文本处理专题

基于Python打造一个全能文本处理工具
《基于Python打造一个全能文本处理工具》:本文主要介绍一个基于Python+Tkinter开发的全功能本地化文本处理工具,它不仅具备基础的格式转换功能,更集成了中文特色处理等实用功能,有需要的... 目录1. 概述:当文本处理遇上python图形界面2. 功能全景图:六大核心模块解析3.运行效果4. 相

Linux文本处理大纲
目录 一、正则表达式二、字符串截取命令(1)cut命令(2)printf命令(3)awk命令1、条件(pattern): 一般使用关系表达式作为条件2、动作(Action): 格式化输出 流程控制语句 三、字符串处理命令(1)排序命令sort(2)统计命令wc 一、正则表达式 正则表达式用来在文件中匹配符合条件的字符串, 正则是包含匹配。grep,awk,sed等命令可以支

NLP-文本处理:依存句法分析(主谓、动宾、动补...)【基于“分词后得到的词语列表A”+“A进行词性标注后得到的词性列表B”来进行依存句法分析】【使用成熟的第三方工具包】
句法分析(syntactic parsing)是自然语言处理中的关键技术之一,它是对输入的文本句子进行分析以得到句子的句法结构的处理过程。对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的重要一环,另一方面也为其它自然语言处理任务提供支持。例如句法驱动的统计机器翻译需要对源语言或目标语言(或者同时两种语言)进行句法分析。 第三方工具包: 哈工大LTP首页 哈工大LTP4 文档

NLP-文本处理:词性标注【使用成熟的第三方工具包:中文(哈工大LTP)、英文()】【对分词后得到的“词语列表”进行词性标注,词性标注的结果用于依存句法分析、语义角色标注】
词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等. 顾名思义, 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性. 举个栗子: 我爱自然语言处理==>我/rr, 爱/v, 自然语言/n, 处理/vnrr: 人称代词v: 动词n: 名词vn

Linux 系统入门:高级系统管理与文本处理
📚 Linux 系统入门:高级系统管理与文本处理 📑 目录 ⚙️ Linux 系统进程管理进阶📂 Linux 高效文本、文件处理命令📝 Shell 脚本入门 ⚙️ Linux 系统进程管理进阶 在 Linux 系统中,进程管理是保持系统高效运行的核心。通过深入理解进程的概念及其管理方式,能够更好地优化系统资源,提升性能。Linux 提供了多种工具和命令来监控和控制进程,从而

Linux 文本处理
1.正则表达式 Linux 正则表达式在文本处理和搜索过程中起着非常重要的作用。它可以用于匹配和查找符合特定模式的字符串,从而实现强大的文本处理功能。以下是一些常见的正则表达式作用: 1. 匹配字符串:正则表达式可以根据指定的模式匹配字符串。比如,可以使用正则表达式查找所有以特定字符开头或结尾的字符串。 2. 搜索和替换:正则表达式可以用于搜索

正则表达式:Visual Basic中的强大文本处理工具
正则表达式:Visual Basic中的强大文本处理工具 在软件开发中,文本处理是一项常见且关键的任务。正则表达式作为一种强大的文本模式匹配工具,能够用于执行各种复杂的字符串搜索、替换、验证等操作。Visual Basic(VB),作为一门流行的编程语言,提供了对正则表达式的支持。本文将详细介绍如何在Visual Basic中使用正则表达式,包括其基本概念、功能特点以及实际应用示例。 一、正则

【Rust光年纪】文本分析利器:探索Rust语言的多功能文本处理库
从情感分析到关键词提取:Rust语言文本分析库详解 前言 随着自然语言处理技术的不断发展,对各种文本数据进行分析和处理的需求也在不断增加。本文将介绍一些用于Rust语言的文本分析和处理库,包括情感分析、自然语言处理、中文转换、语言检查和关键词提取等方面的工具和资源。 欢迎订阅专栏:Rust光年纪 文章目录 从情感分析到关键词提取:Rust语言文本分析库详解前言1. senti

文本处理方向——WEB开发系列19
处理不同方向的文本是一个重要且复杂的任务,尤其是在多语言支持和跨文化网站设计中尤为重要。CSS(层叠样式表)为我们提供了强大的工具来处理不同的书写模式和布局方向。接下来我们来继续探讨关于 CSS 中的书写模式、块级布局和内联布局、方向、逻辑属性和逻辑值,以及如何使用这些工具来有效地管理文本的显示。 一、什么是书写模式 书写模式(writing modes)是指文本在页面上书写和排版的方

