本文主要是介绍yolov8使用:数据格式转换(目标检测、图像分类)多目标跟踪,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
安装
yolov8地址:https://github.com/ultralytics/ultralytics
git clone https://github.com/ultralytics/ultralytics.git
安装环境:
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
目标检测
标注格式转换
若使用 labelimg 做为标注工具时:
VOC标注输出的是xml格式的标注文件

需要将xml文件转txt文件,yolo才能训练
标签格式转换xml转txt:https://blog.csdn.net/qq_42102546/article/details/125303080
YOLO标注输出的是txt格式的标注文件,可直接用于训练。

输出的是json标注文件(注意是这样的json;[{“image”: “zha1_1478.jpg”, “annotations”: [{“label”: “w”, “coordinates”: {“x”: 290.0, “y”: 337.0, “width”: 184.0, “height”: 122.0}}]}])
不要使用这个

若使用 labelme 作为标注工具,输出文件为:json格式
转换代码如下:json转txt
import json
import osdef convert(img_size, box):dw = 1. / (img_size[0])dh = 1. / (img_size[1])x = (box[0] + box[2]) / 2.0 - 1y = (box[1] + box[3]) / 2.0 - 1w = box[2] - box[0]h = box[3] - box[1]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def decode_json(json_floder_path, json_name):global path# 转换好txt的标签路径txt_name = path + json_name[0:-5] + '.txt'txt_file = open(txt_name, 'w')json_path = os.path.join(json_floder_path, json_name)data = json.load(open(json_path, 'r', encoding='gb2312'))print(data)img_w = data['imageWidth']img_h = data['imageHeight']for i in data['shapes']:label_name = i['label']if (i['shape_type'] == 'rectangle'):x1 = int(i['points'][0][0])y1 = int(i['points'][0][1])x2 = int(i['points'][1][0])y2 = int(i['points'][1][1])bb = (x1, y1, x2, y2)bbox = convert((img_w, img_h), bb)txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')if __name__ == "__main__":# 使用labelme标注后生成的 json 转 txt# 原始json标签路径json_floder_path = 'D:\\yolo_\\mu_biao_gen_zong\\data2\\'# 目标txt 保存路径path = 'D:\\yolo_\\mu_biao_gen_zong\\d\\'# 类别name2id = {'w': 0, 'f': 1} # 具体自己数据集类别json_names = os.listdir(json_floder_path)print(json_names)for json_name in json_names:decode_json(json_floder_path, json_name)数据集划分(目标检测)
暂无
训练代码
from ultralytics import YOLO# Load a model
# model = YOLO("yolov8n.yaml") # build a new model from YAML
# 目标检测
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# 图像分类
# model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# model = YOLO("dataset.yaml").load("yolov8n.pt") # build from YAML and transfer weights# Train the model
results = model.train(data="dataset.yaml", epochs=40, imgsz=640) # 40次 输入图像缩放大小640
# results = model.train(data="D:/yolo_/mu_biao_gen_zong/data", epochs=40, imgsz=640)dataset.yaml 文件内容
数据集根目录
训练集目录
测试集目录
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/yolo_/mu_biao_gen_zong/data # dataset root dir,数据集根目录,使用绝对路径
train: D:/yolo_/mu_biao_gen_zong/data/train # train images (relative to 'path') ,训练集图片目录(相对于path)
val: D:/yolo_/mu_biao_gen_zong/data/val # val images (relative to 'path') ,测试集图片目录(相对于path)
test: # test images (optional# Classes,类别
names:0: roses1: sunflowers
推理代码
读取目录下的所有图像进行推理绘制矩形并保存在另一个目录中
from ultralytics import YOLO
import numpy as np
import cv2
import os
import timedef cv_show(neme, img):cv2.imshow(neme, img)cv2.waitKey(0)cv2.destroyAllWindows()# Load a model
