出,参数最优的SVM分类器的性能优于其他方法.LIBLINEAR SVM方法的性能准确率提高到91.14%,在其他分类器中是最好的。
考虑
舌象是东方医学的诊断标准之一,曾有可能无创评估整体身体状况,识别身体疾病。然而,传统模型存在着冗余性和对有偏差样本的检测精度低的问题(特别是在检测异常图像时)。在本研究中,我们提出了一种利用CHDNet这种高度分布式的模型,提取适当的特征进行图像异常检测的模型。评价结果表明,该模型的性能高于传统模型。
但我对此事的看法是这样的。
首先,不清楚为什么选择Linear SVM作为分类器,SVM通常使用RBF内核,但当需要快速计算处理海量数据时,就会使用Linear。作者解释说,原因是特征数远大于样本数,发现Linear的精度高于SVM-RBF内核的精度。不过,造成这一结果的原因没有告诉大家,也不清楚原因。
引入所提出的方法特有的非线性变换的下一个原因是卷积层的tanh(x)中存在负值,但不清楚是否考虑了其他方法,例如,使用ReLU激活函数。在图像分析领域,可以想象,激活函数可以用来剔除负值。在图像分析领域,可以设想使用激活函数:ReLU来处理负值的噪声,但没有明确说明不使用它的原因(或不能引入它),有人认为应该明确说明像现在这样的非线性变换比ReLU函数更有意义这一点。
结论
在本文中,我们提出了一种使用无监督特征学习方法进行舌头图像分类的新型框架。它使用CHDNet通过学习特征来训练一个加权的LIBLINEAR SVM分类器来检测异常患者。实验结果表明,与其他方法相比,我们的新框架和加权LIBLINEAR SVM的组合具有最好的预测性能。
这篇关于深度学习的舌象诊断:从舌头上了解系统性疾病!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



