本文主要是介绍sqli-labs 靶场闯关基础准备、学习步骤、SQL注入类型,常用基本函数、获取数据库元数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Sqli-labs的主要作用是帮助用户学习如何识别和利用不同类型的SQL注入漏洞,并了解如何修复和防范这些漏洞。
它提供了多个不同的漏洞场景,每个场景都代表了一个特定类型的SQL注入漏洞。
用户可以通过攻击这些场景来学习和实践漏洞利用技术,以及相应的修复和防御措施。
Sqli-labs还提供了详细的漏洞说明和解决方案,帮助用户理解漏洞的原理、影响和防御方法。

Sqli-labs是一个用于学习和练习SQL注入漏洞的开源应用程序。它提供了一系列的漏洞场景和练习环境,帮助用户了解和实践SQL注入漏洞的利用技术。
学习步骤
学习Sqli-labs需要的基础主要包括对SQL语言和Web应用程序安全性的基本了解。
对于初学者来说,可以先从学习SQL语言的基础知识开始,了解SQL的基本语法和查询语句。
然后,可以逐渐深入学习Web应用程序的安全性知识,包括常见的Web漏洞类型和防范方法。
在学习Sqli-labs时,建议按照以下步骤进行:
- 了解Sqli-labs的基本概念和原理,包括SQL注入漏洞的定义、类型和影响等。
- 下载并安装Sqli-labs靶场环境,可以在虚拟机或云平台上进行搭建。
- 按照Sqli-labs提供的教程和示例进行学习和实践,了解如何识别和利用SQL注入漏洞,并学习如何修复和防范这些漏洞。
- 尝试自己编写SQL注入攻击代码,对Sqli-labs靶场中的漏洞进行攻击,并验证自己的攻击效果。
- 学习如何对Web应用程序进行安全性测试和评估,了解如何检测和修复SQL注入漏洞等常见的Web漏洞。
安装步骤
PHP和MySQL的环境可以通过PHPStudy安装。[PHPStudy官网](https://www.xp.cn/)
- Github官网下载安装并放在指定目录下(假如/var/www是你网站的本地地址文件夹)
- 或者,你可以在