高效文本编辑器:轻松掌握内容,批量删除每隔一行带有分隔符的内容,助力文本处理更高效!
在信息爆炸的时代,文本处理已成为我们日常生活和工作中不可或缺的一部分。然而,面对海量的文本内容,如何高效地进行编辑和整理,成为了许多人面临的难题。今天,我要向大家推荐一款高效文本编辑器——首助编辑高手,它将助您轻松驾驭文本海洋,让内容处理更高效 首助编辑高手以其出色的文本批量操作功能,赢得了广大用户的青睐。在主页面,您可以清晰地看到各个板块栏,其中文本批量操作板块更是为您的编辑工作提供了强大

【推荐】Perl入门教程特点功能文本处理读取文件替换文本写入文件分割字符数据库处理环境准备安装(包含示咧)
本人详解 作者:王文峰,参加过 CSDN 2020年度博客之星,《Java王大师王天师》 公众号:JAVA开发王大师,专注于天道酬勤的 Java 开发问题中国国学、传统文化和代码爱好者的程序人生,期待你的关注和支持!本人外号:神秘小峯 山峯 转载说明:务必注明来源(注明:作者:王文峰哦) 【推荐】Perl入门教程特点功能文本处理读取文件替换文本写入文件分割字符数据库处理环境准备安装
Unix文本处理工具之sed
sed也是Unix的文本处理工具。sed是Stream Editor(流式编辑器)的缩写,它能够基于模式匹配过滤(所谓过滤就是在文件中找到符合某些条件的行)修改文本(就是对找到的符合条件的内容进行一些修改操作)。 1、sed命令格式 1.1 sed命令的基本格式 sed命令主要有三种使用形式: sed ‘编辑指令’ 文件1 文件2 ……:用于将处理后的结果输出 sed -n ‘
Unix文本处理工具之awk
Unix命令行下输入的命令是文本,输出也都是文本。因此,掌握Unix文本处理工具是很重要的一种能力。awk是Unix常用的文本处理工具中的一种,它是以其发明者(Aho,Weinberger和Kernighan)的名字首字符命名的,是一种基于模式匹配检查输入然后将期望的匹配结果处理后输出到屏幕的文本数据处理工具。 1、awk命令格式 awk ‘模式 {操作}’ 文件1 文件2 …… a

【LLM Agent 长文本】Chain-of-Agents与Qwen-Agent引领智能体长文本处理革命
前言 大模型在处理长文本上下文任务时主要存在以下两个问题: 输入长度减少:RAG的方法可以减少输入长度,但这可能导致所需信息的部分丢失,影响任务解决性能。扩展LLMs的上下文长度:通过微调的方式来扩展LLMs的上下文窗口,以便处理整个输入。当窗口变长时,LLMs难以集中注意力在解决任务所需的信息上,导致上下文利用效率低下。 下面来看看两个有趣的另辟蹊径的方法,使用Agent协同来处理长上下文
Elasticsearch分析器与分词器:定制文本处理流程
Elasticsearch分析器与分词器:定制文本处理流程 在Elasticsearch中,文本搜索和处理是核心功能之一。为了优化搜索效率和准确性,Elasticsearch提供了丰富的分析器(Analyzer)和分词器(Tokenizer)来定制文本处理流程。本文将介绍分析器和分词器的基本概念,并探讨如何定制文本处理流程以满足特定的需求。 一、分析器与分词器的基本概念 在Elasticse

