本文主要是介绍一文看懂如何增强LLM的长文本处理能力(包含代码和原理解析),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本篇博客是LLM中的RoPE位置编码代码解析与RoPE的性质分析(一)的续集,若对RoPE的性质不了解(比如远程衰减性、周期性与频率特性),建议先看LLM中的RoPE位置编码代码解析与RoPE的性质分析(一)
如何增强使用RoPE的LLM的处理长文本的能力
我们继续定义模型的训练长度为 L t r a i n L_{train} Ltrain,模型的测试长度为 L t e s t L_{test} Ltest, L t e s t > L t r a i n L_{test} > L_{train} Ltest>Ltrain,定义 s = L t e s t L t r a i n s={L_{test} \over L_{train}} s=LtrainLtest为内插因子。
回忆一下RoPE的实现:
[ q 0 q 1 q 2 q 3 . . q d − 2 q d − 1 ] ∗ [ c o s m θ 0 c o s m θ 0 c o s m θ 1 c o s m θ 1 . . c o s m θ d / 2 − 1 c o s m θ d / 2 − 1 ] + [ − q 1 q 0 − q 3 q 2 . . − q d − 1 q d − 2 ] ∗ [ s i n m θ 0 s i n m θ 0 s i n m θ 1 s i n m θ 1 . . s i n m θ d / 2 − 1 s i n m θ d / 2 − 1 ] ( 1 ) \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 q_0\\ %第一行元素 q_1\\ %第二行元素 q_2 \\ q_3 \\ .. \\ q_{d-2}\\ q_{d-1} \end{bmatrix} * \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 cosm\theta_0\\ %第一行元素 cosm\theta_0\\ %第二行元素 cosm\theta_1 \\ cosm\theta_1 \\ .. \\ cosm\theta_{d/2-1}\\ cosm\theta_{d/2-1} \end{bmatrix} + \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 -q_1\\ %第一行元素 q_0\\ %第二行元素 -q_3 \\ q_2 \\ .. \\ -q_{d-1}\\ q_{d-2} \end{bmatrix} * \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 sinm\theta_0\\ %第一行元素 sin m\theta_0\\ %第二行元素 sinm\theta_1 \\ sinm\theta_1 \\ .. \\ sinm\theta_{d/2-1}\\ sinm\theta_{d/2-1} \end{bmatrix} \ \ \ \ \ \ \ \ \ \ \ \ (1) q0q1q2q3..qd−2qd−1 ∗ cosmθ0cosmθ0cosmθ1cosmθ1..cosmθd/2−1cosmθd/2−1 + −q1q0−q3q2..−qd−1qd−2 ∗ sinmθ0sinmθ0sinmθ1sinmθ1..sinmθd/2−1sinmθd/2−1 (1)
