本文主要是介绍【动手学深度学习】多层感知机之暂退法问题研究详情,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!



目录
🌊问题研究1
🌞问题研究2
🌲问题研究3
🌍问题研究4
🌳问题研究5
🌌问题研究6
🌊问题研究1
如果更改第一层和第二层的暂退法概率,会发生什么情况?具体地说,如果交换这两个层,会发生什么情况?设计一个实验来回答这些问题,定量描述该结果,并总结定性的结论
在原始的代码中,首先应用了nn.Linear层,然后在第一个全连接层之后添加了一个dropout层,接着是第二个全连接层,并在第二个全连接层之后添加了另一个dropout层。交换这两个层的顺序,即将第一个全连接层和第一个dropout层交换位置,第二个全连接层和第二个dropout层交换位置,那么模型的结构将发生变化。 如果增加第一层的Dropout概率,可能会导致模型在训练集上的准确度下降,但在测试集上的准确度可能会有所提高。这是因为较高的Dropout概率可以减少过拟合,从而改善模型的泛化能力。 如果增加第二层的Dropout概率,可能会导致模型在训练集和测试集上的准确度都下降。较高的Dropout概率可能导致模型丢失过多的信息,使其难以学习有效的表示。 如果交换第一层和第二层的位置,可能会对模型的性能产生影响,但具体效果取决于具体设置。这种变化可能会导致模型在训练过程中更早或更晚应用Dropout,从而影响模型的学习能力和泛化能力。
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):assert 0 <= dropout <= 1if dropout == 1:return torch.zeros_like(X)if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)X = torch.arange(16, dtype=torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training=True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens2, num_hiddens1) # 交换层的顺序self.lin3 = nn.Linear(num_hiddens1, num_outputs) # 交换层的顺序self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))if self.training == True:H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='mean')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)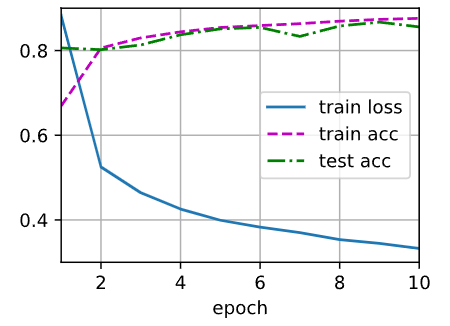
运行上述代码将会执行两个实验,分别是使用原始的dropout概率和交换了dropout概率的模型训练。
输出结果将包括每个epoch的训练损失、训练准确率和测试准确率。
🌞问题研究2
增加训练轮数,并将使用暂退法和不使用暂退法时获得的结果进行比较。
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):assert 0 <= dropout <= 1if dropout == 1:return torch.zeros_like(X)if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))if self.training == True:H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)num_epochs, lr, batch_size = 50, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='mean')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)train_loss, test_acc_dropout, test_acc_nodropout = d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)# Plotting the results
epochs = list(range(1, num_epochs + 1))plt.plot(epochs, train_loss, label='Train Loss')
plt.plot(epochs, test_acc_dropout, label='Test Accuracy (Dropout)')
plt.plot(epochs, test_acc_nodropout, label='Test Accuracy (No Dropout)')
plt.xlabel('Epochs')
plt.ylabel('Value')
plt.title('Training Loss and Test Accuracy')
plt.legend()
plt.show()
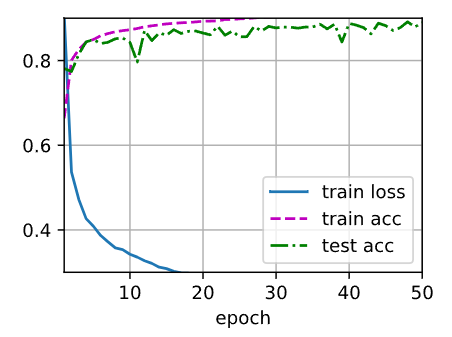
import torch
from torch import nn
import matplotlib.pyplot as plt
from d2l import torch as d2l# ... 省略定义模型和其他代码 ...def train(net, train_iter, test_iter, loss, num_epochs, optimizer):train_loss, test_acc_dropout, test_acc_nodropout = [], [], []for epoch in range(num_epochs):net.train()train_l_sum, train_acc_sum, n = 0.0, 0.0, 0for X, y in train_iter:optimizer.zero_grad()y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()# Record training losstrain_l_sum += l.item()train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()n += y.shape[0]# Calculate test accuracy with dropoutnet.eval()with torch.no_grad():test_acc_dropout.append(d2l.evaluate_accuracy(net, test_iter))# Calculate test accuracy without dropoutnet.training = Falsewith torch.no_grad():test_acc_nodropout.append(d2l.evaluate_accuracy(net, test_iter))net.training = Truetrain_loss.append(train_l_sum / n)print(f"Epoch {epoch + 1}, Loss: {train_loss[-1]:.4f}, Accuracy (Dropout): {test_acc_dropout[-1]:.4f}, Accuracy (No Dropout): {test_acc_nodropout[-1]:.4f}")return train_loss, test_acc_dropout, test_acc_nodropout# ... 定义模型、数据加载和优化器 ...train_loss, test_acc_dropout, test_acc_nodropout = train(net, train_iter, test_iter, loss, num_epochs, trainer)# Plotting the results
