本文主要是介绍传统RAG破局者:混合检索助力新纪元,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI如何读懂你?混合检索技术揭秘
©作者|Steven
来源|神州问学
一、RAG 概念解释
向量检索为核心的 RAG 架构已成为解决大模型获取最新外部知识,同时解决其生成幻觉问题时的主流技术框架,并且已在相当多的应用场景中落地实践。开发者可以利用该技术低成本地构建一个 AI 智能客服、企业智能知识库、AI 搜索引擎等,通过自然语言输入与各类知识组织形式进行对话。以一个有代表性的 RAG 应用为例:
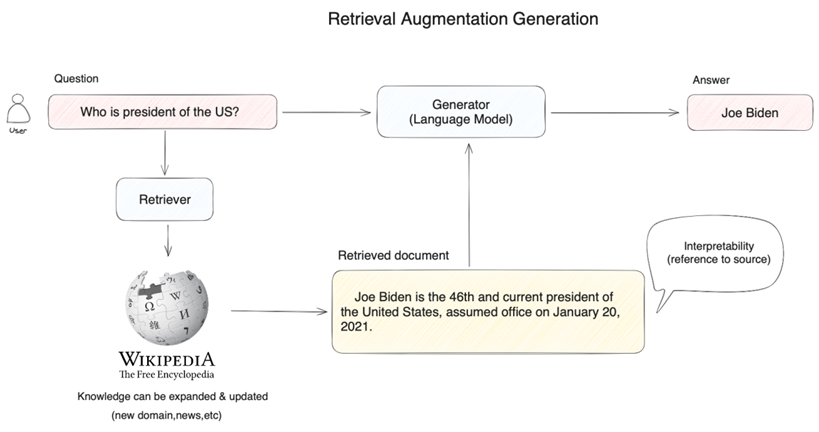
在下图中,当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量检索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统…),然后再将用户问题和检索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
二、传统RAG检索瓶颈
传统RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的方式。技术原理是通过将外部知识库的文档先拆分为语义完整的段落或句子,并将其转换(Embedding)为计算机能够理解的一串数字表达(多维向量),同时对用户问题进行同样的转换操作。
计算机能够发现用户问题与句子之间细微的语义相关性,比如 “猫追逐老鼠” 和 “小猫捕猎老鼠” 的语义相关度会高于 “猫追逐老鼠” 和 “我喜欢吃火腿” 之间的相关度。在将相关度最高的文本内容查找到后,RAG 系统会将其作为用户问题的上下文一起提供给大模型,帮助大模型回答问题。
虽然向量检索在以上情景中具有明显优势,但有在某些情况下,呈现的效果不佳,比如:
●搜索一个人或物体的名字(例如,伊隆·马斯克,iPhone 15)
●搜索缩写词或短语(例如,RAG,RLHF)
●搜索 ID(例如, gpt-3.5-turbo , titan-xlarge-v1.01 )
简单来说,向量检索在语义理解方面具有优势,但前提是检索问题的长度要达到一定量级,才能在转化为向量之后,通过相似度匹配到语义最接近的内容,一旦用户有检索短词短句,或是具有特殊语义的句子,向量检索的效果就会大大折扣,因而模型生成准确度也会下降。
而上面这些的缺点恰恰都是传统关键词检索的优势所在,传统关键词检索擅长:
●精确匹配(如产品名称、姓名、产品编号)
●少量字符的匹配(通过少量字符进行向量检索时效果非常不好,但很多用户恰恰习惯只输入几个关键词)
●倾向低频词汇的匹配(低频词汇往往承载了语言中的重要意义,比如“你想跟我去喝咖啡吗?”这句话中的分词,“喝”“咖啡”会比“你”“想”“吗”在句子中承载更重要的含义)
