本文主要是介绍YOLOv8改进(一)-- 轻量化模型ShuffleNetV2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、前言
- 2、ShuffleNetV2代码实现
- 2.1、创建ShuffleNet类
- 2.2、修改tasks.py
- 2.3、创建shufflenetv2.yaml文件
- 2.4、跑通示例
- 3、碰到的问题
- 4、目标检测系列文章
1、前言
移动端设备也需要既准确又快的小模型。为了满足这些需求,一些轻量级的CNN网络如MobileNet和ShuffleNet被提出,它们在速度和准确度之间做了很好地平衡。ShuffleNetv2是旷视2018年提出的ShuffleNet升级版本,并被ECCV2018收录。
当然也可以修改YOLOv5模型,具体参考= = = = =>YOLOv5改进(四)–轻量化模型ShuffleNetv2
2、ShuffleNetV2代码实现
2.1、创建ShuffleNet类
在ultralytics/nn文件夹中新建ShuffleNet.py文件
import torch
import torch.nn as nnclass Conv_maxpool(nn.Module):def __init__(self, c1, c2): # ch_in, ch_outsuper().__init__()self.conv= nn.Sequential(nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(c2),nn.ReLU(inplace=True),)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)def forward(self, x):return self.maxpool(self.conv(x))class ShuffleNetV2(nn.Module):def __init__(self, inp, oup, stride): # ch_in, ch_out, stridesuper().__init__()self.stride = stridebranch_features = oup // 2assert (self.stride != 1) or (inp == branch_features << 1)if self.stride == 2:# copy inputself.branch1 = nn.Sequential(nn.Conv2d(inp, inp, kernel_size=3, stride=self.stride, padding=1, groups=inp),nn.BatchNorm2d(inp),nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),nn.BatchNorm2d(branch_features),nn.ReLU(inplace=True))else:self.branch1 = nn.Sequential()self.branch2 = nn.Sequential(nn.Conv2d(inp if (self.stride == 2) else branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),nn.BatchNorm2d(branch_features),nn.ReLU(inplace=True),nn.Conv2d(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1, groups=branch_features),nn.BatchNorm2d(branch_features),nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),nn.BatchNorm2d(branch_features),nn.ReLU(inplace=True),)def forward(self, x):if self.stride == 1:x1, x2 = x.chunk(2, dim=1)out = torch.cat((x1, self.branch2(x2)), dim=1)else:out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)out = self.channel_shuffle(out, 2)return outdef channel_shuffle(self, x, groups):N, C, H, W = x.size()out = x.view(N, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous().view(N, C, H, W)return out
2.2、修改tasks.py