在公式(1)中, m m m表示query向量的位置,同时cos函数与sin函数的输入均是 m θ i m\theta_{i} mθi, i i i表示分量。
在RoPE中, m θ i m\theta_{i} mθi的定义是:
f ( m , θ i ) = m θ i = m b a s e 2 i / d ( 2 ) f(m, \theta_{i}) = m\theta_{i} = {m \over base^{2i/d}} \ \ \ \ \ \ \ \ \ \ \ \ \ \ (2) f(m,θi)=mθi=base2i/dm (2)
对于某个模型来说, d d d是固定的。
位置编码内插是早期对基于RoPE的LLM进行长文本能力扩展的方法。
PI(位置编码内插,Position Interpolation)
EXTENDING CONTEXT WINDOW OF LARGE LANGUAGE MODELS VIA POSITION INTERPOLATION
位置编码内插是指,将超过 L t r a i n L_{train} Ltrain的文本的position_id缩放到 [ 0 , L t r a i n − 1 ] [0, L_{train}-1] [0,Ltrain−1]。下图的第二行展示了位置编码内插后的效果,可以看到PI之后,原本两个点直接的距离变得更短了,压缩了局部token之间的分辨率,从而可能会造成局部失真。所以PI的方法需要一定量的额外训练,从而缓解失真问题(或者说是让模型适应比较拥挤的位置编码)。

transformers库对于PI的实现也是非常简单,可以看到,相比原始的RoPE,简单的将position_ids除了一个内插因子 s s s。有相关论文表明,即使PI+后期fintune,最多也只能外推8倍的长度,再高性能便开始下降了。
class LlamaLinearScalingRotaryEmbedding(LlamaRotaryEmbedding):"""LlamaRotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""def forward(self, x, position_ids):# difference to the original RoPE: a scaling factor is aplied to the position idsposition_ids = position_ids.float() / self.scaling_factorcos, sin = super().forward(x, position_ids)return cos, sin进一步理解位置编码高频外推与低频内插的含义
PI方法简单粗暴,但也存在很多缺点:
- 从position_id的角度理解,就是如上文所说的降低了模型的分辨率,造成局部失真。
- 从LLM中的RoPE位置编码代码解析与RoPE的性质分析(一)中的高频低频角度理解,PI方法没有考虑到高频分量和低频分量的特性,统一的对所有分量进行了内插。好的RoEP扩展方法应当是做到:高频外推、低频内插。
在LLM中的RoPE位置编码代码解析与RoPE的性质分析(一)的最后,简单介绍过高频外推与低频内插。
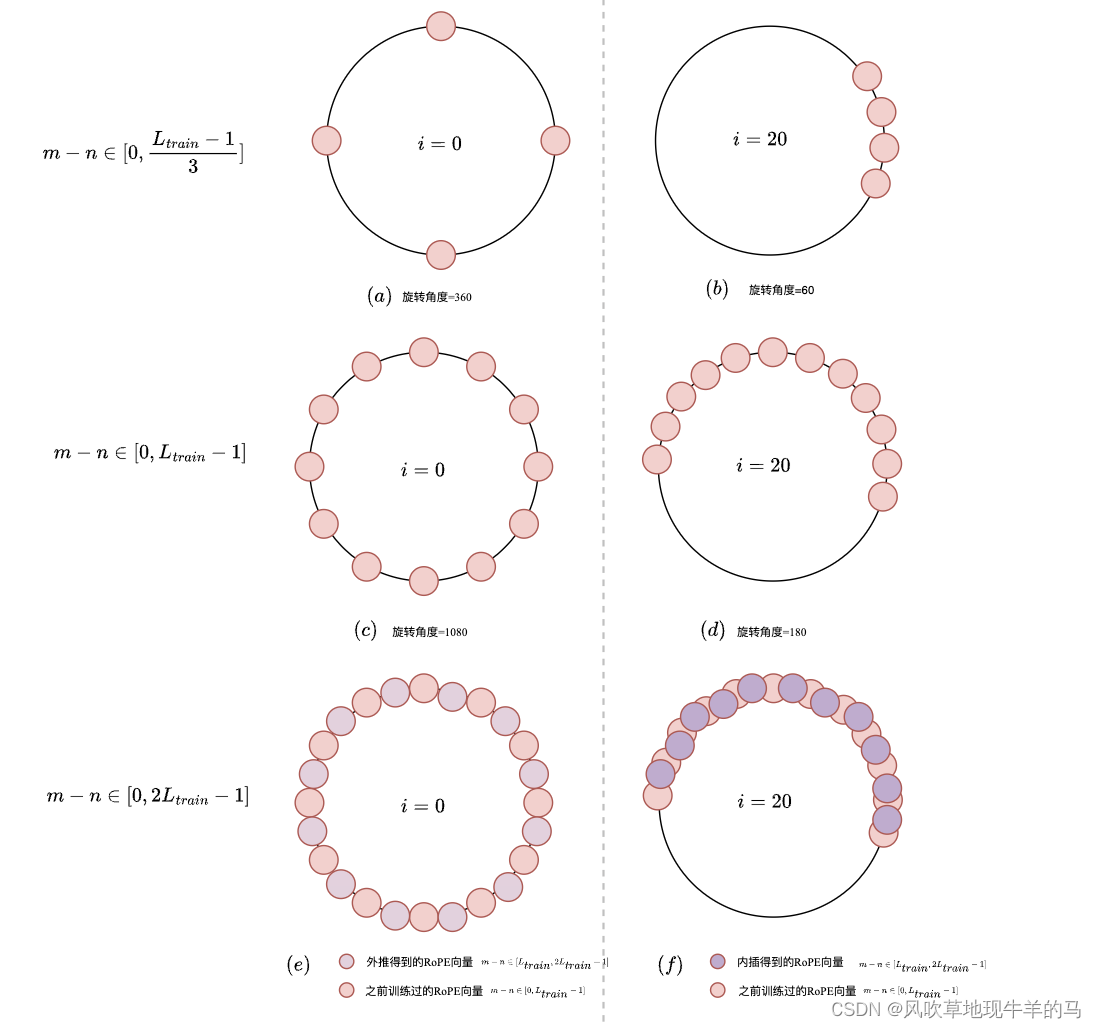
