本文主要是介绍论文精读--Swin Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
想让ViT像CNN一样分成几个block,做层级式的特征提取,从而使提取出的特征有多尺度的概念
Abstract
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection.This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO testdev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-theart by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures. The code and models are publicly available at https://github.com/microsoft/Swin-Transformer.
翻译:
本文提出了一种新的视觉Transformer,称为Swin Transformer,可以作为通用的计算机视觉主干网络。从语言到视觉领域中,适应Transformer面临的挑战主要源自两个领域之间的差异,例如视觉实体的尺度变化较大,以及图像像素的高分辨率相对于文本中的单词。为了应对这些差异,我们提出了一种分层Transformer,其表示通过Shifted窗口计算。Shifted窗口方案通过将自注意力计算限制在不重叠的局部窗口内,同时允许跨窗口连接,从而提高了效率。这种分层架构具有在不同尺度上建模的灵活性,并且对图像大小具有线性计算复杂度。Swin Transformer的这些特性使其能够适用于广泛的视觉任务,包括图像分类(在ImageNet-1K上达到87.3的top-1准确率)和密集预测任务,如目标检测(在COCO testdev上达到58.7的box AP和51.1的mask AP)和语义分割(在ADE20K val上达到53.5的mIoU)。其性能大幅超越了之前的最先进水平,在COCO上分别提高了2.7的box AP和2.6的mask AP,在ADE20K上提高了3.2的mIoU,展示了基于Transformer的模型作为视觉主干网络的潜力。分层设计和Shifted窗口方法对于全MLP架构也有益。代码和模型已公开发布在:https://github.com/microsoft/Swin-Transformer。
总结:
ViT只是证明了视觉可以有自己的transformer,没有证明可以作为骨干网络用于所有的图像任务
从nlp到cv的挑战主要有两方面,其中一个是尺度上的问题,nlp中都是单词,而cv中不同物体的尺度不同,如果用像素点作为基本单位则序列长度不可控,因此之前的工作要么把特征图输入transformer,要么把图片打成patch输入transformer,本质上都是为了减少序列的影响。
作者通过移动窗口的方法解决序列长度问题
Introduction
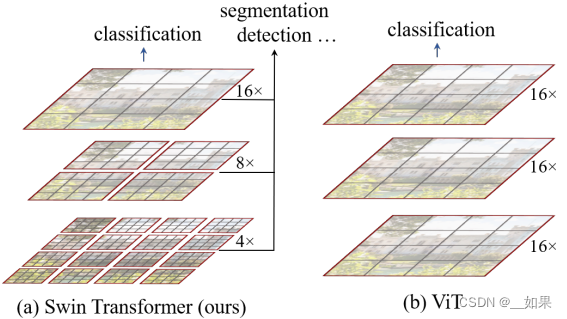
对于很多视觉任务,多尺度是非常重要的,右边的VIT始终只有patch这一个尺度
Swin Transformer在小窗口算自注意力而不是整图上,计算复杂度与图片大小成线性增长关系,而ViT则是平方关系
窗口也能捕捉附近其他窗口的连续信息,是够用的,全局建模有可能会浪费资源
CNN有多尺度特征是因为pooling增大每个卷积核的感受野,所以在这里提出patch merging,把相邻的小patch合成一个大patch
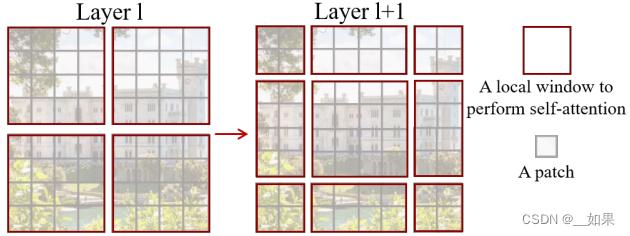
红色是窗口,灰色是4x4的小patch
shift操作:把整个特征图整体向右下角移动2个patch,移动使得窗口可以看见更多patch的信息
Method
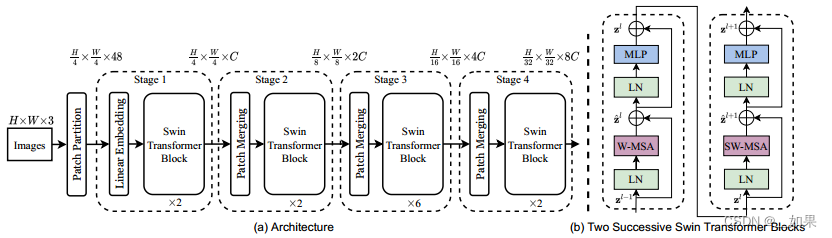
(1)图片打patch,大小4x4
(2)linear embedding把向量维度变成预设好的值,维度是超参数C
(3)因为patch小,所以序列长,transformer接受不了,因此通过swin变成窗口并做自注意力,每个窗口7x7=49个patch,所以序列长度变成49
(4)block堆叠,加一个patch merging操作获得多尺度信息,patch merging将每隔一个的patch放入同一新窗口,按照通道合并,最后用1x1卷积调整通道大小,保证每次维度翻倍
(5)如果要做分类,则在最后加一个全局池化;而ViT使用了cls token

先做一次窗口的自注意力,再做一次移动窗口的多头自注意力
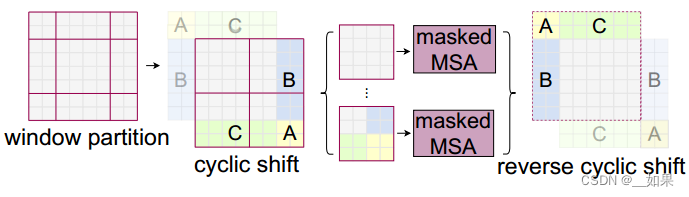
向右下角移动实现移动窗口的方法不好,增加了窗口数量
作者提出一种掩码方式:当往右下角移动得到9个窗口时,再做一次循环移位,也就是把左上角被移走的部分拼回右下角,但此时破坏了像素之间的相邻信息,因此把不合适做自注意力的地方mask掉,最后把移动部分拼回左上角还原语义
mask通过矩阵加法实现,加一个合适的负数和0
Conclusion
This paper presents Swin Transformer, a new vision Transformer which produces a hierarchical feature representation and has linear computational complexity with respect to input image size. Swin Transformer achieves the state-of-the-art performance on COCO object detection and ADE20K semantic segmentation, significantly surpassing previous best methods. We hope that Swin Transformer’s strong performance on various vision problems will encourage unified modeling of vision and language signals.
As a key element of Swin Transformer, the shifted window based self-attention is shown to be effective and efficient on vision problems, and we look forward to investigating its use in natural language processing as well.
翻译:
本文提出了Swin Transformer,这是一种新的视觉Transformer,它生成分层特征表示,并且相对于输入图像大小具有线性计算复杂度。Swin Transformer在COCO目标检测和ADE20K语义分割任务上实现了最先进的性能,显著超过了之前的最佳方法。我们希望Swin Transformer在各种视觉问题上的强大性能能够促进视觉和语言信号的统一建模。
作为Swin Transformer的关键要素,基于Shifted窗口的自注意力在视觉问题上被证明是有效且高效的,我们期待着进一步研究其在自然语言处理中的应用。
这篇关于论文精读--Swin Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