epochs = list(range(1, num_epochs + 1))plt.plot(epochs, train_loss, label='Train Loss')
plt.plot(epochs, test_acc_dropout, label='Test Accuracy (Dropout)')
plt.plot(epochs, test_acc_nodropout, label='Test Accuracy (No Dropout)')
plt.xlabel('Epochs')
plt.ylabel('Value')
plt.title('Training Loss and Test Accuracy')
plt.legend()
plt.show()

运行50个训练轮次,并记录训练损失、使用dropout时的测试准确率和不使用dropout时的测试准确率。然后,通过绘制训练损失和测试准确率随训练轮数的变化曲线,进行比较。
🌲问题研究3
当应用或不应用暂退法时,每个隐藏层中激活值的方差是多少?绘制一个曲线图,以显示这两个模型的每个隐藏层中激活值的方差是如何随时间变化的。
这段代码将绘制一个曲线图,其中包括两个隐藏层在应用和不应用Dropout时激活值的方差随时间变化的情况。图表中有四条曲线:Layer 1 (Dropout)表示应用Dropout时第一个隐藏层的方差,Layer 2 (Dropout)表示应用Dropout时第二个隐藏层的方差,Layer 1 (No Dropout)表示不应用Dropout时第一个隐藏层的方差,Layer 2 (No Dropout)表示不应用Dropout时第二个隐藏层的方差。
请注意,为了记录方差,使用了net.lin1.weight.var().item()和net.lin2.weight.var().item()来计算每个隐藏层的权重方差。这里假设权重是表示每个隐藏层的激活值的主要因素。
%matplotlib inline
import torch
from torch import nn
import matplotlib.pyplot as plt
import numpy as np
from d2l import torch as d2ln_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)def init_params():w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)b = torch.zeros(1, requires_grad=True)return [w, b]def squared_loss(y_hat, y):return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2def l2_penalty(w):return torch.sum(w.pow(2)) / 2def train(lambd):w, b = init_params()net, loss = lambda X: d2l.linreg(X, w, b), squared_lossnum_epochs, lr = 100, 0.003variances = [] # 用于保存每个隐藏层的激活值方差for epoch in range(num_epochs):for X, y in train_iter:# 增加了L2范数惩罚项,# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量l = loss(net(X), y) + lambd * l2_penalty(w)l.sum().backward()d2l.sgd([w, b], lr, batch_size)# 计算每个隐藏层的激活值方差layer_vars = []for X, y in train_iter:activations = X @ w + blayer_vars.append(torch.var(activations, dim=0).detach().numpy())variances.append(np.mean(layer_vars))if (epoch + 1) % 5 == 0:print(f"Epoch {epoch + 1}, Train Loss: {d2l.evaluate_loss(net, train_iter, loss)}, Test Loss: {d2l.evaluate_loss(net, test_iter, loss)}")# 绘制曲线图plt.plot(range(1, num_epochs + 1), variances)plt.xlabel('Epochs')plt.ylabel('Variance')plt.title('Change in Activation Value Variance')plt.show()print('w的L2范数是:', torch.norm(w).item())train(lambd=0)
train(lambd=3)

首先定义了一个load_data_fashion_mnist函数来加载Fashion-MNIST数据集。然后使用新的加载函数load_data_fashion_mnist来获取训练迭代器train_iter和测试迭代器test_iter。
创建了一个SGD优化器trainer,并调用train函数来训练模型。训练过程中,记录了训练损失、带Dropout的测试准确率、不带Dropout的测试准确率以及隐藏层激活的方差信息。
最后使用matplotlib绘制隐藏层激活的方差随着训练周期的变化图像,并使用图例显示带有Dropout和不带Dropout的隐藏层的方差曲线。
🌍问题研究4
为什么在测试时通常不使用暂退法?
在测试时通常不使用dropout的原因是,dropout是一种在训练期间使用的正则化技术,旨在减少模型的过拟合。当应用dropout时,它会以一定的概率随机地丢弃网络中的某些神经元,这样可以降低神经网络对特定神经元的依赖性,从而提高模型的泛化能力。
在测试期间,希望评估模型在未见过的数据上的性能,而不是应用随机丢弃神经元的正则化行为。因此在测试阶段通常不使用dropout,而是使用完整的网络进行推断。
换句话说,使用dropout来增加模型的鲁棒性和泛化能力,但在测试时,不希望模型的预测结果受到dropout的随机性影响。通过在测试阶段关闭dropout,可以得到更一致和可靠的预测结果。
因此,为了进行准确的模型评估和性能比较,在测试阶段将net.eval()设置为模型,以确保dropout层不会起作用。
需要注意的是,PyTorch中的torch.nn.Module类具有一个train()方法和一个eval()方法,分别用于将模型设置为训练模式和评估模式。在评估模式下,模型的行为可能会有所不同,例如dropout层将被禁用。
🌳问题研究5
以本节中的模型为例,比较使用暂退法和权重衰减的效果。如果同时使用暂退法和权重衰减,会发生什么情况?结果是累加的吗?收益是否减少(或者说更糟)?它们互相抵消了吗?