在上图中,我们说到第 i = 0 i=0 i=0组属于高频分量,此时整个圈上的每一段弧线都被训练过,所以可以直接外推(这里外推的含义就是当 m ∈ [ L t r a i n , 2 L t r a i n − 1 ] m \in [L_{train},2L_{train}-1] m∈[Ltrain,2Ltrain−1],不需要对 f ( m , θ 0 ) f(m,\theta_{0}) f(m,θ0)做任何改动,可以直接扩展)。第 i = 20 i=20 i=20组属于低频分量,需要内插(这里内插的含义就是当 m ∈ [ L t r a i n , 2 L t r a i n − 1 ] m\in[L_{train},2L_{train}-1] m∈[Ltrain,2Ltrain−1]时,需要缩放到 [ 0 , L t r a i n − 1 ] [0, L_{train}-1] [0,Ltrain−1],此时 f f f函数变为 f ( m / s , θ 20 ) , 这里缩放因子 s = 2 f(m/s, \theta_{20}),这里缩放因子s=2 f(m/s,θ20),这里缩放因子s=2)。
也就是说,好的RoPE扩展方法,应该是当 m ∈ [ L t r a i n , 2 L t r a i n − 1 ] m \in [L_{train},2L_{train}-1] m∈[Ltrain,2Ltrain−1]时:
f ( m , θ i ) = { f ( m , θ i ) , i ∈ ϕ h i g h f ( m / s , θ i ) , i ∈ ϕ l o w ( 3 ) f(m, \theta_{i})= \left\{ \begin{aligned} & f(m, \theta_{i}) \ \ \ \ \ \ \ \ , i \in \phi_{high} \\ & f(m/s, \theta_{i}) \ \ \ \ \ \ \ \ , i \in \phi_{low} \\ \end{aligned} \ \ \ \ \ \ \ \ \ (3) \right. f(m,θi)={f(m,θi) ,i∈ϕhighf(m/s,θi) ,i∈ϕlow (3)
其中, ϕ h i g h \phi_{high} ϕhigh属于高频分量集合, ϕ l o w \phi_{low} ϕlow属于低频分量集合。可见PI的方法对低频分量做到了内插,但没有对高频分量做到外推。
那么对于低频分量来说,将 m / s m/s m/s,本质上其实还是扩大了 b a s e base base参数,我们令
m b a s e ^ 2 i / d = m / s b a s e 2 i / d ( 4 ) {m \over \hat{base}^{2i/d}} = {m /s \over base^{2i/d}} \ \ \ \ \ \ \ \ \ \ \ \ \ (4) base^2i/dm=base2i/dm/s (4)
解得, b a s e ^ = s d / 2 i b a s e \hat{base}=s^{d/2i}base base^=sd/2ibase,也就是将base参数扩大了 s d / 2 i s^{d/2i} sd/2i倍。
ABF(增加base参数,Adjusted Base Frequency)
Effective Long-Context Scaling of Foundation Models
如何理解简单粗暴的修改base参数就可以增加模型的外推能力?
