本文主要是介绍Go实战 | 使用Go-Fiber采用分层架构搭建一个简单的Web服务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
📢博客主页:程序源⠀-CSDN博客
📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!
一、环境准备、示例介绍
Go语言安装,GoLand编辑器
这个示例实现了一个简单的待办事项(todo)管理系统。
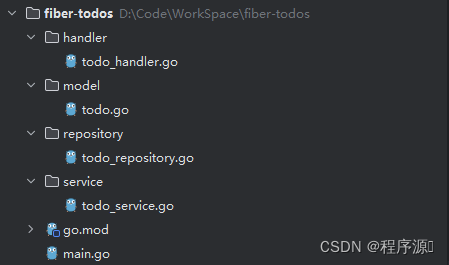
目录详情
新建一个fiber-todos文件夹,在目录中新建如下文件
二、代码编写
采用分层架构搭建一个简单的Web服务有助于提高代码的可维护性和可扩展性。我们将把应用程序分为以下几个层次:
-
Handler(处理器层):处理HTTP请求。
-
Service(服务层):包含业务逻辑。
-
Repository(仓库层):处理数据访问逻辑。
-
Model(模型层):定义数据结构。
2.1 Handler(处理器层)
package handlerimport ("fiber-todos/model""fiber-todos/service""github.com/gofiber/fiber/v2"
)type TodoHandler struct {service service.TodoService
}func NewTodoHandler(service service.TodoService) *TodoHandler {return &TodoHandler{service: service}
}func (h *TodoHandler) GetTodos(c *fiber.Ctx) error {todos := h.service.GetAllTodos()return c.JSON(todos)
}func (h *TodoHandler) GetTodoByID(c *fiber.Ctx) error {id := c.Params("id")todo, found := h.service.GetTodoByID(id)if !found {return c.Status(fiber.StatusNotFound).JSON(fiber.Map{"error": "Todo not found"})}return c.JSON(todo)
}func (h *TodoHandler) CreateTodo(c *fiber.Ctx) error {todo := new(model.Todo)if err := c.BodyParser(todo); err != nil {return c.Status(fiber.StatusBadRequest).JSON(fiber.Map{"error": "Cannot parse JSON"})}createdTodo := h.service.CreateTodo(*todo)return c.Status(fiber.StatusCreated).JSON(createdTodo)
}func (h *TodoHandler) UpdateTodo(c *fiber.Ctx) error {id := c.Params("id")todo := new(model.Todo)if err := c.BodyParser(todo); err != nil {return c.Status(fiber.StatusBadRequest).JSON(fiber.Map{"error": "Cannot parse JSON"})}updatedTodo, found := h.service.UpdateTodo(id, *todo)if !found {return c.Status(fiber.StatusNotFound).JSON(fiber.Map{"error": "Todo not found"})}return c.JSON(updatedTodo)
}func (h *TodoHandler) DeleteTodo(c *fiber.Ctx) error {id := c.Params("id")deleted := h.service.DeleteTodo(id)if !deleted {return c.Status(fiber.StatusNotFound).JSON(fiber.Map{"error": "Todo not found"})}return c.SendStatus(fiber.StatusNoContent)
}2.2 Service(服务层)
package serviceimport ("fiber-todos/model""fiber-todos/repository"
)type TodoService interface {GetAllTodos() []model.TodoGetTodoByID(id string) (model.Todo, bool)CreateTodo(todo model.Todo) model.TodoUpdateTodo(id string, todo model.Todo) (model.Todo, bool)DeleteTodo(id string) bool
}type todoService struct {repo repository.TodoRepository
}func NewTodoService(repo repository.TodoRepository) TodoService {return &todoService{repo: repo}
}func (s *todoService) GetAllTodos() []model.Todo {return s.repo.GetAll()
