本文主要是介绍超越GPT-4 LoRA技术引领大型语言模型新革命,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读

探索语言模型的新境界 —— LoRA Land 技术解读
亲爱的读者朋友们,今天我们将一起深入探索一项激动人心的研究 ——《LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report》。这篇由 Predibase 团队撰写的技术报告,为我们揭开了大型语言模型(LLMs)通过低秩适应(LoRA)方法进行参数高效微调(PEFT)的神秘面纱。通过这种方法,研究者们成功训练出310个与GPT-4相媲美的微调模型,不仅在性能上取得了显著提升,更在资源利用和成本效益上展现了巨大潜力。
在这篇论文解读中,我们将详细解读LoRA技术的核心原理,探讨它如何在减少训练参数和内存使用的同时,实现与全参数微调相仿的性能。同时,我们将一起见证LoRA Land项目如何通过LoRAX服务器,在单个GPU上高效部署25个LoRA微调模型,为特定任务提供专业化服务。
无论你是AI领域的专业人士,还是对最新科技进展充满好奇的普通读者,这篇文章都将带你一窥LLMs的未来发展方向,以及它们在现实世界应用中的无限可能。让我们一起启程,探索LoRA Land的奇妙世界吧!
引言:探索LoRA在大型语言模型中的应用
在人工智能领域,大型语言模型(LLMs)的发展日新月异,它们在多种任务中展示了卓越的性能。然而,这些模型通常需要大量的计算资源和内存,这限制了它们的实用性和可访问性。为了解决这一问题,低秩适应(LoRA)技术应运而生,它通过在保持模型性能的同时减少可训练参数的数量和内存使用,为参数高效的微调提供了一种有效的方法。
LoRA的核心思想是在大型语言模型的冻结层之间插入低秩矩阵,这些矩阵较小且易于训练,能够显著减少模型调整的复杂性和成本。这种方法不仅保持了模型的灵活性,还大大降低了部署和运行大型模型所需的资源。本文将深入探讨LoRA在实际应用中的表现和潜力,特别是它如何在不牺牲性能的情况下,实现对大型语言模型的高效微调。
论文概览
标题: LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
作者: Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
链接: https://arxiv.org/pdf/2405.00732.pdf
本文通过对310个使用LoRA微调的大型语言模型(LLMs)进行综合评估,展示了LoRA技术在提升模型性能方面的有效性。研究团队不仅探讨了LoRA微调模型在多种任务上的表现,还评估了这些模型在实际应用中的部署效率。此外,文章还详细介绍了LoRA技术的实现细节和优化策略,为未来的研究和应用提供了宝贵的参考。

LoRA技术简介
Low Rank Adaptation(LoRA)是一种用于大型语言模型(LLMs)的参数高效微调(PEFT)方法,近年来得到了广泛的采用。LoRA通过在模型的冻结权重层旁增加少量的可训练低秩矩阵,显著减少了可训练参数的数量,同时几乎不增加推理时的计算负担。这种方法不仅节省了内存使用,还能在保持与全参数微调相当的性能的同时,实现更高的计算效率。
LoRA的核心思想是在不完全解冻原始模型的情况下,通过微调少量的参数来适应下游任务。这种策略与传统的微调方法相比,可以显著减少对计算资源的需求,使得在资源受限的环境中部署大型语言模型成为可能。此外,LoRA的设计允许它与其他参数高效的微调技术(如Prompt-based和Adapter-based方法)结合使用,进一步提升模型的灵活性和效能。
在实际应用中,LoRA已被证明能够有效提升模型在特定任务上的表现,例如在多个基准测试中超越了GPT-4等先进模型。通过对比不同的基模型和任务复杂性,LoRA不仅展示了其在提升模型性能方面的潜力,还揭示了其在处理特定类型任务时的优势,特别是在那些对参数数量和计算效率要求较高的场景中。