/var/www文件夹中使用 git 命令。/var/www文件夹,然后使用以下命令git clone https://github.com/Audi-1/sqli-labs.git sqli-labs - 打开 sql-labs 文件夹内的 sql-connections 文件夹下的文件“
db-creds.inc”。 - 更新您的 MYSQL 数据库用户名和密码。(PHPStudy默认使用 root:toor)
- 从浏览器访问 sql-labs 文件夹以加载
index.html - 单击链接
setup/resetDB创建数据库、创建表并填充数据。 - 单击sqli labs页面中的课程编号可打开课程页面。
注入类型
- 基于错误的注入(Union Select)
- String
- Integer
- 基于错误的注入(基于双注入)
- 盲注:
- 基于布尔
- 基于时间
- 更新查询注入。
- 插入查询注入。
- Header 注入。
- 基于Referer
- 基于UserAgent
- 基于Cookie
- 二阶注入
一阶注入是指输入的注射语句对WEB直接产生了影响,出现了结果;
二阶注入类似存储型XSS,是指输入提交的语句,无法直接对WEB应用程序产生影响,通过其它的辅助间接的对WEB产生危害. - 绕过WAF
- 绕过黑名单过滤器
- 剥离注释
- 剥离 OR & AND
- 剥离空格和注释
- 剥离 UNION & SELECT
- 阻抗不匹配
- 绕过addslashes()
- 绕过 mysql_real_escape_string。 (特殊情况下)
- 堆叠式 SQL 注入。
- 二次通道提取
MySQL
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
Linux作为操作系统,Apache 或Nginx作为 Web 服务器,MySQL 作为数据库,PHP/Perl/Python作为服务器端脚本解释器。由于这四个软件都是免费或开放源码软件(FLOSS),因此使用这种方式不用花一分钱(除开人工成本)就可以建立起一个稳定、免费的网站系统,被业界称为“LAMP“或“LNMP”组合。