}func (s *todoService) GetTodoByID(id string) (model.Todo, bool) {return s.repo.GetByID(id)
}func (s *todoService) CreateTodo(todo model.Todo) model.Todo {return s.repo.Create(todo)
}func (s *todoService) UpdateTodo(id string, todo model.Todo) (model.Todo, bool) {return s.repo.Update(id, todo)
}func (s *todoService) DeleteTodo(id string) bool {return s.repo.Delete(id)
}2.3 Repository(仓库层)
package repositoryimport ("fiber-todos/model""github.com/google/uuid"
)type TodoRepository interface {GetAll() []model.TodoGetByID(id string) (model.Todo, bool)Create(todo model.Todo) model.TodoUpdate(id string, todo model.Todo) (model.Todo, bool)Delete(id string) bool
}type InMemoryTodoRepository struct {todos []model.Todo
}func NewInMemoryTodoRepository() TodoRepository {return &InMemoryTodoRepository{todos: []model.Todo{},}
}func (r *InMemoryTodoRepository) GetAll() []model.Todo {return r.todos
}func (r *InMemoryTodoRepository) GetByID(id string) (model.Todo, bool) {for _, todo := range r.todos {if todo.ID == id {return todo, true}}return model.Todo{}, false
}func (r *InMemoryTodoRepository) Create(todo model.Todo) model.Todo {todo.ID = uuid.New().String()r.todos = append(r.todos, todo)return todo
}func (r *InMemoryTodoRepository) Update(id string, updatedTodo model.Todo) (model.Todo, bool) {for i, todo := range r.todos {if todo.ID == id {r.todos[i].Title = updatedTodo.Titler.todos[i].Done = updatedTodo.Donereturn r.todos[i], true}}return model.Todo{}, false
}func (r *InMemoryTodoRepository) Delete(id string) bool {for i, todo := range r.todos {if todo.ID == id {r.todos = append(r.todos[:i], r.todos[i+1:]...)return true}}return false
}2.4 Model(模型层)
package modeltype Todo struct {ID string `json:"id"`Title string `json:"title"`Done bool `json:"done"`
}
三、运行结果
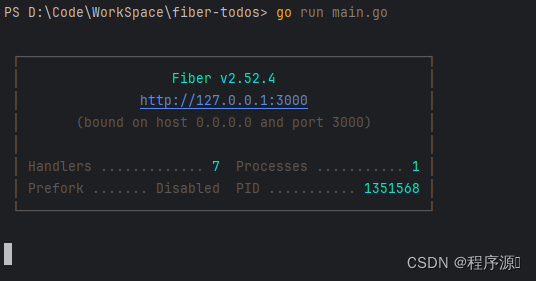
在终端中打开项目,运行项目
go run main.go
再打开一个新的终端
这里使用
Invoke-WebRequest发送 POST 请求
$headers = @{"Content-Type" = "application/json"
}$body = @{"title" = "Learn Fiber""done" = $false
} | ConvertTo-JsonInvoke-WebRequest -Uri "http://localhost:3000/todos" -Method POST -Headers $headers -Body $body
解析:
Headers 字典创建:
$headers = @{"Content-Type" = "application/json"
}Body 对象创建:
$body = @{"title" = "Learn Fiber""done" = $false
} | ConvertTo-Json
发送 POST 请求:
curl -X POST http://localhost:3000/todos -H "Content-Type: application/json" -d '{"title": "Learn Fiber", "done": false}'
响应结果:
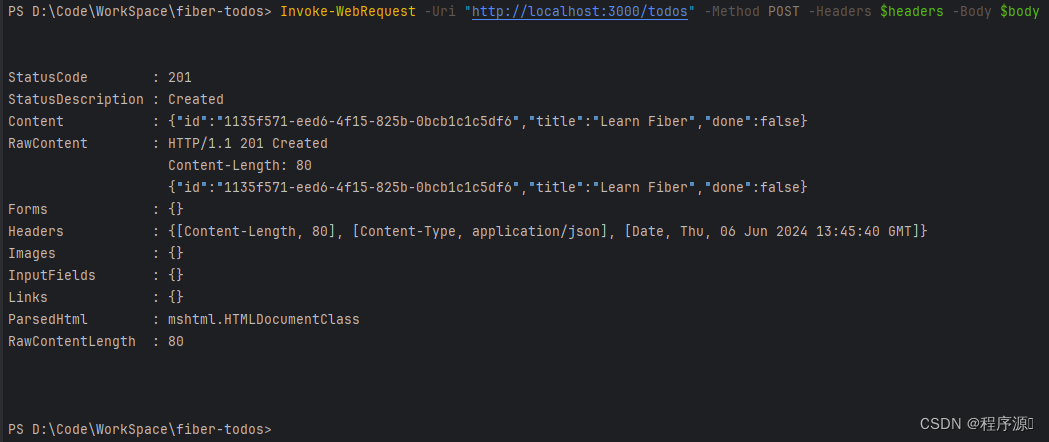
成功发送了 POST 请求
这篇关于Go实战 | 使用Go-Fiber采用分层架构搭建一个简单的Web服务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