在实验中,我们发现,LLaMA3的base=10000,只能从8k直接外推到9k左右,而Qwen1.5的base=1000000,可以从32k直接外推到52k。
-
角度1:从远程衰减性的角度
LLM中的RoPE位置编码代码解析与RoPE的性质分析(一)中提到,RoPE具有远程衰减性,当base参数较小时(比如10000),这时对于长文本来说,远程的token注意力就更减弱了,因此这篇文章中提出,可以直接将base参数从10000 增加到 500000,这样可以降低RoPE的远程衰减性。 -
角度2:从容量的角度
如下图所示,左侧的图表示,用3维4进制的数,最多可以表示 [ 0 − 63 ] [0-63] [0−63],我们用 f ( b a s e = 4 , d i m = 3 ) f(base=4,dim=3) f(base=4,dim=3)表示。
假设现在需要表示 [ 0 , 124 ] [0, 124] [0,124],应该如何做?当然可以继续按照4进制,将维数由3维扩展为4维。也可以有另外的方法,将进制改为5进制,这样可以在不增加维数的情况下,增加 f f f的表示容量。 f ( b a s e = 4 , d i m = 3 ) f(base=4,dim=3) f(base=4,dim=3)的容量是64,而 f ( b a s e = 5 , d i m = 3 ) f(base=5,dim=3) f(base=5,dim=3)的容量是125。

对于RoPE来说,增加base参数,相当于增加了RoPE的表示容量,所以在长度外推的时候,大的base参数,外推能力要好于小base参数的外推能力,并且,增加base参数,并不会改变相邻两个点的距离,所以不会有PI方法的局部失真问题,如论文中的图所示。

NTK-RoPE (NTK-aware)
https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/
ABF的方法明显是对模型的长文本处理是有效果的,但是并没有给出一个具体计算扩大原本base的公式,NTK-RoPE给出了扩大base参数的公式:
f ( m , θ i ) = m ( b a s e ∗ s d / ( d − 2 ) ) 2 i / d ( 5 ) f(m, \theta_{i}) = {m \over (base*s^{d/(d-2)}) ^{2i/d}} \ \ \ \ \ \ \ \ \ \ \ \ (5) f(m,θi)=(base∗sd/(d−2))2i/dm (5)
相比于公式(2),base参数被扩大了 s d / d − 2 s^{d/d-2} sd/d−2倍。那么base参数为什么要扩大这么多倍?NTK-RoPE的作者提出,在推导的时候,先是保证了让最低频( i = d / 2 − 1 i=d/2-1 i=d/2−1)执行完整的内插。也就是有:
( b a s e ∗ k ) − 2 i / d = s ∗ b a s e − 2 i / d (base*k)^{-2i/d} = s*base^{-2i/d} (base∗k)−2i/d=s∗base−2i/d
解得 k = s d / ( d − 2 ) = L t e s t L t r a i n d / ( d − 2 ) k = s^{d/(d-2)} = {L_{test} \over L_{train}}^{d/(d-2)} k=sd/(d−2)=LtrainLtestd/(d−2)。在这种情况下,虽然NTK-RoPE对于每一个分量,都将base参数扩大了 s d / d − 2 s^{d/d-2} sd/d−2倍,但是保证了最高频( i = 0 时, f ( m , θ 0 ) 结果不变 i=0时,f(m, \theta_{0})结果不变 i=0时,f(m,θ0)结果不变),从而实现了最高频外推(不插值),最低频( i = d / / 2 − 1 i=d//2-1 i=d//2−1)插值,从而在免训练的情况下,效果超过了PI。
但是在微调情况下,PI的效果要好于NTK-RoPE,原因在于NTK-RoPE可能会出现越界值,缓解的办法是,调高 s s s
代码实现如下:
class LlamaDynamicNTKScalingRotaryEmbedding(LlamaRotaryEmbedding):"""LlamaRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""def forward(self, x, seq_len):# difference to the original RoPE: inv_freq is recomputed when the sequence length > original lengthposition_ids = torch.arange(seq_len, dtype=torch.int64).unsqueeze(0).to(x.device)# seq_len = torch.max(position_ids) + 1if seq_len > self.max_position_embeddings:base = self.base * ((self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)) ** (self.dim / (self.dim - 2))inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(x.device) / self.dim))self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: this may break with compilationcos, sin = super().forward(x, position_ids)return cos, sin
目前所有的非Dynamic的长度扩展方法均会对 L t r a i n L_{train} Ltrain长度内的文本性能造成一定下降。为了避免外推的时候,影响 L t r a i n L_{train} Ltrain长度内的文本性能表现,上面的代码使用了Dynamic的方法。
Yarn (NTK-by-parts)
YaRN: Efficient Context Window Extension of Large Language Models
这篇论文写的很好,建议阅读。
NTK-RoPE的方法只保证了最高频分量外推和最低频分量内插。根据公式(3),应该是对高频分量集合 ϕ h i g h \phi_{high} ϕhigh外推,对低频分量集合 ϕ l o w \phi_{low} ϕlow内插。那么如何得到 ϕ h i g h \phi_{high} ϕhigh和 ϕ l o w \phi_{low} ϕlow?