model = YOLO('best.pt') # pretrained YOLOv8n modelpath_r = "./save_jpg/"
path_s = "./save_jpg_1/"
jpg_list = os.listdir(path_r)
for jpg_name in jpg_list:path_jpg_name = path_r + jpg_name# results = model('./save_jpg/1712411336861392961.jpg') # return a list of Results objectsresults = model(path_jpg_name)print(type(results))print(len(results))for result in results:boxes = result.boxes # Boxes object for bounding box outputs# print(type(result.orig_img))for i in range(len(boxes)):boxes = boxes.cpu()x1 = int(np.array(boxes[i].xyxy)[0][0])y1 = int(np.array(boxes[i].xyxy)[0][1])x2 = int(np.array(boxes[i].xyxy)[0][2])y2 = int(np.array(boxes[i].xyxy)[0][3])print(x1, y1, x2, y2)# 绘制矩形cv2.rectangle(result.orig_img, (x1, y1), (x2, y2), (0, 255, 0), 3)#cv_show("neme", result.orig_img)path_name_save = path_s + str(time.time()) + ".jpg"cv2.imwrite(path_name_save,result.orig_img)# masks = result.masks # Masks object for segmentation masks outputs# keypoints = result.keypoints # Keypoints object for pose outputs# probs = result.probs # Probs object for classification outputs# print(probs)#result.show() # display to screen#result.save(filename='result.jpg') # save to disk图像分类
数据集划分(图像分类)
分类图像数据集划分
默认总文件夹下 data_name 里面是具体分类的类别。
例如:
data_name
└──Cat 该文件夹里面是对应类型的图像
└──Dog 该文件夹里面是对应类型的图像
import argparse
import os
from shutil import copy
import randomdef mkfile(file):if not os.path.exists(file):os.makedirs(file)# './data_name'
def data_list(path, percentage, name):# 获取data文件夹下所有文件夹名(即需要分类的类名)file_path = pathflower_class = [cla for cla in os.listdir(file_path)]# # 创建 训练集train 文件夹,并由类名在其目录下创建5个子目录pwd2 = name + "/train"mkfile(name)for cla in flower_class:mkfile(pwd2 + "/" + cla)# 创建 验证集val 文件夹,并由类名在其目录下创建子目录pwd3 = name + "/val"mkfile(name)for cla in flower_class:mkfile(pwd3 + "/" + cla)# 划分比例,训练集 : 验证集 = 9 : 1split_rate = percentage# 遍历所有类别的全部图像并按比例分成训练集和验证集for cla in flower_class:cla_path = file_path + '/' + cla + '/' # 某一类别的子目录images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称num = len(images)eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称for index, image in enumerate(images):# eval_index 中保存验证集val的图像名称if image in eval_index:image_path = cla_path + imagenew_path = pwd3 + "/" + clacopy(image_path, new_path) # 将选中的图像复制到新路径# 其余的图像保存在训练集train中else:image_path = cla_path + imagenew_path = pwd2 + "/" + clacopy(image_path, new_path)print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing barprint()print("processing done!")if __name__ == '__main__':parser = argparse.ArgumentParser(description="开始分离\"训练集\"与\"测试集\"百分比,""默认读取同级目录文件名:data_name,""默认训练集80%,测试集20%""默认保存文件名:data""train-->训练集""val -->测试集")parser.add_argument('--path', type=str, default="./data_name", help='输入目标文件的路径')parser.add_argument('--percentage', type=float, default=0.2, help='指定测试集比例,例如:"0.2",训练集80%,测试集20%')parser.add_argument('--name', type=str, default="./data", help='另存为命名')args = parser.parse_args()path, percentage, name = args.path, args.percentage, args.namedata_list(path, percentage, name)训练代码