常用基本函数
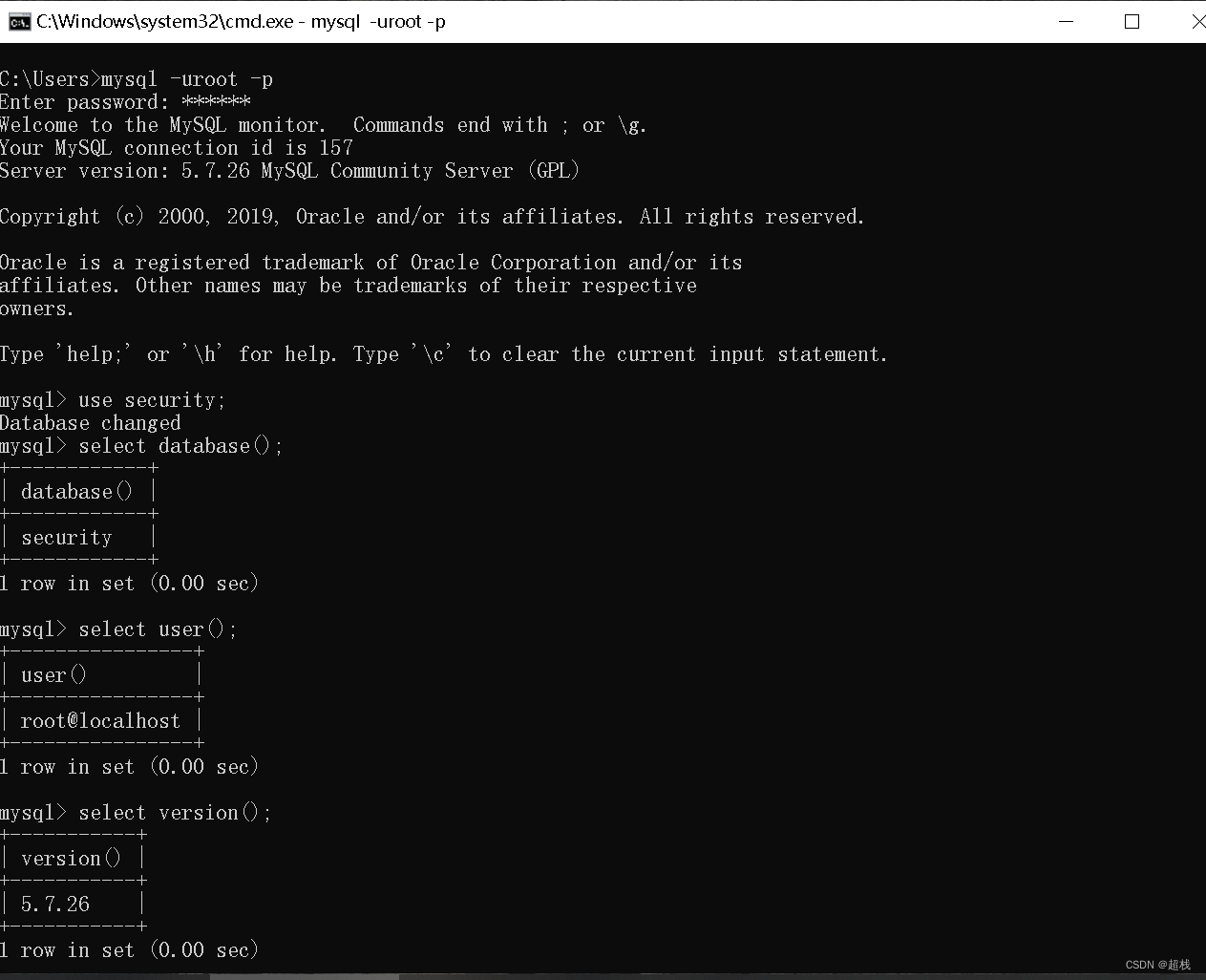
系统函数
USER()返回当前用户SESSION_USER()返回当前用户SYSTEM_USER()返回当前用户CURRENT_USER()返回当前用户VERSION()返回数据库的版本号DATABASE()返回当前数据库名BINARY(s)将字符串 s 转换为二进制字符串BIN(x)返回 x 的二进制编码
字符串函数
UPPER(s)将字符串转换为大写UCASE(s)将字符串转换为大写TRIM(s)去掉字符串 s 开始和结尾处的空格SUBSTR(s, start, length)从字符串 s 的 start 位置截取长度为 length 的子字符串SPACE(n)返回 n 个空格FIELD(s,s1,s2…)返回第一个字符串 s 在字符串列表(s1,s2…)中的位置CONCAT_WS(x, s1,s2…sn)同 CONCAT(s1,s2,…) 函数,但是每个字符串之间要加上 x,x 可以是分隔符CONCAT(s1,s2…sn)字符串 s1,s2 等多个字符串合并为一个字符串GROUP_CONCAT([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator ‘分隔符’])CHARACTER_LENGTH(s)返回字符串 s 的字符数CHAR_LENGTH(s)返回字符串 s 的字符数ASCII(s)返回字符串 s 的第一个字符的 ASCII 码。
数字函数
SUM(expression)返回指定字段的总和SQRT(x)返回x的平方根SIN(x)求正弦值(参数是弧度)SIGN(x)返回 x 的符号,x 是负数、0、正数分别返回 -1、0 和 1ROUND(x)返回离 x 最近的整数RAND()返回 0 到 1 的随机数POW(x,y)返回 x 的 y 次方COUNT(col)统计查询结果的行数FLOOR(x)返回小于或等于 x 的最大整数