这里需要额外引入一个概念,波长 λ \lambda λ,我们定义RoPE embedding的第 i i i组分量的波长计算公式:
λ i = 2 π θ i = 2 π b a s e 2 i / d ( 6 ) \lambda_{i} = {2\pi \over \theta_{i}} =2\pi base^{2i/d} \ \ \ \ \ \ \ \ (6) λi=θi2π=2πbase2i/d (6)
公式(6)描述了RoPE的第 i i i组分量旋转360度(一圈)所走过的长度。Yarn论文的作者还发现,对于某些低频分量,其波长 λ i > L t r a i n \lambda_{i}>L_{train} λi>Ltrain,也就是如我们前面所讲的,在整个训练过程中,没有转够一圈,整个圈上只有一段弧线被训练过。对于高频分量来说,可能已经转了很多圈。所以我们还可以定义一个在 L t r a i n L_{train} Ltrain长度上的圈数:
r i = L t r a i n λ i r_{i} = {L_{train} \over \lambda_{i} } ri=λiLtrain
那么,我们可以定义两个超参数, β f a s t \beta_{fast} βfast与 β s l o w \beta_{slow} βslow,分别表示筛选高频分量的阈值与筛选低频分量的阈值:
- 若 r i > β f a s t r_{i} > \beta_{fast} ri>βfast,那么认为是高频分量,不需要内插。
- 若 r i < β s l o w r_{i} < \beta_{slow} ri<βslow,那么认为是低频分量,需要内插。
- 若介于二者之间,则内插和外推均可。
若用公式来表达,那就是:
f ( m , θ i ) = m / s b a s e 2 i / d ( 1 − α ( r i ) ) + m b a s e 2 i / d α ( r i ) ( 7 ) f(m, \theta_{i}) = {m/s \over base^{2i/d}} (1-\alpha(r_{i})) +{m \over base^{2i/d} } \alpha(r_{i}) \ \ \ \ \ \ \ \ \ \ (7) f(m,θi)=base2i/dm/s(1−α(ri))+base2i/dmα(ri) (7)
其中:
α ( r i ) = { 1 , r i > β f a s t 0 , r i < β s l o w r i − β s l o w β f a s t − β s l o w , β s l o w < = r i < = β f a s t ( 8 ) \alpha(r_{i})= \left\{ \begin{aligned} & 1 \ \ \ \ \ \ \ \ , r_{i} > \beta_{fast} \\ & 0 \ \ \ \ \ \ \ \ , r_{i} < \beta_{slow} \\ & {r_{i}-\beta_{slow} \over \beta_{fast}-\beta_{slow}} \ \ \ \ \ \ , \beta_{slow}<= r_{i} <= \beta_{fast}\\ \end{aligned} \ \ \ \ \ \ \ \ \ (8) \right. α(ri)=⎩ ⎨ ⎧1 ,ri>βfast0 ,ri<βslowβfast−βslowri−βslow ,βslow<=ri<=βfast (8)
- 截止目前,其实都是NTK-by-parts的内容。
- NTK-by-parts在微调和非微调的场景下,均取得了最好的性能。
- 在论文中,作者发现对于LLaMA2来说, β f a s t = 32 , β s l o w = 1 \beta_{fast}=32, \beta_{slow}=1 βfast=32,βslow=1时,可以有最好的性能表现。
下图展示了LLaMA2-7B的不同分量对应的旋转圈数的变化曲线, β f a s t = 32 , β s l o w = 1 , i ∈ [ 0 , 2048 ) \beta_{fast}=32, \beta_{slow}=1, i \in [0, 2048) βfast=32,βslow=1,i∈[0,2048)。
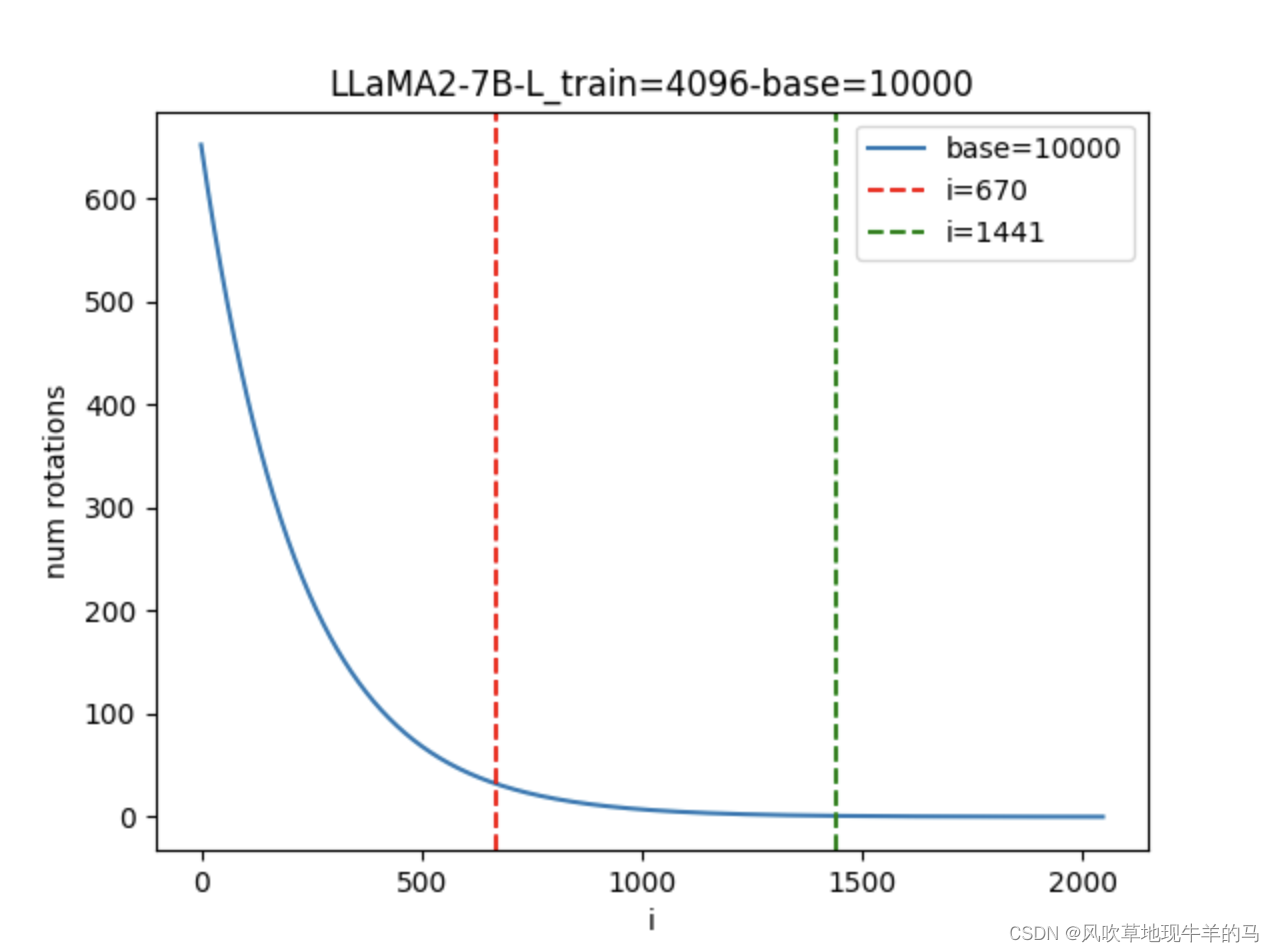
- i = 670 i=670 i=670左侧的区域均直接外推,不进行插值
- i = 1441 i=1441 i=1441右侧的区域进行内插
- 中间的区域外推和内插混合。
制图的代码如下
import torch
import math