三、引入混合检索
2023年9月,Microsoft Azure AI 在官方博客上发布了一篇题为《Azure 认知搜索:通过混合检索和排序能力超越向量搜索》的文章。该文对在 RAG 架构的生成式 AI 应用中引入混合检索和重排序技术进行了全面的实验数据评估,量化了该技术组合对改善文档召回率和准确性方面的显著效果。
从本质上讲,混合检索类似于炼金术士的混合药水,无缝地融合了不同的检索算法,以提炼出无与伦比的相关性药水。将传统的基于关键字的检索想象成坚实的基础,植根于精确的术语匹配,但容易受到拼写错误和同义词的影响。相比之下,向量或语义检索的出现引入了上下文感知的闪亮面纱,超越了语言障碍和印刷错误。通过融合这些元素,混合检索产生了一种超越单个方法局限的协同作用,揭示了以前隐藏在数字混乱层下的洞察力宝库。
混合检索将两种或多种检索算法组合在一起以提高检索结果相关性的检索技术。虽然没有定义组合哪些算法,但混合检索通常是指传统的基于关键字的检索和现代向量检索的组合。
传统上,基于关键字的检索是检索引擎的明显选择。但随着机器学习 (ML) 算法的出现,向量嵌入启用了一种新的检索技术——称为向量或语义检索——使我们能够在语义上检索数据。但是,这两种检索技术都需要考虑以下基本权衡:
●基于关键字的检索:虽然它的精确关键字匹配功能对特定术语(如产品名称或行业术语)有益,但它对错别字和同义词很敏感,这会导致它错过重要的上下文。
●向量或语义检索:虽然它的语义检索功能允许基于数据的语义含义进行多语言和多模态检索,并使其对拼写错误具有鲁棒性,但它可能会错过重要的关键词。此外,它取决于生成的向量嵌入的质量,并且对域外项很敏感。
将基于关键字的检索和矢量检索结合到混合检索中,可以利用这两种检索技术的优势来提高检索结果的相关性,尤其是对于文本检索用例。
例如,考虑检索查询“如何将两个 Pandas DataFrame 与 ?”合并。关键字检索将有助于找到该方法的相关结果。但是,由于“合并”一词具有“合并”、“连接”和“连接”等同义词,因此如果我们能够利用语义检索的上下文感知,将会很有帮助。
四、混合检索的原理
混合检索通过融合检索结果并重新排名,结合了基于关键字和向量检索技术。
●基于关键字的检索
在混合检索的上下文中,基于关键字的检索通常使用一种称为稀疏嵌入的表示形式,这就是为什么它也被称为稀疏向量检索。稀疏嵌入是大部分值为零的向量,只有少数非零值,如下所示。
[0, 0, 0, 0, 0, 1, 0, 0, 0, 24, 3, 0, 0, 0, 0, ...]
稀疏嵌入可以使用不同的算法生成。稀疏嵌入最常用的算法是 BM25(最佳匹配 25),它建立在 TF-IDF(术语频率-反向文档频率)方法的基础上并对其进行了改进。简单来说,BM25 强调术语的重要性,这些术语基于它们在文档中的频率相对于它们在所有文档中的频率。
●矢量检索