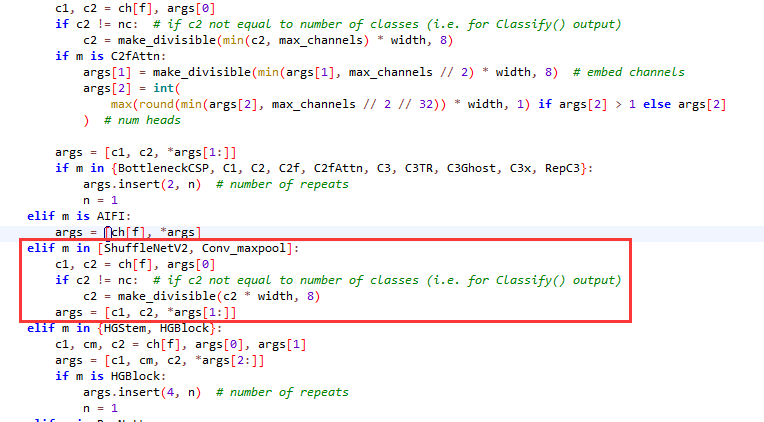
修改ultralytics/nn/tasks.py的 parse_model()函数:添加以下代码
elif m in [ShuffleNetV2, Conv_maxpool]:c1, c2 = ch[f], args[0]if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)c2 = make_divisible(c2 * width, 8)args = [c1, c2, *args[1:]]
2.3、创建shufflenetv2.yaml文件
在ultralytics/yolo/cfg目录下创建shufflenetv2.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license# Parameters
nc: 6 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.50 # scales convolution channels# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv_maxpool, [24]] # 0-P2/4- [-1, 1, ShuffleNetV2, [116, 2]] # 1-P3/8- [-1, 3, ShuffleNetV2, [116, 1]] # 2- [-1, 1, ShuffleNetV2, [232, 2]] # 3-P4/16- [-1, 7, ShuffleNetV2, [232, 1]] # 4- [-1, 1, ShuffleNetV2, [464, 2]] # 5-P5/32- [-1, 3, ShuffleNetV2, [464, 1]] # 6- [-1, 1, SPPF, [1024, 5]] # 7# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 10- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 2], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 13 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 7], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[13, 16, 19], 1, Detect, [nc]] # Detect(P3, P4, P5)
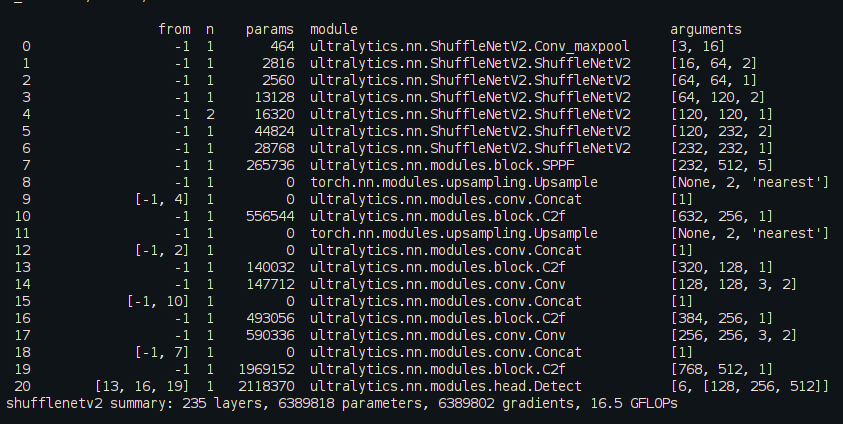
2.4、跑通示例
核查是否修改成功,见下图,至此全部修改成功。
3、碰到的问题
File “/public/home/miniconda/envs/yolov8/lib/python3.8/site-packages/ultralytics/nn/tasks.py”, line 855, in parse_model
m = getattr(torch.nn, m[3:]) if “nn.” in m else globals()[m] # get module KeyError: ‘Conv_maxpool’
说明你没有真正修改tasks.py文件,需要你重新将2、ShuffleNetV2代码实现重新弄一遍,注意本次要来到 /public/home/miniconda/envs/yolov8/lib/python3.8/site-packages/ultralytics/nn 创建 ShuffleNet.py文件和修改task.py文件
4、目标检测系列文章
- YOLOv5s网络模型讲解(一看就会)
- 生活垃圾数据集(YOLO版)
- YOLOv5如何训练自己的数据集
- 双向控制舵机(树莓派版)
- 树莓派部署YOLOv5目标检测(详细篇)
- YOLO_Tracking 实践 (环境搭建 & 案例测试)
- 目标检测:数据集划分 & XML数据集转YOLO标签
- DeepSort行人车辆识别系统(实现目标检测+跟踪+统计)
- YOLOv5参数大全(parse_opt篇)
- YOLOv5改进(一)-- 轻量化YOLOv5s模型
- YOLOv5改进(二)-- 目标检测优化点(添加小目标头检测)
- YOLOv5改进(三)-- 引进Focaler-IoU损失函数
- YOLOv5改进(四)–轻量化模型ShuffleNetv2
- YOLOv5改进(五)-- 轻量化模型MobileNetv3
- YOLOv5改进(六)–引入YOLOv8中C2F模块
这篇关于YOLOv8改进(一)-- 轻量化模型ShuffleNetV2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