Python文本处理利器:jieba库全解析
文章目录 Python文本处理利器:jieba库全解析第一部分:背景和功能介绍第二部分:库的概述第三部分:安装方法第四部分:常用库函数介绍1. 精确模式分词2. 全模式分词3. 搜索引擎模式分词4. 添加自定义词典5. 关键词提取 第五部分:库的应用场景场景一:文本分析场景三:中文分词统计 第六部分:常见bug及解决方案Bug 1:UnicodeDecodeErrorBug 2:Module
【linux】(6)文本处理sed
sed(stream editor)是可以根据指定的脚本对输入文本进行编辑、替换、删除等操作。 基本用法 sed [options] 'script' [file...] 常用选项 -n:抑制默认输出。通常 sed 会打印每一行,通过 -n 选项可以只打印被脚本处理的行。 sed -n 'p' filename -e:允许多脚本处理。可以指定多个 -e 选项来处理文本。 sed -
文本批量高效编辑器:一键在每行结尾添加分隔符,助力文本处理飞速提升!
在信息爆炸的时代,文本处理成为了一项不可或缺的技能。然而,面对大量的文本数据,如何高效地进行处理却成为了一项挑战。这时,一款高效、易用的文本批量编辑器就显得尤为重要。这个软件就是首助编辑高手 首先,打开首助编辑高手的主页面,您会被它简洁明了、直观易用的界面所吸引。在板块栏里,轻松找到并选择“文本批量操作”板块,您就已经迈出了高效文本处理的第一步。 进入操作页面,点击“添加文件”按钮,您就可
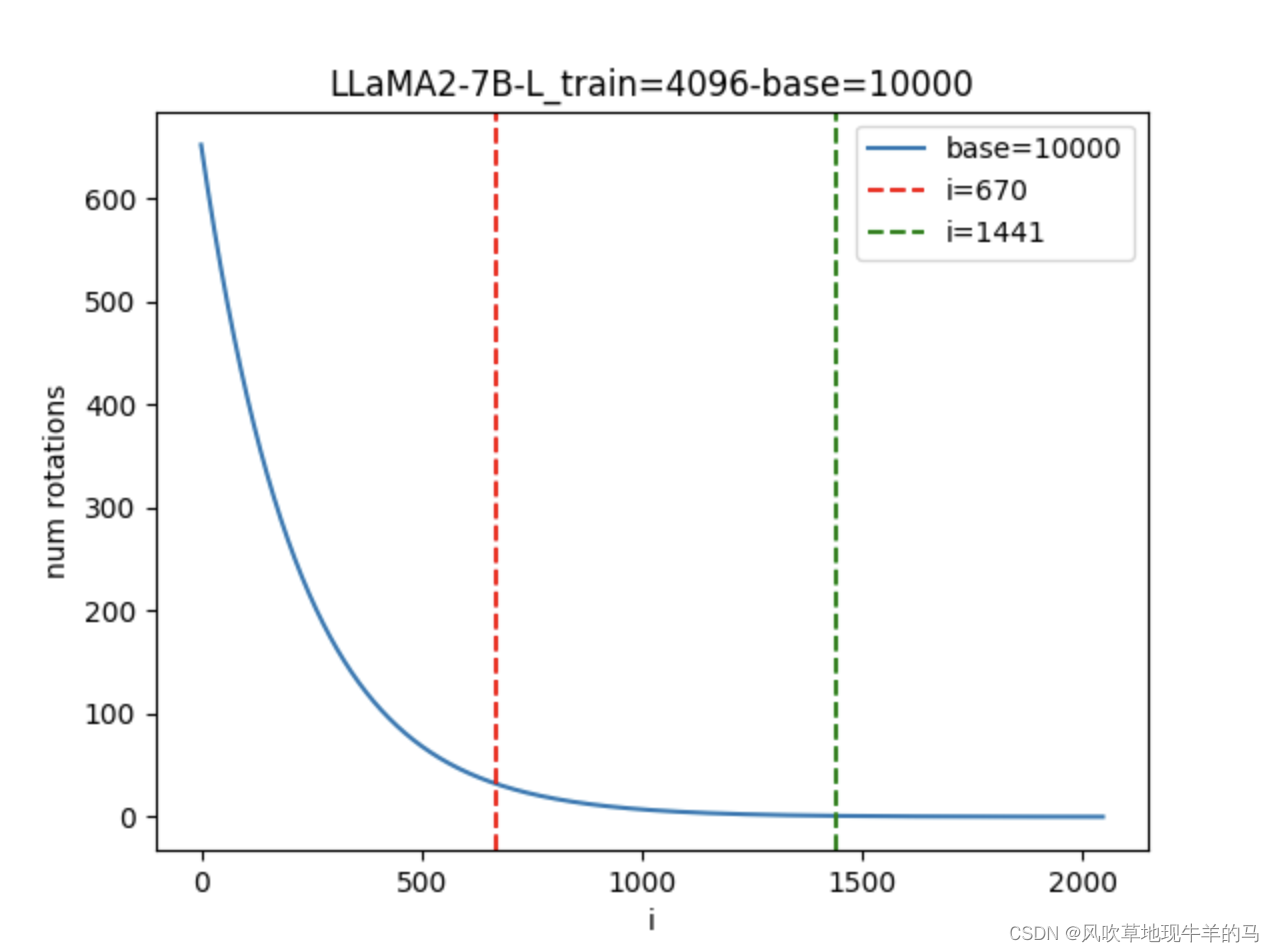
一文看懂如何增强LLM的长文本处理能力(包含代码和原理解析)
本篇博客是LLM中的RoPE位置编码代码解析与RoPE的性质分析(一)的续集,若对RoPE的性质不了解(比如远程衰减性、周期性与频率特性),建议先看LLM中的RoPE位置编码代码解析与RoPE的性质分析(一) 如何增强使用RoPE的LLM的处理长文本的能力 我们继续定义模型的训练长度为 L t r a i n L_{train} Ltrain,模型的测试长度为 L t e s t L_
Linux文本处理三剑客之awk命令
官方文档:https://www.gnu.org/software/gawk/manual/gawk.html 什么是awk? Awk是一种文本处理工具,它的名字是由其三位创始人(Aho、Weinberger和Kernighan)的姓氏首字母组成的。Awk的设计初衷是用于处理结构化文本数据,它提供了强大的模式匹配和数据提取功能。 Awk的工作方式是逐行扫描输入文本文件,并对每一行应用一