or (select 1 from (select count(*),concat(0x7e,(),0x7e,floor(rand(0) * 2))x from information_schema.tables group by x)a)--+
报错注入函数
xpath函数
XPATH(XML Path Language)是一种用于在XML文档中定位元素和属性的语言。
XPATH可以通过路径表达式来选取XML文档中的节点。路径表达式可以是绝对的或相对的。绝对路径从根节点开始,而相对路径从当前节点开始。
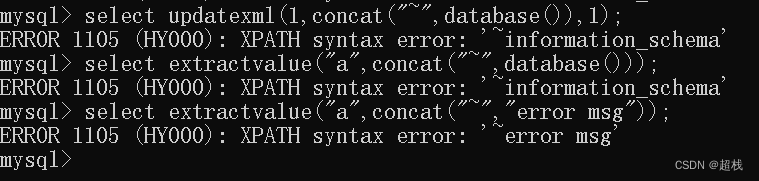
UPDATEXML (XML_document, XPath_string, new_value);返回与XPath表达式匹配的值。如果未找到匹配项,则返回空字符串。EXTRACTVALUE (XML_document, XPath_string);根据XPath表达式更新XML片段。
XPath_string即为注入点,插入~(ASCII码是0x7e)和^(ASCII码是0x5e)等特殊字符是非法的,也就会产生报错,而这些特殊字符也恰好是报错注入的关键点,
而当报错内容为SQL语句的时候,SQL那边的解析器会自动解析该SQL语句,就造成了SQL语句的任意执行。
GTID
GTID是MySQL数据库每次提交事务后生成的一个全局事务标识符,GTID不仅在本服务器上是唯一的,其在复制拓扑中也是唯一的。
GTID_SUBSET( set1 , set2 )若在 set1 中的 GTID,也在 set2 中,返回 true,否则返回 false ( set1 是 set2 的子集)GTID_SUBTRACT( set1 , set2 )返回在 set1 中,不在 set2 中的 GTID 集合 ( set1 与 set2 的差集)
GTID_SUBSET函数