实验设计与数据集选择
1. 数据集的选择
在本研究中,我们选择了多种数据集来评估LoRA微调方法的效果。这些数据集包括广泛的领域知识(如MMLU)、内容审查(如Jigsaw)、SQL生成(如WikiSQL)以及GLUE基准测试。这些数据集不仅在学术界和工业界广泛使用,而且它们的多样性和复杂性可以充分测试LoRA微调方法在不同任务上的适应性和效果。
2. 任务类型的分类
我们将这些数据集涵盖的任务分为五类,以便更系统地评估LoRA的效果:
- 经典NLP任务:涉及命名实体识别、数据到文本生成等。
- 知识型任务:包括多项选择题等。
- 推理型任务:涉及逻辑和推理的多项选择题。
- 数学问题:基于数学的文字问题。
- 内容生成:如新闻头条生成等。
这种分类方法不仅帮助我们系统地评估LoRA在不同类型任务上的表现,还为后续的模型优化和应用提供了重要的指导。
3. 实验设计
所有的LLMs都使用相同的训练参数进行微调,以确保实验结果的一致性和可比性。我们采用零或单次射击的完成式提示,简化了查询过程,并尽可能减少了因提示设计差异引起的性能变异。此外,我们还特别关注模型在单一GPU上的训练和部署效率,通过动态适配器加载技术,实现了在单一硬件上部署和服务多个LoRA微调模型的能力。
通过这种严谨的实验设计和多样化的数据集选择,我们的研究不仅展示了LoRA在多个任务和模型上的广泛适用性,还验证了其在实际应用中的高效性和经济效益。

LoRA微调的效果分析
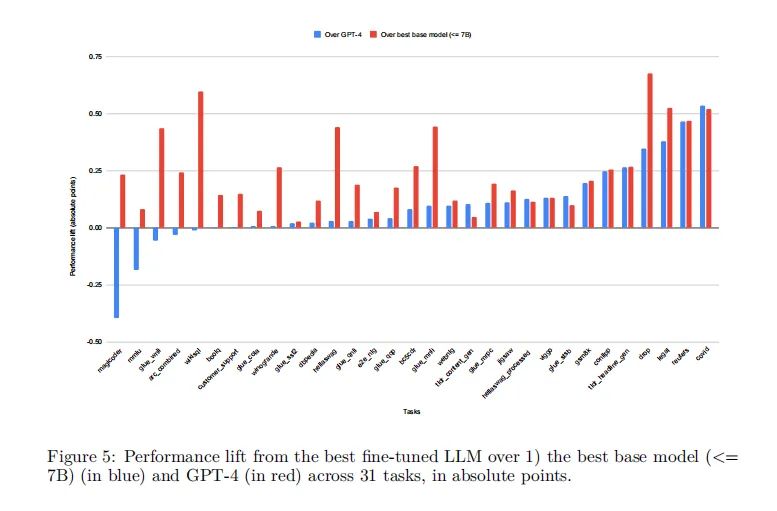
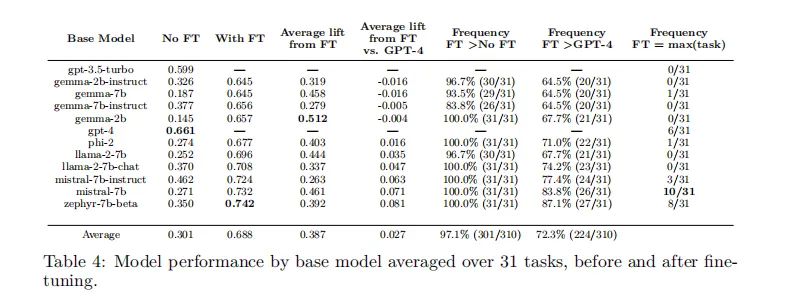
在对大型语言模型(LLMs)进行微调的过程中,低秩适应(LoRA)方法已被广泛采用,因为它在减少可训练参数数量和内存使用的同时,能够达到与全面微调相媲美的性能。通过对310个使用LoRA微调的模型进行评估,我们发现这些模型在多种任务上的表现普遍优于基础模型。具体来说,使用4位LoRA微调的模型平均比基础模型高出34分,比GPT-4高出10分。
我们的实验涵盖了10种基础模型和31种任务,总计310个LLM经过LoRA微调。这些模型在相同的训练参数下进行微调,并使用简单的单次提示进行查询,以确保评估的一致性。通过这种标准化的比较框架,我们能够准确地评估不同基础模型在经过LoRA微调后的内在能力。
在所有任务中,经过LoRA微调的模型平均性能(0.756)显著高于GPT-4(0.661)。这一发现不仅验证了LoRA微调的有效性,也突显了在特定任务上使用专门化的小模型而非单一的通用大模型的优势。
LoRAX服务器:多模型高效服务
LoRAX是一个开源的多LoRA推理服务器,专为在单个GPU上同时服务多个LoRA微调模型而设计。与传统的独立LLM部署相比,LoRAX具有几个创新的组件:
动态适配器加载:允许在运行时按需从存储中加载每组微调LoRA权重,而不会阻塞并发请求。

连续多适配器批处理:一种公平的调度策略,通过在多个LoRA适配器集上并行工作来优化系统的总体吞吐量。
分层权重缓存:支持在请求之间快速交换LoRA适配器,并将适配器权重卸载到CPU和磁盘,以避免内存溢出错误。
在实际应用中,LoRAX成功部署了25个LoRA微调的Mistral-7B LLM,这些模型被用于服务数千名用户,所有模型均部署在单个NVIDIA A100 GPU上。我们的基准测试显示,即使在负载增加的情况下,系统的延迟和吞吐量表现仍然稳定,证明了LoRAX在处理高并发和大规模部署方面的有效性。
总体而言,LoRAX不仅提高了部署效率,还通过支持多模型并发处理,显著降低了成本和资源消耗,使得在实际生产环境中使用多个专门化的LLM成为可能。
性能基准与部署效果