矢量检索是一种现代检索技术,随着 ML 的进步而出现。现代 ML 算法(如 Transformers)可以以各种模态(文本、图像等)生成数据对象的数值表示,称为向量嵌入。
这些向量嵌入通常包含密集的信息,并且主要由非零值(密集向量)组成,如下所示。这就是为什么向量检索也被称为密集向量检索的原因。
[0.634, 0.234, 0.867, 0.042, 0.249, 0.093, 0.029, 0.123, 0.234, ...]
搜索查询嵌入到与数据对象相同的向量空间中。然后,利用其向量嵌入,根据指定的相似度指标(如余弦距离)计算最接近的数据对象。返回的搜索结果会列出最接近的数据对象,这些对象按其与搜索查询的相似性进行排名。
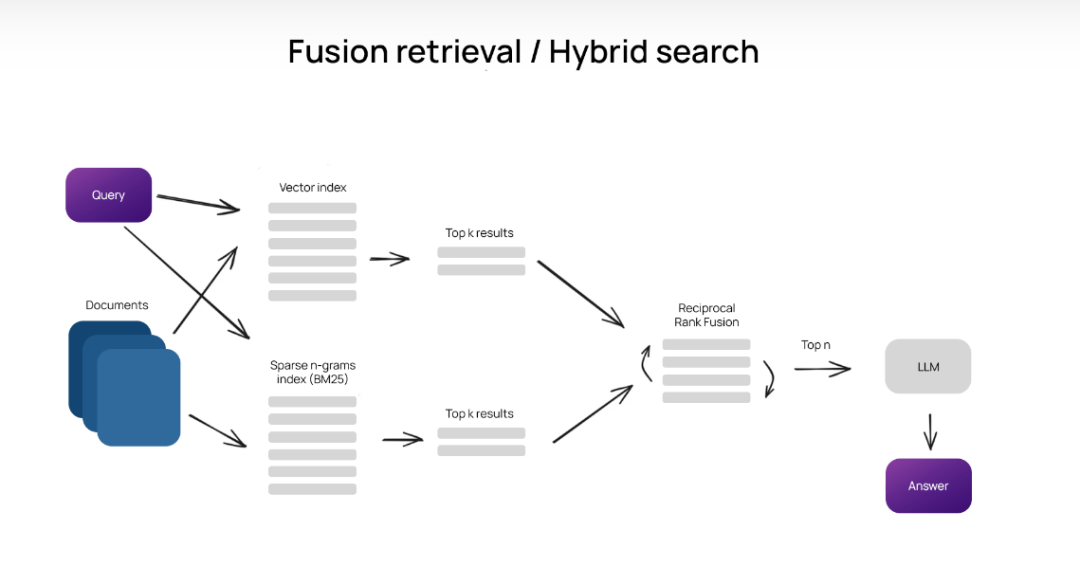
●基于关键字和向量搜索结果的融合
基于关键字的搜索和矢量搜索都返回一组单独的结果,通常是按计算的相关性排序的搜索结果列表。必须将这些单独的搜索结果集组合在一起。
有许多不同的策略可以将两个列表的排名结果合并为一个单一的排名,一般来说,搜索结果通常是首先评分的。这些分数可以根据指定的指标(例如余弦距离)计算,也可以仅根据搜索结果列表中的排名进行计算。
然后,计算出的分数用一个参数进行加权,该参数决定了每个算法的权重并影响结果的重新排名。

通常,alpha 取一个介于 0 和 1 之间的值,其中
alpha = 1:纯矢量搜索
alpha = 0:纯关键字搜索
下面,您可以看到关键字和向量搜索之间融合的最小示例,其中包含基于排名和 .alpha = 0.5
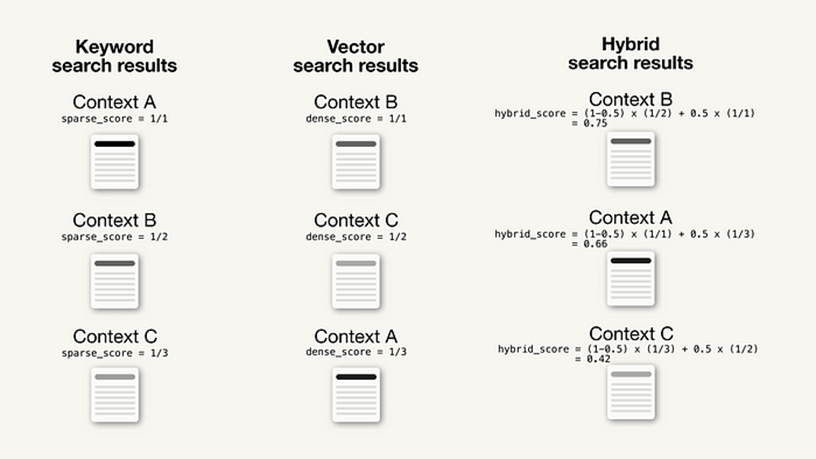
五、Azure AI 实验数据评估
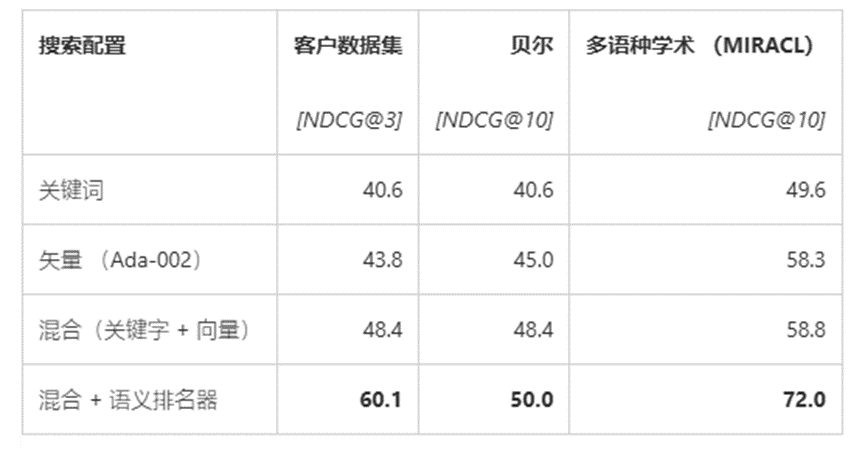
Azure AI 对 RAG 中几种常用的检索模式做了实验数据测试,包括关键词检索、向量检索、混合检索、混合检索 + 重排序。实验结果支持将混合检索 + 重排序视为改进文档召回相关性的有效方法,对于使用 RAG 架构的生成式 AI 场景尤其适用。
以下是针对不同数据集类型的测试结果,可以看到混合检索 + 重排序的组合在不同测试集下的召回质量上都有一定程度的提升。
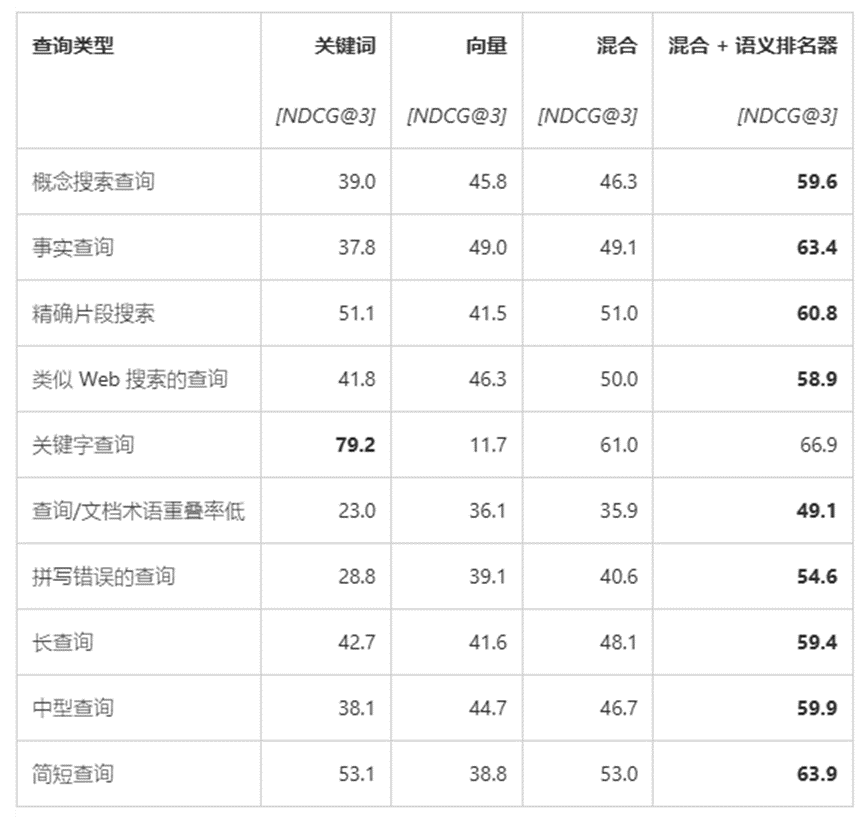
以下是针对不同查询情景的评估结果,可以看到在各个用例情景下,混合检索 + 重排序在不同程度上提升了文档召回的质量。
六、何时使用混合检索?
混合搜索非常适合以下用例:希望启用语义搜索功能以获得更像人类的搜索体验,但还需要针对特定术语(如产品名称或序列号)进行精确的短语匹配。
一个很好的例子是 Stack Overflow 平台,它通过使用混合搜索扩展了其语义搜索的搜索功能。

