本文主要是介绍数据结构严蔚敏版精简版-绪论,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.基本概念和术语
下列概念和术语将在以后各章节中多次出现,本节先对这些概念和术语赋予确定的含义。
数据(Data):数据是客观事物的符号表示,是所有能输入到计算机中并被计算机程序处理的符号 的总称。
数据元素(DataElement):数据元素是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。 在有些情况下,数据元素也称为元素、记录等。
数据项(DataItem):数据项是组成数据元素的、有独立含义的、不可分割的最小单位。例如,学生 基本信息表中的学号、姓名、性别等都是数据项。
数据对象(DataObject):数据对象是性质相同的数据元素的集合,是数据的一个子集。
2.数据结构
数据结构 (Data Structure) 是相互之间存在一种或多种特定关系的数据元素的集合。
数据结构包括逻辑结构和存储结构两个层次。
2.1数据的逻辑结构
从逻辑关系上描述数据,它与数据的存储无关,是独立千计算机的。
通常有四类基本结构,从逻辑结构上分为线性和非线性
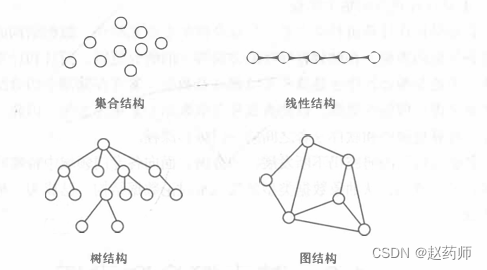
逻辑结构可以用一个层次图描述
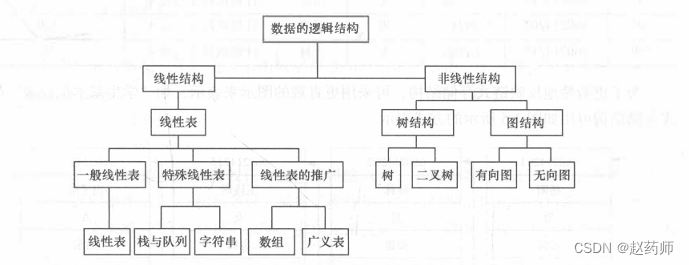
2.2数据的存储结构
数据对象在计算机中的存储表示称为数据的存储结构,也称为物理结构。数据元素在计算机中有两种基本的存储结构,分别是顺序存储结构和链式存储结构。
四大存储结构:顺序存储结构、链接存储结构、索引存储结构和散列存储结构
举例:如链、哈希(散列)、顺序、索引等关键字的一般是存储结构。
3.算法评估
算法 (Algorithm) 是为了解决某类问题而规定的一个有限长的操作序列。
3.1算法五个重要特性
(1)有穷性。一个算法必须总是在执行有穷步后结束,且每一步都必须在有穷时间内完成。
(2) 确定性。对千每种情况下所应执行的操作,在算法中都有确切的规定,不会产生二义性, 使算法的执行者或阅读者都能明确其含义及如何执行。
(3) 可行性。算法中的所有操作都可以通过已经实现的基本操作运算执行有限次来实现。
(4) 输入。一个算法有零个或多个输入。
(5) 输出。一个算法有一个或多个输出,无输出的 算法没有任何意义。
3.2评价算法优劣的基本标准
一个算法的优劣应该从以下几方面来评价。
(1)正确性。在合理的数据输入下,能够在有限的运行时间内得到正确的结果。
(2)可读性。一个好的算法,首先应便千人们理解和相互交流, 其次才是机器可执行性。可 读性强的算法有助于人们对算法的理解,而难懂的算法易千隐藏错误,且难千调试和修改。
(3)健壮性。当输入的数据非法时,好的算法能适当地做出正确反应或进行相应处理,而不 会产生一些莫名其妙的输出结果。
(4)高效性。高效性包括时间和空间两个方面。时间 可以用时间复杂度来度量;空间可以用空间复杂度来度量。时间复杂度和空间复杂度是衡量算法的两个主要指标。
通常只讨论算法在最坏情况下的时间复杂度,即分析在最坏情况下,算法执行时间的上界。
若算法执行时所需要的辅助空间相对千输入数据量而言是个常数,则称这个算法为原地工作,辅助 空间为0(1),
这篇关于数据结构严蔚敏版精简版-绪论的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