') or gtid_subset(concat(0x7e,(SELECT GROUP_CONCAT(user,':',password) from manage),0x7e),1)--+') or gtid_subtract(concat(0x7e,(SELECT GROUP_CONCAT(user,':',password) from manage),0x7e),1)--+
ST
在MySQL数据库中,与空间数据相关的函数通常都以ST_(Spatial Type)为前缀。这些函数用于处理空间数据类型,如点(Point)、线(Line)、多边形(Polygon)等。
ST_前缀用于标识这些函数与空间数据相关。
ST_LatFromGeoHash从地理哈希值返回纬度
and ST_LatFromGeoHash(concat(0x7e,(),0x7e))--+ST_LongFromGeoHash从地理哈希值返回经度
and ST_LongFromGeoHash(concat(0x7e,(),0x7e))--+ST_Pointfromgeohash将地理哈希值转换为点值
or ST_PointFromGeoHash((),1)--+
系统信息
常用命令
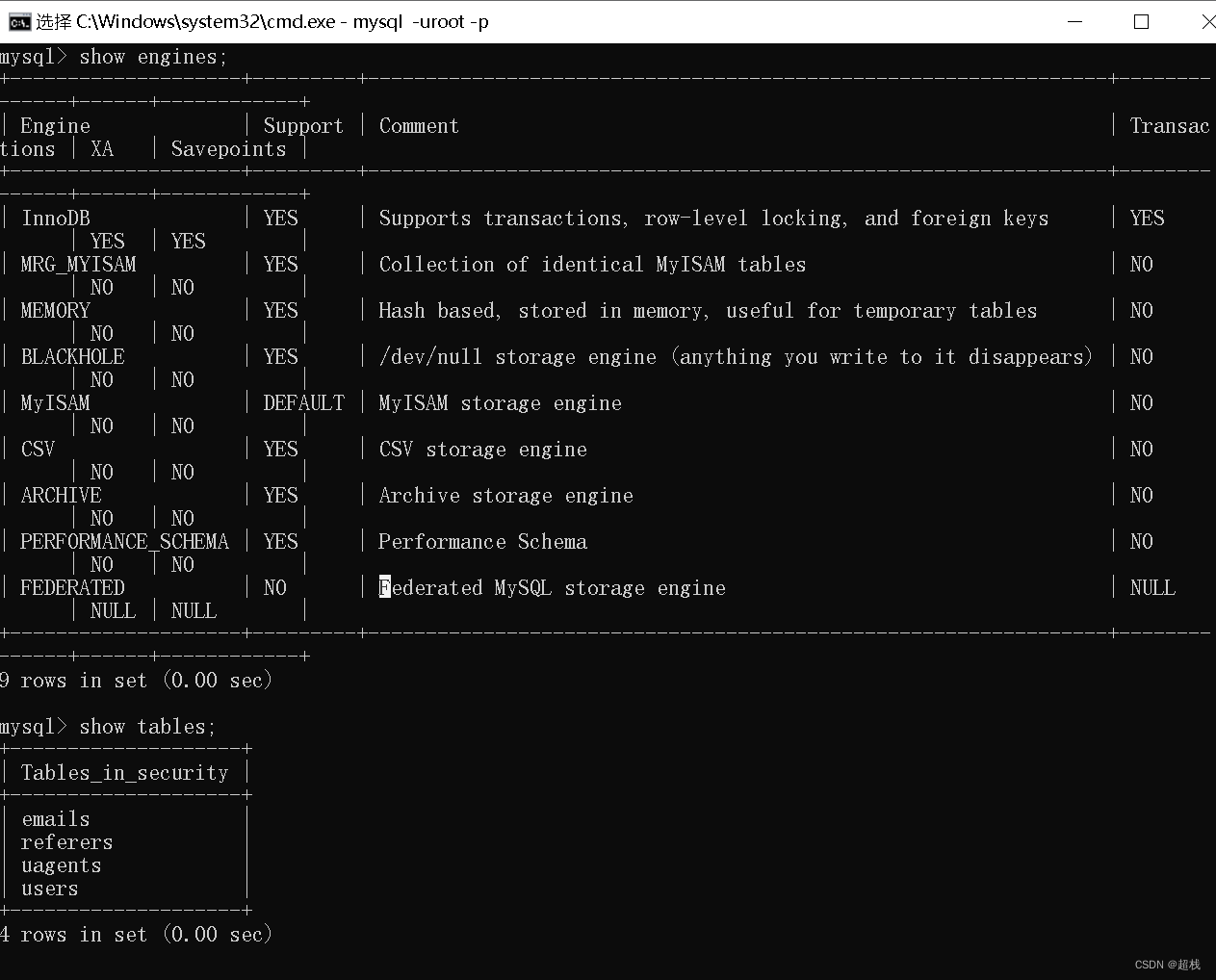
show tables或show tables from database_name; – 显示当前数据库中所有表的名称。show databases; – 显示mysql中所有数据库的名称。show columns from table_name from database_name; 或show columns from database_name.table_name; – 显示表中列名称。show grants for user_name; – 显示一个用户的权限,显示结果类似于grant 命令。show index from table_name; – 显示表的索引。show status; – 显示一些系统特定资源的信息,例如,正在运行的线程数量。show variables; – 显示系统变量的名称和值。