最初,Stack Overflow 使用 TF-IDF 将关键字与文档匹配。但是,描述尝试解决的编码问题可能很困难。根据您用来描述问题的词语,它可能会导致不同的结果(例如,合并两个 Pandas DataFrame 可以通过不同的方法完成,例如合并、连接和连接)。因此,对于这些情况,一种更具上下文感知能力的搜索方法(例如语义搜索)将更有益。
但是,另一方面,Stack Overflow 的一个常见用例是复制粘贴错误消息。在这种情况下,精确关键字匹配是首选的搜索方法。此外,还需要方法和参数名称的精确关键字匹配功能。
许多类似的现实世界用例都受益于上下文感知语义搜索,但仍然依赖于精确的关键字匹配。这些用例可以从实现混合搜索检索器组件中受益匪浅。
总结
本文介绍了混合搜索的概念,即基于关键字的搜索和向量搜索的组合。混合搜索合并了单独搜索算法的搜索结果,并相应地对搜索结果进行了重新排序。
在混合搜索中,该参数控制基于关键字的搜索和语义搜索之间的权重。此参数可以被视为一个超参数,用于优化 RAG 管道以提高搜索结果的准确性。
使用 Stack Overflow案例研究,展示了混合搜索如何用于语义搜索可以改善搜索体验的用例。但是,当特定术语频繁出现时,精确的关键字匹配仍然很重要。
参考文献
[1] Microsoft Tech Community. (2023, April 24). Azure AI Search: Outperforming Vector Search with Hybrid. Retrieved from
https://techcommunity.microsoft.com/t5/ai-azure-ai-services-blog/azure-ai-search-outperforming-vector-search-with-hybrid/ba-p/3929167
[2] Towards Data Science. Improving Retrieval Performance in RAG Pipelines with Hybrid Search. Available at:
https://towardsdatascience.com/improving-retrieval-performance-in-rag-pipelines-with-hybrid-search-c75203c2f2f5. Accessed May 24, 2024.
[3] Dify AI Documentation. Hybrid Search. Available at:
https://docs.dify.ai/v/zh-hans/learn-more/extended-reading/retrieval-augment/hybrid-search. Accessed May 24, 2024.
这篇关于传统RAG破局者:混合检索助力新纪元的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!