本文主要是介绍算法人生(20):从“自注意力机制”看“个人精力怎么管”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们知道在ChatGPT中,Transformer模型扮演着重要的角色。Transformer 模型通过自注意力机制来建模序列中的依赖关系,从而实现对序列数据的处理的。因为传统的循环神经网络(RNN)和卷积神经网络(CNN)在处理长距离依赖问题上存在一定的局限性,而自注意力机制能够在不受序列长度限制的情况下,同时考虑序列中所有位置的信息,因此能够更好地捕捉序列的长距离依赖关系。下面我们先来看下Transformer 的构成。
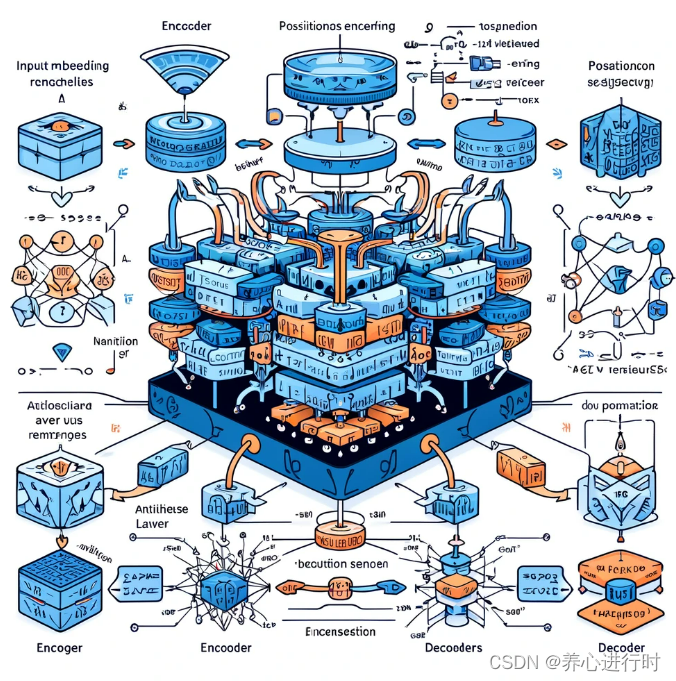
Transformer 模型由编码器(Encoder)和解码器(Decoder)组成,每个部分由多个相同的层堆叠而成。每个层都由两个子层组成:多头自注意力层和全连接前馈网络层。编码器用于将输入序列编码为一系列抽象表示,而解码器则用于从这些表示中生成目标序列。Transformer 模型的大致步骤如下:
-
输入表示:首先,将输入序列中的每个词或者标记转换为其对应的词嵌入表示,通常使用预训练的词嵌入模型来获取词向量。
-
编码器的堆叠:将输入序列的词嵌入表示输入给编码器的第一个层,然后经过多个相同的编码器层进行堆叠处理。每个编码器层的输出作为下一个编码器层的输入。
-
解码器的堆叠:将目标序列的词嵌入表示输入给解码器的第一个层,然后经过多个相同的解码器层进行堆叠处理。每个解码器层的输出作为下一个解码器层的输入。
-
自注意力和前馈网络层的计算:在编码器和解码器的每个层中,分别执行多头自注意力机制和全连接前馈网络的计算,以生成新的表示。
-
最终输出:解码器的最后一层的输出经过一个线性层和 Softmax 函数,生成最终的预测结果或者生成序列。
在上述步骤中,自注意力机制起到的作用主要是将序列中的每个位置都视为 Query、Key 和 Value,并利用它们之间的相互作用来计算每个位置的注意力分数,然后根据这些分数对序列中的不同位置进行加权平均,从而获得每个位置的新表示。通过这种方式,模型能够在不同的维度上关注序列中不同位置的信息,从而更好地捕捉序列的长距离依赖关系,并生成具有更丰富信息的表示,从而为后续的任务提供更好的输入。这也使得自注意力机制成为了处理序列数据的一种强大工具,在自然语言处理任务中被广泛应用。
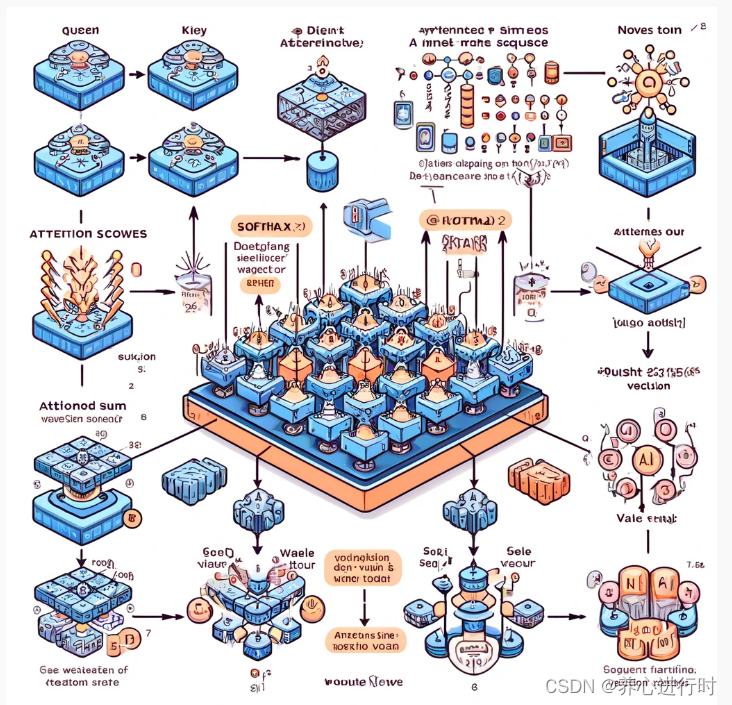