show processlist; – 显示系统中正在运行的所有进程,也就是当前正在执行的查询。大多数用户可以查看他们自己的进程,但是如果他们拥有process权限,就可以查看所有人的进程,包括密码。show table status; – 显示当前使用或者指定的database中的每个表的信息。信息包括表类型和表的最新更新时间。show privileges; – 显示服务器所支持的不同权限。show create database database_name; – 显示create database 语句是否能够创建指定的数据库。show create table table_name; – 显示create database 语句是否能够创建指定的数据库。show engines; – 显示安装以后可用的存储引擎和默认引擎。show logs; – 显示BDB存储引擎的日志。show warnings; – 显示最后一个执行的语句所产生的错误、警告和通知。show errors; – 只显示最后一个执行语句所产生的错误。desc; – 获取数据表结构
注释
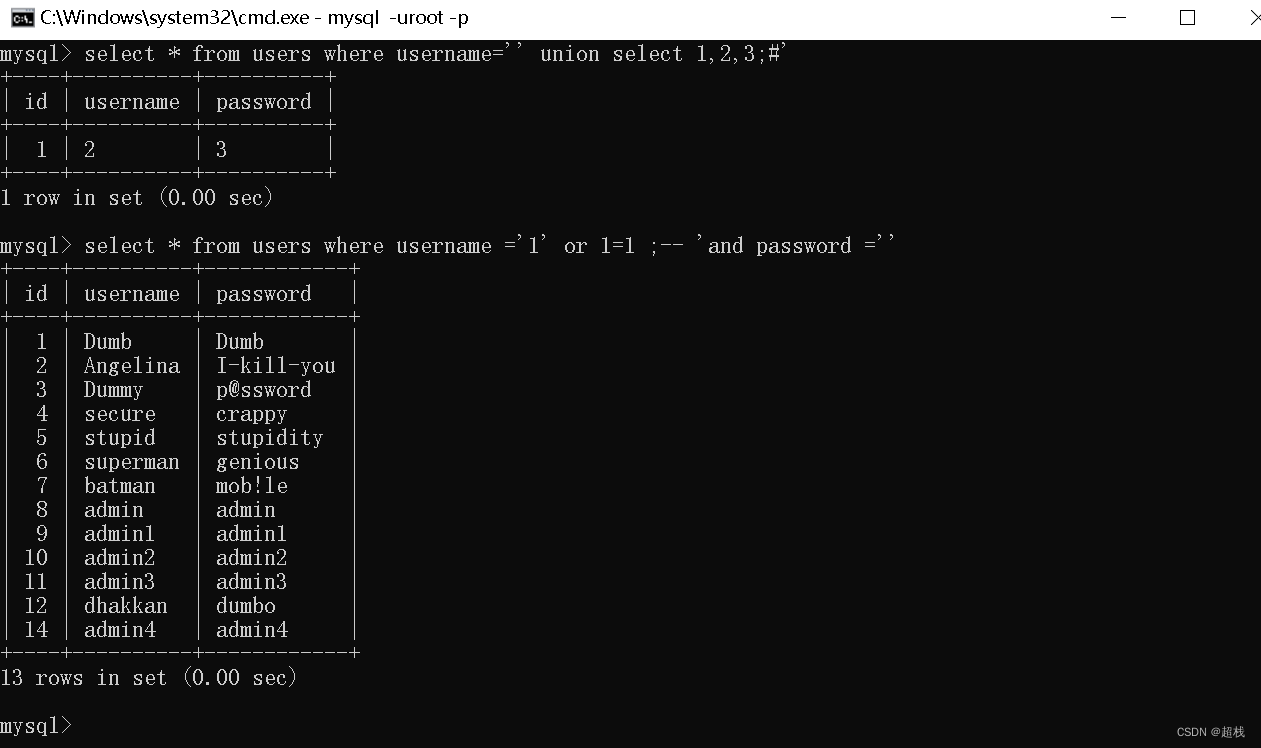
#Hash注释/*C语言风格注释--SQL语句注释;%00空字节`反引号(只能在语句尾使用)
数据库元数据
information_schema 顾名思义就是一个信息库,是用来存储数据库的元数据(比如数据库,表的名称,列的数据类型、访问权限等),
在每个 MySQL 实例中,information_schema 保存了它维护的所有数据库的信息,这个库中包含了很多只读的表。
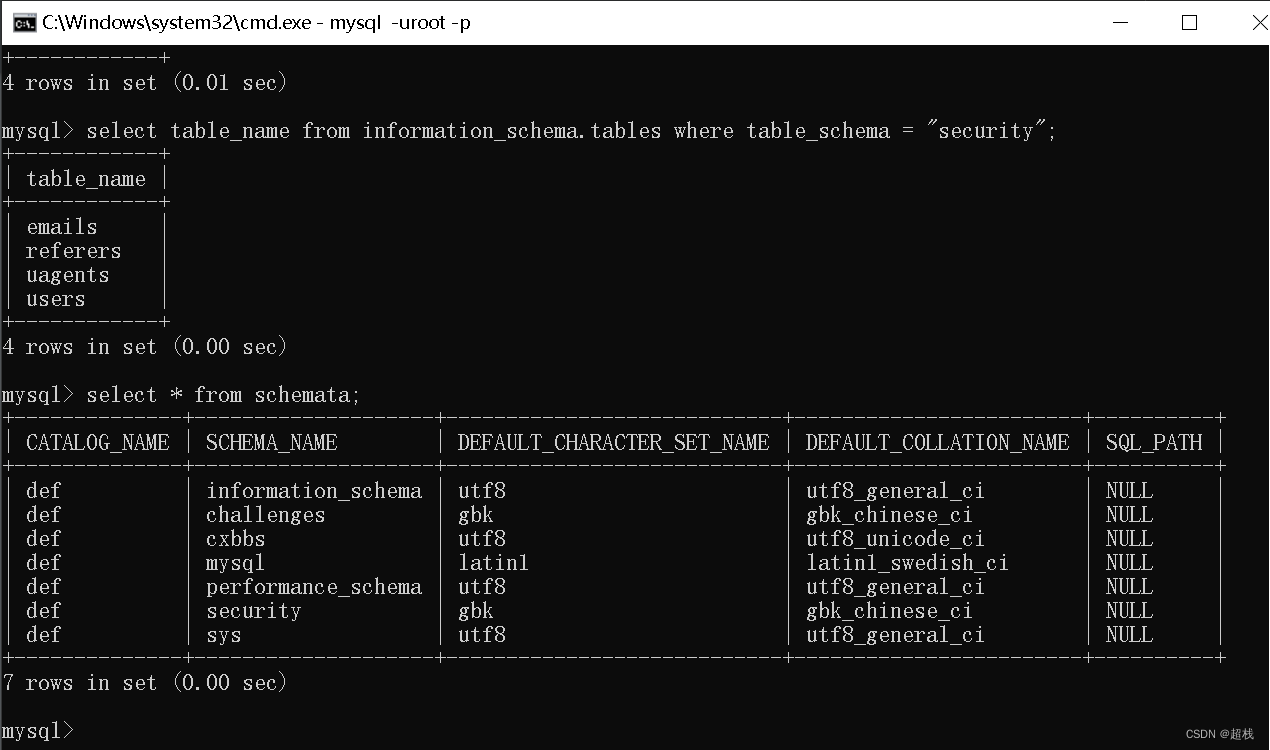
information_schema数据库
- schmata表:存放了所有的库名,存放在此表中 schema_name 字段中
- tables 表:存放了所有的表名, table_chema库名 以及对应的 table_name表名
- columns表:存放了所有的字段,table_schema库名,table_name表名,column_name字段名