import matplotlib.pyplot as pltdef find_correction_dim(num_rotations, dim, base=10000, max_position_embeddings=2048):return (dim * math.log(max_position_embeddings/(num_rotations * 2 * math.pi)))/(2 * math.log(base))# Find dim range bounds based on rotations
def find_correction_range(beta_fast, beta_slow, dim, base=10000, max_position_embeddings=2048):low = math.floor(find_correction_dim(beta_fast, dim, base, max_position_embeddings))high = math.ceil(find_correction_dim(beta_slow, dim, base, max_position_embeddings))return max(low, 0), min(high, dim-1) # Clamp values just in casedim = 4096
max_pos_embeddings = 4096
base = 10000
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2) / dim))# 波长
lambda_ = 2 * math.pi / inv_freq
# 旋转圈数
num_ros = max_pos_embeddings / lambda_x = torch.arange(dim//2).numpy()
y = num_ros.numpy()low_dim, high_dim = find_correction_range(beta_fast=32, beta_slow=1, dim=dim, base=base, max_position_embeddings=max_pos_embeddings)
print(low_dim)
print(high_dim)
print(num_ros[high_dim], num_ros[low_dim])plt.title(f'LLaMA2-7B-L_train={max_pos_embeddings}-base={base}')
plt.plot(x, y, label=f"base={base}")
plt.axvline(x=low_dim, color="r", linestyle='--', label=f'i={low_dim}')
plt.axvline(x=high_dim, color="g", linestyle='--', label=f'i={high_dim}')
plt.legend()
plt.xlabel('i')
plt.ylabel('num rotations')
plt.show()
接下来应该是Yarn的版本了。Yarn是在NTK-by-parts的基础上,在计算attention score的时候,进行了一个温度系数的惩罚。
s o f t m a x ( q m k n T t d ) softmax({q_{m}k_{n}^{T} \over t \sqrt{d}}) softmax(tdqmknT)
由于RoPE的特性,直接将 q m 与 k n q_{m}与k_{n} qm与kn除以 1 / t \sqrt{1/t} 1/t,可以达到同样的效果。那么 1 / t \sqrt{1/t} 1/t如何确定?Yarn论文作者取值为:
1 / t = 0.1 l n ( s ) + 1 \sqrt{1/t} = 0.1ln(s) +1 1/t=0.1ln(s)+1
至此,Yarn的方法就结束了。
Yarn的代码如下:
class LlamaYaRNScaledRotaryEmbedding(LlamaRotaryEmbedding):def __init__(self,*args,original_max_position_embeddings=2048,extrapolation_factor=1,attn_factor=1,beta_fast=32,beta_slow=1,device=None,**kwargs):super().