虽然自注意力机制起源于人工智能,但其核心思想“动态分配注意力资源以优化信息处理”对我们个人的精力管理也有着深刻的启示,尤其是以下思路:
-
识别并优先处理关键任务:自注意力机制会自动聚焦于输入序列中最重要的部分,我们在管理个人精力时,也需要学会识别日常工作中最关键、最有价值的任务,并优先分配精力给这些任务。也就是要将这种思维“判断哪些事项真正推动目标前进的,哪些只是次要细节”培养成自动的思维链接,才能将其应用到我们生活的各个方面,从而高效利用我们有限的精力资源。
-
灵活调整注意力焦点:自注意力机制的灵活性在于能够根据不同上下文动态调整注意力分配。我们在管理个人精力时,也需要根据当前的内外部环境、身体状况和情绪状态灵活调整精力分配的重点。比如,我们可以在精力充沛的早晨专注于那些需要高度集中的工作,而在下午疲劳时则可以选择做些较为轻松的任务或者安排一段休息的时间等。
-
避免精力分散,集中处理:自注意力机制通过集中注意力于少数关键元素,提高了信息处理的效率。个人精力管理也可以遵循类似的原理,尽量减少多任务并行处理,集中精力逐一攻克手头的任务。(虽然多任务并行看上去很高效,但因其会让我们的心思更加散乱,而不是如正念或心流那样,让我们只聚焦于当下做的一件事,所以不太适合个人的精力管理)
-
周期性回顾与调整:自注意力机制在模型训练过程中会不断学习和调整注意力权重,个人精力管理也需要定期回顾自己的精力分配策略,根据实际效果进行调整优先级和资源分配。比如,定期检查自己的工作习惯、休闲生活,学习生活等,看看我们是否有效利用了时间或精力来学习、工作和放松,是否需要调整任务时间表、舍弃一些不是很重要的事情从而让自己更有精力聚焦在更重要的事情上等等。
-
利用外部信号辅助决策:自注意力机制会利用输入数据中的特征来指导注意力的分配。个人也可以借助外部工具或指标(如日程表、闹钟、健康监测设备提供的数据)来帮助自己更好地管理精力,比如定时提醒我们切换任务,注意劳逸结合或者是可视化已经完成的任务和时间分配,从而总结并调整后续的时间安排等等。
总的来说,自注意力机制的精髓在于智能、高效地分配有限的处理资源。如果将其思路应用于个人的精力管理上,则意味着我们要刻意培养我们对自身状态的敏锐感知,更科学、灵活地为不同的任务分配精力权重或分数,确保在有限的精力资源下,实现个人效能的最大化!
这篇关于算法人生(20):从“自注意力机制”看“个人精力怎么管”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