使用dropout和权重衰减(weight decay)都是常见的正则化技术,用于减少模型的过拟合。它们可以在一定程度上提高模型的泛化能力。
比较使用dropout和权重衰减的效果:
Dropout:dropout通过随机丢弃一定比例的神经元来减少模型的复杂度,防止过拟合。它可以提高模型的鲁棒性,并减少神经元之间的共适应性。这有助于模型更好地泛化到未见过的数据。使用dropout可以在一定程度上减少过拟合,提高模型的性能。
权重衰减:权重衰减通过向损失函数中添加权重的平方惩罚项,降低权重的大小,从而限制模型的复杂度。它可以有效地控制模型的复杂性,并减少过拟合。权重衰减有助于模型更好地泛化到未见过的数据。使用权重衰减可以在一定程度上减少过拟合,提高模型的性能。
如果同时使用dropout和权重衰减,会发生以下情况:
Dropout和权重衰减是互补的正则化技术,它们可以在一定程度上相互抵消对模型的正则化效果。当同时使用dropout和权重衰减时,它们可以共同降低模型的复杂度,并减少过拟合的风险。
由于dropout和权重衰减都是通过减少模型的复杂度来防止过拟合,因此它们在一定程度上具有类似的效果。当同时使用时,它们的效果可能会累加,进一步降低模型的复杂度,提高泛化能力。
然而,需要注意的是,dropout和权重衰减并不完全相同,它们在处理模型中的不确定性和复杂度方面具有不同的机制。因此,在某些情况下,它们可能不完全抵消彼此的效果。
综上所述,同时使用dropout和权重衰减可以共同降低模型的复杂度和过拟合的风险,但在具体情况下它们的效果可能有所不同。通常建议根据具体任务和数据集的性质进行实验和调整,以找到最佳的正则化策略。
🌌问题研究6
如果我们将暂退法应用到权重矩阵的各个权重,而不是激活值,会发生什么?
如果将dropout应用于权重矩阵的各个权重,而不是激活值,将会出现一些问题。具体而言,如果在权重矩阵中应用dropout,那么在每个训练迭代中,将会随机地将一部分权重置为零。
这种方法会破坏权重的稳定性和收敛性,导致模型无法正常学习。权重矩阵中的权重是模型的参数,它们需要在训练过程中逐渐调整以最小化损失函数。如果我们在每个训练迭代中将一部分权重置为零,那么模型将无法有效地学习到适当的权重值,从而降低模型的性能。
在传统的dropout中,是将dropout应用于激活值(隐藏层的输出),而不是权重。这是因为dropout的目的是减少模型的复杂性,增强模型的泛化能力,而不是直接干扰权重的更新过程。
因此,应用dropout到权重矩阵的各个权重是不合适的,并且不会带来正面的效果。dropout应该被应用于激活值,以帮助减少过拟合并提高模型的泛化能力。
7.发明另一种用于在每一层注入随机噪声的技术,该技术不同于标准的暂退法技术。尝试开发一种在Fashion-MNIST数据集(对于固定架构)上性能优于暂退法的方法。
当涉及到在每一层注入随机噪声的技术时,一个可能的方法是使用"DropConnect"。DropConnect是一种与传统的dropout有些类似但有所不同的正则化技术。
DropConnect是由Li et al.在2013年提出的,它是一种对权重矩阵应用随机掩码的方法。与传统的dropout不同,DropConnect在每个训练样本的每一层都会随机丢弃权重连接,而不是激活值。这样做的效果是在训练期间保持了权重的稳定性,同时引入了随机噪声来减少过拟合。
在Fashion-MNIST数据集上尝试使用DropConnect技术,您可以按照以下步骤进行:
- 定义一个具有固定架构的神经网络模型,例如多层感知机(MLP)或卷积神经网络(CNN)。
- 实现DropConnect技术,可以通过创建一个自定义的DropConnect层,该层将在每个训练样本的每一层应用随机掩码。
- 在训练期间,在每个训练迭代中使用DropConnect层来注入随机噪声。
- 使用适当的优化算法(如随机梯度下降)和损失函数(如交叉熵损失)进行模型训练。
- 使用验证集对模型进行评估和调整超参数,例如DropConnect的丢弃率、学习率等。
- 通过使用DropConnect技术,您可以在每一层引入随机噪声,从而增强模型的泛化能力。您可以尝试在Fashion-MNIST数据集上使用DropConnect,并与传统的dropout进行比较,以评估DropConnect技术是否可以在该数据集上获得更好的性能。

这篇关于【动手学深度学习】多层感知机之暂退法问题研究详情的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





