本文主要是介绍空间转录组基础数据解读+学习方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
详情请参考这个视频:空间转录组(spatial transcriptome)数据分析基础教程_哔哩哔哩_bilibili
1.首先是filtered_feature_bc_matrix文件
两个里面的内容本质一样,都是空间转录组 表达矩阵的信息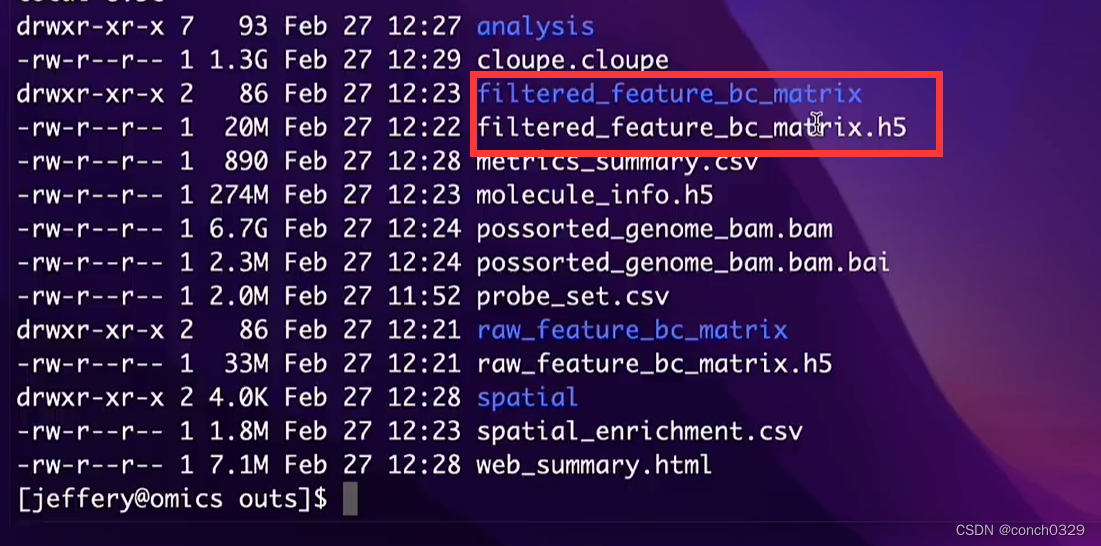
2.具体的所有东西可以在10x的网站里学,看参数
具体的网址:Cell Ranger Gene Expression Outputs - Official 10x Genomics Support
可以在这个里面进行学习。
3.具体讲一下spatial的数据还有adata中的uns中的spatial数据和obsm中的spatial数据吧!
本质是一样的,但是明显可以看到adata中的spatial数据比spatial文件夹中的数据少?因为质控等一些原因
spatial 中有 4 千多的数据,但是在 filtered_feature_bc_matrix.h5 中的 obs 中只有 3 千多的数据,可能是因为在数据处理过程中进行了质量控制和过滤,去除了低质量细胞、空白滴、非目标区域的细胞等。这是单细胞 RNA 测序和空间转录组学数据处理中常见的步骤,目的是提高数据的可靠性和准确性。

根据要求调整
import scanpy as sc# 加载原始spatial数据
input_dir = ("E:/Lung/Lung/A1/outs")
adata = sc.read_visium(path=input_dir, count_file='raw_feature_bc_matrix.h5')
# adata_spatial = sc.read_visium("path_to_visium_data")# 加载过滤后的数据
adata_filtered = sc.read_visium(path=input_dir, count_file='filtered_feature_bc_matrix.h5')# 打印原始和过滤后数据的细胞数量
print(f"Total spots in spatial data: {adata.shape[0]}")
print(f"Total cells in filtered data: {adata_filtered.shape[0]}")
输出结果是这样的 所以你猜为什么要叫filtered的文件夹?
所以你猜为什么要叫filtered的文件夹?
4.一直很想知道.h5文件夹下到底是些个什么妖魔鬼怪?
官方文件下 里面有这个几个压缩包,再点进去看:
里面有这个几个压缩包,再点进去看:
barcodes就是ATCG之类的UMIspot的代号
feature就是一些基础的特征:类似于如下的基因表达
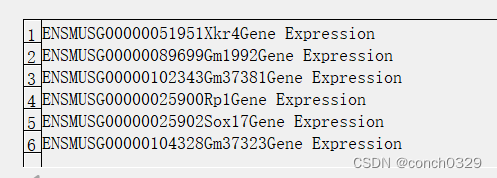
matrix是基因表达的稀疏矩阵
形式大概如下:
%%MatrixMarket matrix coordinate integer general
% A gene expression matrix
4 3 5
1 1 10
1 3 20
2 2 30
4 1 40
4 3 50
什么意思?
假设我们有一个基因表达矩阵,其中基因和样本的表达量如下:
| Gene \ Sample | Sample1 | Sample2 | Sample3 |
|---|---|---|---|
| Gene1 | 10 | 0 | 20 |
| Gene2 | 0 | 30 | 0 |
| Gene3 | 0 | 0 | 0 |
| Gene4 | 40 | 0 | 50 |
- 表示矩阵有 4 行(基因数)、3 列(样本数)、5 个非零元素。
-
1 1 10表示第 1 行第 1 列的值为 10(Gene1 在 Sample1 中的表达量)。1 3 20表示第 1 行第 3 列的值为 20(Gene1 在 Sample3 中的表达量)。2 2 30表示第 2 行第 2 列的值为 30(Gene2 在 Sample2 中的表达量)。4 1 40表示第 4 行第 1 列的值为 40(Gene4 在 Sample1 中的表达量)。4 3 50表示第 4 行第 3 列的值为 50(Gene4 在 Sample3 中的表达量)。
-
这种文件格式非常适合存储稀疏矩阵,其中大部分元素为零,只有少量非零元素,如基因表达矩阵、社会网络、推荐系统等中的数据。
这篇关于空间转录组基础数据解读+学习方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