在本研究中,我们对310个使用LoRA方法微调的大型语言模型(LLM)进行了性能评估。这些模型覆盖了10种基础模型和31种任务。通过对比微调前后的性能,我们发现LoRA微调显著提升了模型的表现。
1. 性能提升概览
根据我们的数据,使用LoRA微调的模型在多数任务中表现优于基础模型。具体来说,微调后的模型在31个任务中的平均表现比GPT-4高出约10个百分点。这一发现突出了LoRA微调策略在提升特定任务性能方面的有效性。
2. 部署效果
我们使用LoRAX,一个开源的多LoRA推理服务器,来部署这些微调后的模型。LoRAX支持在单个GPU上同时服务多个LoRA微调模型,通过共享基础模型权重和动态适配器加载来优化资源使用。在实际部署中,LoRA Land网应用能够在单个NVIDIA A100 GPU上托管25个LoRA微调的Mistral-7B LLM,展示了在单一硬件资源上部署多个专业化LLM的经济效率和实用性。
讨论与分析
1. 基础模型和任务选择的影响
我们的分析显示,不同的基础模型和任务类型对微调效果有显著影响。例如,Mistral-7B和Zephyr-7b模型在多数任务中表现出色,这可能与它们的架构特性和适应性有关。此外,我们发现任务的复杂性也是一个重要因素,简单的分类任务往往能够通过微调获得更大的性能提升。
2. 微调与任务复杂性的关系
通过对任务复杂性和微调质量提升的相关性分析,我们发现一些有趣的模式。例如,任务的输入输出长度、内容多样性和压缩性等因素与模型性能提升之间存在相关性。这些发现为未来在选择微调策略和预测微调效果时提供了有价值的见解。
3. 部署性能的实际观察
在LoRA Land的实际部署中,我们观察到即使在用户并发量大幅增加时,系统的响应时间和吞吐量仍能保持在合理范围内。这证明了LoRAX在实际应用中处理高并发请求的能力,同时也突显了使用动态适配器加载技术的优势。
总体而言,我们的研究不仅展示了LoRA微调方法在提升LLM性能方面的有效性,也验证了在实际应用中部署多个微调模型的可行性和效率。未来的工作可以进一步探索不同微调策略和基础模型选择对性能的具体影响,以及如何进一步优化模型部署的成本效益。
结论与未来展望
在本研究中,我们探讨了低秩适应(LoRA)对大型语言模型(LLM)进行微调的有效性,以及在生产环境中同时服务多个微调后的LoRA LLM的可行性。
1. 模型质量
我们的结果验证了LoRA微调显著提升了LLM的性能,超越了未经微调的基础模型和GPT-4。特别是像Mistral-7B这样的模型在多个任务上表现出色,突显了在微调成功中选择合适的基础模型的重要性。我们发现,任务的复杂性启发式可以作为预测微调成功的潜在指标,这表明任务的性质在微调的有效性中扮演重要角色。
2. 模型服务
通过LoRAX框架,我们展示了在LoRA Land网络应用中实际部署这些模型的情况。我们提供了首次令牌时间(TFTT)、总请求时间和令牌流时间的基准,并测量了LoRAX在多达100个并发用户的情况下的延迟稳健性。
LoRA Land强调了使用多个专门的LLM而不是单一的通用LLM的质量和成本效益。
3. 限制与改进方向
尽管取得了这些成果,但评估的规模、训练限制和我们的提示工程方法的简单性表明了未来改进的领域。我们释放了所有的模型和训练设置,以供社区进一步验证和实验。
4. 未来研究方向
未来的研究应考虑更全面的评估,以允许资源允许的情况下,更好地理解微调在不同任务和模型规模上的效果。此外,探索更广泛的模型大小,包括更大的模型,如13B或70B,可能提供关于不同计算能力下微调的可扩展性和有效性的见解。
总之,本研究不仅展示了LoRA在提升特定任务的LLM性能方面的潜力,还成功地展示了在实际应用中训练和服务多个任务专用LLM的实际效率。
这篇关于超越GPT-4 LoRA技术引领大型语言模型新革命的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!