本文主要是介绍R语言BIOMOD2 及机器学习方法的物种分布模拟与案例分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BIOMOD2是一个R软件包,用于构建和评估物种分布模型(SDMs)。它集成了多种统计和机器学习方法,如GLM、GAM、SVM等,允许用户预测和分析物种在不同环境条件下的地理分布。通过这种方式,BIOMOD帮助研究者评估气候变化、生境丧失等因素对生物多样性的潜在影响。
基于R语言BIOMOD2 及机器学习方法的物种分布模拟与案例分析 (qq.com)
【亮点】:
1、理论与实践结合:设计旨在平衡理论学习和实际操作,不仅提供了物种分布模型的深入理论知识,还包括大量的实际应用环节,如使用BIOMOD软件包进行实际数据分析和模型建构。
2、多模型学习方法:覆盖多种模型和技术,包括广义线性模型、广义加性模型、机器学习方法等,学员能够了解和掌握多种建模技术,增强模型选择和应用的灵活性。
3、专题深入讨论:针对当前生态和环境问题,如气候变化和生物入侵,课程包括专题讨论和案例研究,帮助学员理解物种分布模型在解决这些全球问题中的实际应用和潜力。
4、跨学科技能培养:不仅限于生态模型的构建,还包括数据科学技能的培养,如数据预处理、统计分析和结果可视化,这些技能在当今数据驱动的科研和政策制定中极为重要。
【目标】:
1、理解物种分布模型的基本原理:理解物种分布模型(SDMs)的理论基础,包括模型的种类、用途以及在生态研究和环境管理中的应用。
2、掌握BIOMOD2软件包的使用:在R环境中有效地使用BIOMOD2软件包,包括数据准备、模型构建、模型评估和结果解释。
3、提高数据分析和处理能力:获取、处理和分析环境与物种数据的能力,包括数据清洗、变量选择和模型优化。
4、应用模型解决实际问题:通过案例学习和实际操作,将所学知识应用于解决真实世界的问题,如生物多样性保护、气候变化影响评估和入侵物种管理。
第一章、引入和理论基础
介绍:目标、流程和期望成果。
生态模型基础:介绍生态模型的基本概念和物种分布模型(SDMs)的重要性。
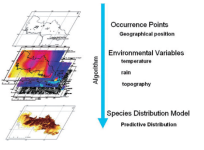
biomod2简介:探讨biomod2的历史、发展和主要功能。
R语言重点工具入门:数据输入与输出、科学计算、地理数据分析、数据可视化等功能。
第二章、数据获取与预处理
常见地球科学数据讲解(数据特点与获取途径):
(1)物种分布数据;
(2)环境变量(站点数据、遥感数据)。
基于R语言的数据预处理:
(1)数据提取:根据需求批量提取相关数据;
(2)数据清洗:数据清洗的原则与方法;
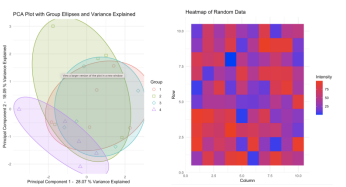
(3)特征变量选择:通过相关性分析、主成分分析(PCA)等方法选择具有代表性的特征变量,提高模型效率。
第三章、模型的建立与评估
机器学习概述与R语言实践
(1)机器学习原理;
(2)常见机器学习算法与流程
基于单一机器学习算法的物种分布特征模拟(以最大熵算法为例)。

biomod2程序包介绍与使用:原理、构成
实际操作:构建第一个物种分布模型,包括选择模型类型和调整参数。
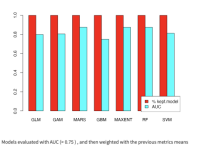
模型评估方法:通过ROC曲线、AUC值等方法评估模型的有效性和准确性。
第四章、模型优化与多模型集成
典型算法参数优化:对随机森林、最大熵等算法进行参数优化,提高模型性能。
集成方法:结合多个模型提高预测结果的稳定性和准确性。
物种分布特征预测:基于单一模型与集成模型预测物种未来分布特征。
实战演练:参与者使用自己的数据或示例数据集,尝试实现多模型集成。
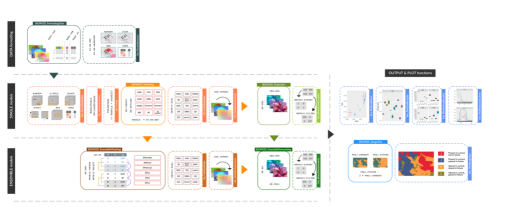
第五章、结果分析和案例研究
结果分析:物种分布特征、环境变量与物种分布关系、未来分布特征预测。
科学制图:栅格图、柱状图、降维结果图等。
案例研究:分析物种分布案例,如何应用学到的技能和知识。
这篇关于R语言BIOMOD2 及机器学习方法的物种分布模拟与案例分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