__init__(*args, **kwargs)self.original_max_position_embeddings = original_max_position_embeddingsself.extrapolation_factor = extrapolation_factorself.attn_factor = attn_factorself.beta_fast = beta_fastself.beta_slow = beta_slowself.yarn(device)def yarn(self, device):pos_freqs = self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim)inv_freq_extrapolation = 1.0 / pos_freqsinv_freq_interpolation = 1.0 / (self.scaling_factor * pos_freqs)# beta_fast和beta_slow表示分量旋转弧度的阈值,意思就是分量d的旋转弧度大于beat_fast,可以认为整个圈上的每个点都训练充分了,直接外推# 分量d的旋转弧度小于beta_slow,可以认为是整个圈上,只有一段弧线被训练过,需要内插low, high = find_correction_range(self.beta_fast, self.beta_slow, self.dim, self.base, self.original_max_position_embeddings)# 对应yarn论文的公式(13)inv_freq_mask = (1 - linear_ramp_mask(low, high, self.dim // 2).float().to(device)) * self.extrapolation_factor # Get n-d rotational scaling corrected for extrapolationinv_freq = inv_freq_interpolation * (1 - inv_freq_mask) + inv_freq_extrapolation * inv_freq_maskself.register_buffer("inv_freq", inv_freq)self.mscale = float(get_mscale(self.scaling_factor) * self.attn_factor) # Get n-d magnitude scaling corrected for interpolationdef forward(self, x, seq_len=None):# x: [bs, num_attention_heads, seq_len, head_size]# This `if` block is unlikely to be run after we build sin/cos in `__init__`. Keep the logic here just in case.cos, sin = super().forward(x, seq_len)cos = cos * self.mscalesin = sin * self.mscalereturn cos, sin
目前开源厂家如何增强LLM的长文本能力
Yi
根据Yi的技术报告,Yi的方案是:
- 训练4k 预训练模型 ,base=10000
- 修改base为10000000,max_position_embeddings=32768,在长文本(数据来源于书籍,长度可能是16k、32k)上少量训练,1-2Btoken就可收敛
- 外推到200k(不用任何长度扩展技术?根据目前开源的checkpoint是这样的。)
InternLM
根据InternLM的技术报告,InterLM的方案是:
- 训练4k 预训练模型,base=50000
- 修改base=1000000,max_position_embeddings=32768,混合50%的32k数据继续训练。
- 外推到200k
qwen1.5
qwen1.5没有技术报告,但是可以从config.json中看到,qwen1.5的max_position_embeddings=32768,达到了32k,base=1000000,方案可能和Yi、InternLM的类似。
在我们的测试下,qwen1.5直接外推可以到52k长度,yarn可以扩展到128k。
参考文献:
https://spaces.ac.cn/archives/9948/comment-page-2#comments
https://blog.csdn.net/PennyYu123/article/details/131717323
https://openreview.net/pdf?id=wHBfxhZu1u
这篇关于一文看懂如何增强LLM的长文本处理能力(包含代码和原理解析)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