MySQL自带的mysql数据库是存储用户和权限相关信息的重要数据库。
MySQL数据库
- innodb_table_stats 存储关于所有InnoDB引擎表的统计数据
- innodb_table_index 记录了所有InnoDB表的索引信息
Sys库所有的数据源来自:performance_schema。目标是把performance_schema的把复杂度降低
Sys数据库
- 字母开头: 适合人阅读,显示是格式化的数
- schema_auto_increment_columns 对表自增ID的监控
- schema_table_statistics_with_buffer 一个视图总结了表的统计信息,包括InnoDB缓冲池统计信息。
- x$开头 : 适合工具采集数据,原始类数据
- x$schema_table_statistics_with_buffer
- x$ps_schema_table_statistics_io
数据库信息
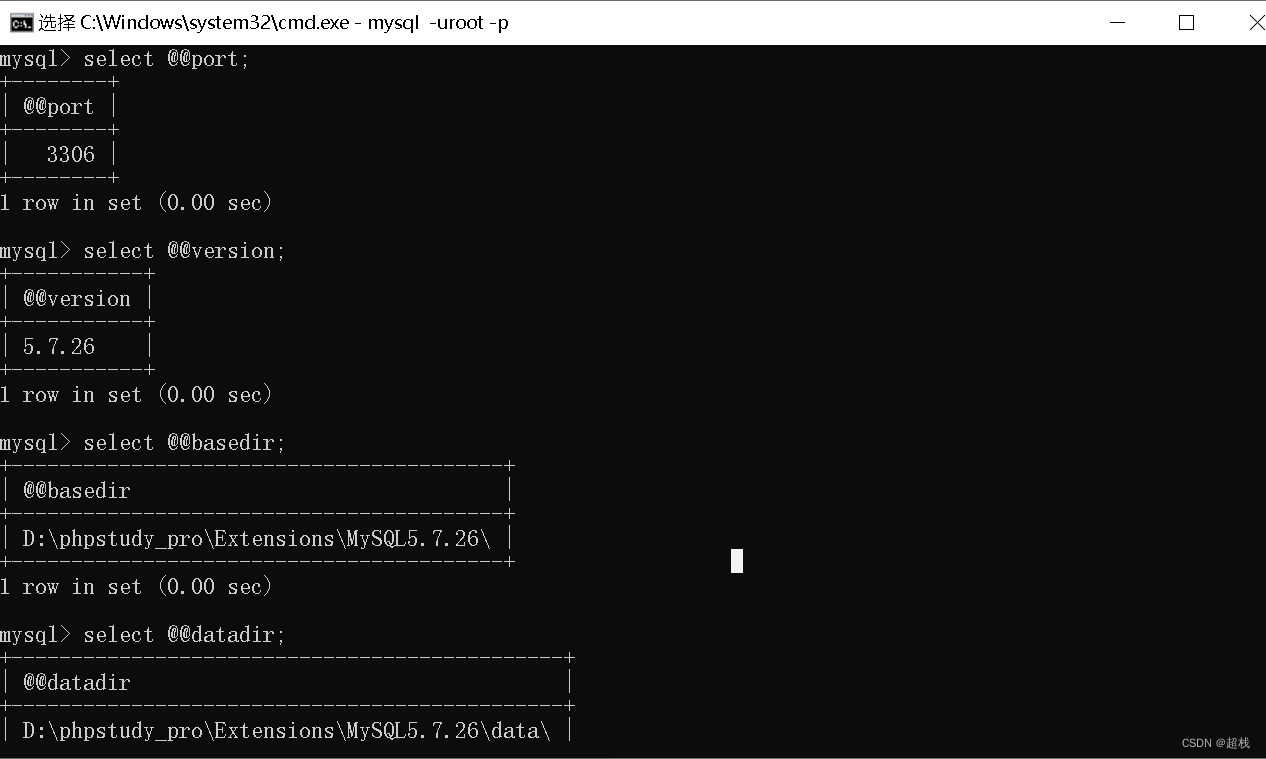
SELECT @@port;输出当前数据库端口号SELECT @@version;输出当前数据库版本号SELECT @@basedir;输出该服务器数据库安装路径SELECT @@datadir;输出数据库中数据的存放路径SELECT @@server_id;输出数据库标识(一般为IP)SELECT @@version_compile_os输出操作系统的版本号SELECT @@innodb_flush_log_at_trx_commit;事务提交刷新时机
SHOW VARIABLES LIKE 'innodb_flush%'如记不住也可使用模糊查询
这篇关于sqli-labs 靶场闯关基础准备、学习步骤、SQL注入类型,常用基本函数、获取数据库元数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