探索Linux中的强大文本处理工具——sed命令
探索Linux中的强大文本处理工具——sed命令 在Linux系统中,文本处理是一项日常且重要的任务。sed命令作为一个流编辑器,以其强大的文本处理能力而著称。它允许我们在不修改原始文件的情况下,对输入流(文件或管道)进行基本的文本转换。今天,我们就来深入了解一下sed命令的使用方法和一些常见示例。 1. sed命令的基本语法 sed命令的基本语法如下: sed [options] 'co
sed文本处理工具的用法:
用法1:前置命令 | sed [选项] '条件指令'用法2:sed [选项] '条件指令' 文件.. .. 步骤一:认识sed工具 sed命令的常用选项如下: -n(屏蔽默认输出,默认sed会输出读取文档的全部内容) -r(支持扩展正则) -i(修改源文件) 条件可以是行号或者/正则/,没有条件时默认为所有行都执行指令指令可以是p输出、d删除、s替换 p指令案例集锦(自己提前生成
Linux常用命令之【文本处理三剑客之sed】
sed命令 功能描述:sed可以对文件实现快速的增删改查 基本格式:sed [参数] [sed内置命令字符] 源文件 参数: -n:取消默认的sed的输出,常与sed内置命令p连用,只输出匹配的行 -i:直接修改文件内容,如果不使用-i,sed只是修改内存中的数据,并不会影响磁盘上的文件 sed内置命令字符: a:append,追加文本,在指定行后添加一行或多行文本 d:de
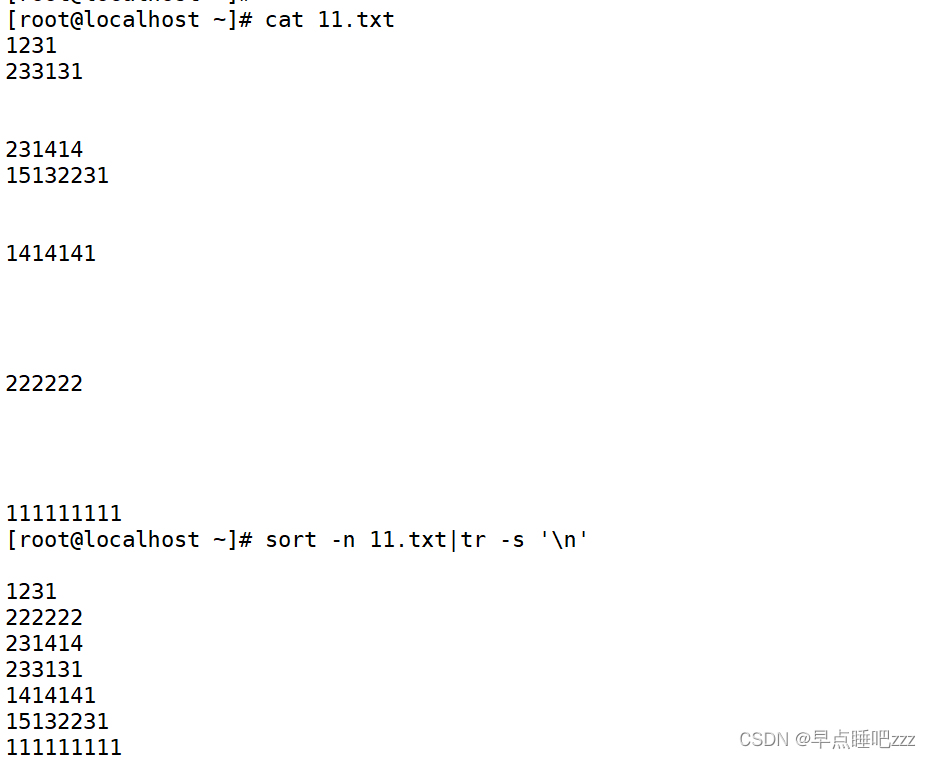
Shell之高效文本处理命令
目录 一、排序命令—sort 基本语法 常用选项 二、去重命令—uniq 基本语法 常用选项 三、替换命令—tr 基本语法: 常用选项 四、裁剪命令—cut 基本语法: 常用选项 字符串分片 五、拆分命令—split 基本语法: 六、 文件合并命令—paste 基本语法: 常用选项 常用命令 七、扫描命令—eval 实操

文本处理——fastText原理及实践(四)
博文地址:https://zhuanlan.zhihu.com/p/32965521 fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在