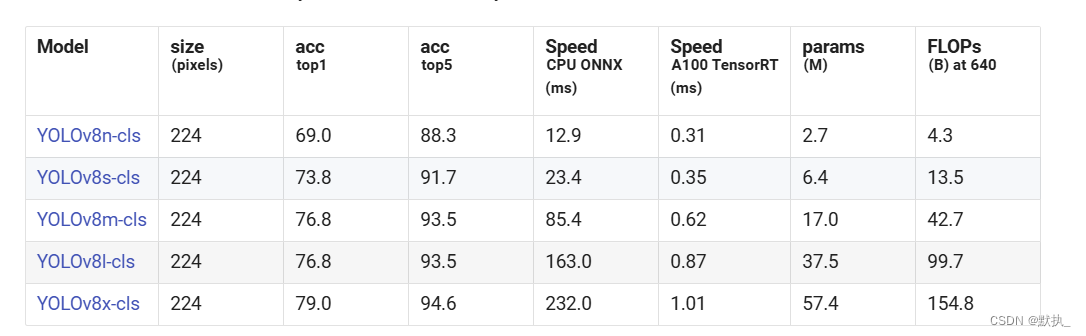
使用不同的预训练权重,直接运行默认下载。
from ultralytics import YOLO# Load a model
# model = YOLO("yolov8n.yaml") # build a new model from YAML
# 目标检测
# model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# 图像分类
model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# model = YOLO("dataset.yaml").load("yolov8n.pt") # build from YAML and transfer weights# Train the model
# results = model.train(data="dataset.yaml", epochs=40, imgsz=640) # 40次 输入图像缩放大小640
results = model.train(data="D:/yolo_/mu_biao_gen_zong/data", epochs=40, imgsz=640)推理代码
from ultralytics import YOLO# Load a model
model = YOLO("best.pt") # pretrained YOLOv8n model# Run batched inference on a list of images
results = model(["im1.jpg", "im2.jpg"]) # return a list of Results objects# Process results list
for result in results:# boxes = result.boxes # 目标检测masks = result.masks # 分割keypoints = result.keypoints # 姿态检测probs = result.probs # 分类obb = result.obb # Oriented boxes object for OBB outputsprint("分类")print(dir(probs))print(probs.top1)# result.show() # 显示# result.save(filename="result.jpg") # save to disk多目标跟踪
yolov8自带调用
多目标跟踪官方文档:https://docs.ultralytics.com/zh/modes/track/
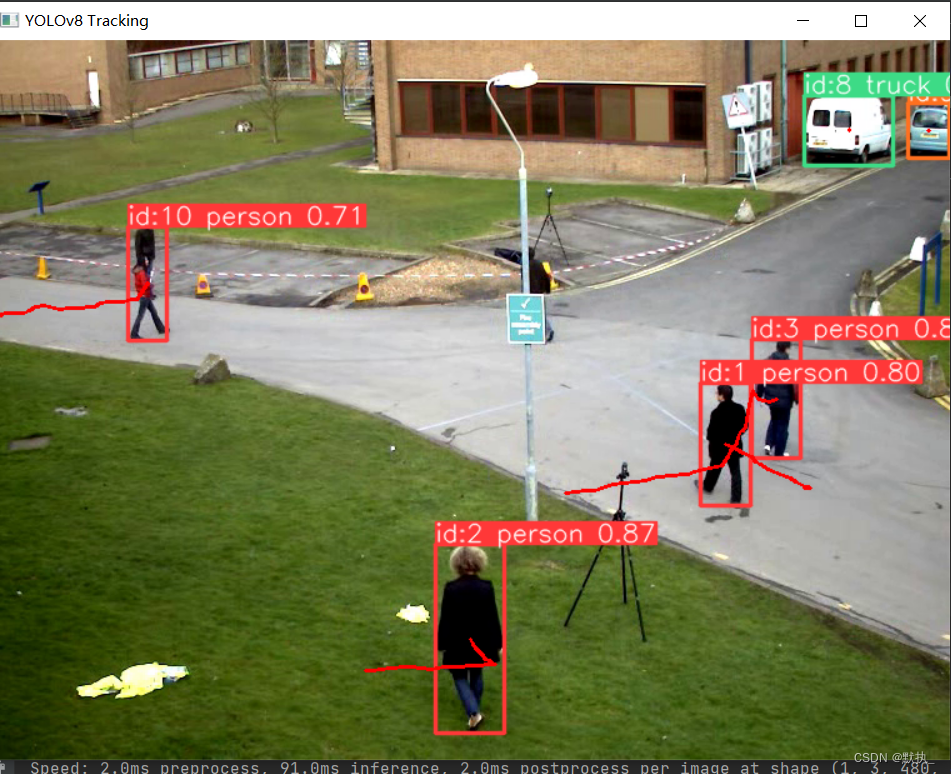
from collections import defaultdict
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import cv2
import numpy as npfrom ultralytics import YOLO# Load the YOLOv8 model
model = YOLO('weights/yolov8n.pt')# Open the video file
video_path = "./data0/testvideo1.mp4"
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
size = (width, height)# Store the track history
track_history = defaultdict(lambda: [])# Loop through the video frames
while cap.isOpened():# Read a frame from the videosuccess, frame = cap.read()if success:# Run YOLOv8 tracking on the frame, persisting tracks between framesresults = model.track(frame, persist=True)# Get the boxes and track IDsif results[0].boxes.id != None:boxes = results[0].boxes.xywh.cpu()track_ids = results[0].boxes.id.int().cpu().tolist()# Visualize the results on the frameannotated_frame = results[0].plot()# Plot the tracksfor box, track_id in zip(boxes, track_ids):x, y, w, h = boxtrack = track_history[track_id]track.append((float(x), float(y))) # x, y center pointif len(track) > 30: # retain 90 tracks for 90 framestrack.pop(0)# Draw the tracking linespoints = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))cv2.polylines(annotated_frame, [points], isClosed=False, color=(0, 0, 255), thickness=2)# Display the annotated framecv2.imshow("YOLOv8 Tracking", annotated_frame)# videoWriter.write(annotated_frame)# Break the loop if 'q' is pressedif cv2.waitKey(1) & 0xFF == ord("q"):breakelse:# Break the loop if the end of the video is reachedbreak# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()这篇关于yolov8使用:数据格式转换(目标检测、图像分类)多目标跟踪的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




