本文主要是介绍PLA Percentron Learning Algorithm #台大 Machine learning #,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Percentron Learning Algorithm
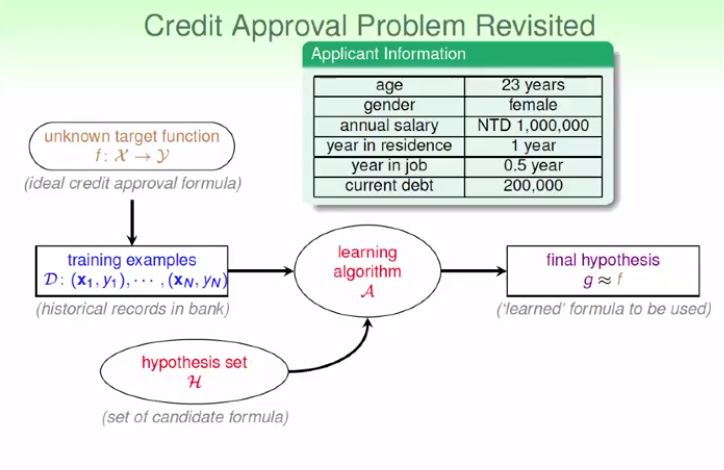



于垃圾邮件的鉴别
这里肯定会预先给定一个关于垃圾邮件词汇的集合(keyword set),然后根据四组不通过的输入样本里面垃圾词汇出现的频率来鉴别是否是垃圾邮件.系统输出+1判定为垃圾邮件,否则不是.这里答案是第二组.

拿二维数据来做例子.我们要选取一条线来划分红色的叉叉,和蓝色的圈圈样本点(线性划分).怎么做呢?这里的困难之处就在于,其实可行的解可能存在无数条直线可以划分这些样本点.很难全部求解,或许实际生活中并不需要全部求解.于是,我们可以先随意的去初始一个假设解,然后不断的去修正这个一开始可能不是正确的解.使之越来越接近正确可行的一个解.
我们一开始把 w 权重系数置为0,然后去修正这个权重系数.怎么修正呢?

PLA的重要性质:有错才更新!
IF
如果实际输出
将新的权重设置为 wt+1=wt+yn(t)∗xn(t) .
即,如果输出 y(n) 是个正数,期望输出y和x向量方向一致,试图减小夹角.如果输出 y(n) 是个负数,期望输出y和x向量方向恰好相反,试图减增大夹角.
ELSE
这里如果实际输出和期望输出无差异,则不需要进行修正了.
关于线性可划分性的探讨:
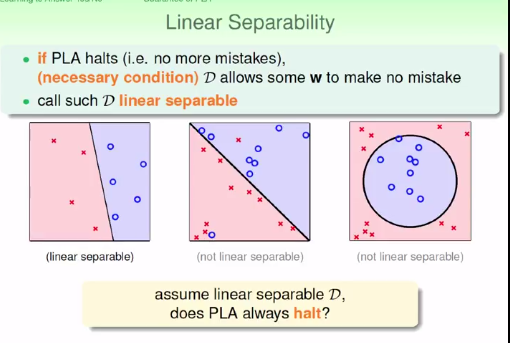
其实关于这一步夹角越来越小的数学推到我也不是很清楚.

Funtime

下面是PLA的一个demo代码:
这个demo 来自link,之前的源码在我的配置环境下不能跑,我有稍作改动.
https://datasciencelab.wordpress.com/2014/01/10/machine-learning-classics-the-perceptron/
"""
Programmer : EOF
file : pla.py
date : 2015.02.22Code description:This program is coded for Perceptron Learning Algorithm."""
import numpy as np
import matplotlib.pyplot as plt
import random
import os, subprocessclass Perceptron:def __init__(self, N):# random linearly seperated dataxA, yA, xB, yB = [random.uniform(-1, 1) for i in range(4)]self.V = np.array([xB*yA - xA*yB, yB - yA, xA - xB])self.X = self.generate_points(N)def generate_points(self, N):X = []for i in range(N):x1, x2 = [random.uniform(-1, 1) for i in range(2)]x = np.array([1, x1, x2])s = int(np.sign(self.V.T.dot(x)))X.append((x, s))return Xdef plot(self, mispts = None, vec = None, save = False):fig = plt.figure(figsize=(5,5))plt.xlim(-1, 1)plt.ylim(-1, 1)V = self.Va, b = -V[1]/V[2], -V[0]/V[2]l = np.linspace(-1, 1)plt.plot(l, a*l + b, 'k-')cols = {1: 'r', -1: 'b'}for x,s in self.X:plt.plot(x[1], x[2], cols[s] + 'o')if mispts:for x, s in mispts:plt.plot(x[1], x[2], cols[s] + '.')if vec != None:aa, bb = -vec[1]/vec[2], -vec[0]/vec[2]plt.plot(l, aa*l + bb, 'g-', lw = 2)if save:if not mispts:plt.title('N = %s' % (str(len(self.X))))else:plt.title('N = %s with % test points' \% (str(len(self.X)), str(len(mispts))))plt.savefig('p_N %s ' % (str(len(self.X))), \dpi = 200, bbox_inches = 'tight')plt.show()def classification_error(self, vec, pts = None):# Error defined as fraction of misclassified pointsif not pts:pts = self.XM = len(pts)n_mispts = 0for x, s in pts:if int(np.sign(vec.T.dot(x))) != s :n_mispts += 1error = n_mispts / float(M)return errordef choose_miscl_point(self, vec):# Choose a random point among the misclassifiedpts = self.Xmispts = []for x, s in pts:if int(np.sign(vec.T.dot(x))) !=s :mispts.append((x, s))return mispts[random.randrange(0, len(mispts))]def pla(self, save = False):# Initialize the weights to zerosw = np.zeros(3)X, N = self.X, len(self.X)it = 0# Iterate until all points are correctly classifiedwhile self.classification_error(w) != 0:it += 1# pick random misclassified pointx, s = self.choose_miscl_point(w)# update weightsw += s*xif save:self.plot(vec = w)plt.title('N = %s, Iteration %s\n' \% (str(N), str(it)))plt.savefig('p_N % s_it %s' % (str(N), str(it)), \dpi = 200, bbox_inches = 'tight')self.w = wdef check_error(self, M, vec):check_pts = self.generate_points(M)return self.classification_error(vec, pts = check_pts)#--------for testing-------------------------
p = Perceptron(20)
#p.plot(p.generate_points(20),p.w, save=True)
p.plot()这篇关于PLA Percentron Learning Algorithm #台大 Machine learning #的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








