本文主要是介绍【传知代码】多视图3D目标检测位置嵌入变换(论文复现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:三维目标检测技术正逐渐成为计算机视觉领域的重要研究方向。特别是在自动驾驶、增强现实(AR)、虚拟现实(VR)以及机器人导航等应用中,对三维空间内目标的精准检测与定位显得尤为重要。然而,传统的二维目标检测技术已无法满足这些复杂场景下的需求,因此,多视图3D目标检测技术的崛起,为我们打开了一扇新的大门,本文将首先介绍多视图3D目标检测技术的基本原理和常用方法,然后深入探讨位置嵌入变换技术的核心算法和关键技术。接下来,我们将结合实际应用案例,分析多视图3D目标检测技术在现实场景中的挑战和解决方案。最后,我们将展望这一技术的未来发展趋势,并探讨可能的研究方向和应用前景。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
演示效果
核心代码
写在最后
概述
多视角图像中的3D目标检测由于其在自动驾驶系统中的低成本而具有吸引力,如下图所示:
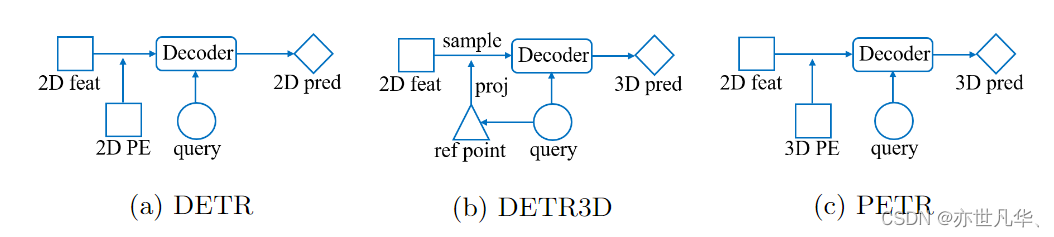
1)在DETR中,每个对象查询表示一个对象,与Transformer解码器中的2D特征交互以产生预测的结果。
2)在DETR3D中,由对象查询预测的3D参考点通过相机参数投影回图像空间,并对2D特征进行采样,以与解码器中的对象查询进行交互。
3)PETR通过将3D位置嵌入编码到2D图像特征中生成3D位置感知特征,对象查询直接与3D位置感知特征交互,并输出3D检测结果。
PETR体系结构具有许多优点,它既保留了原始DETR的端到端的方式,又避免了复杂的2D到3D投影和特征采样。
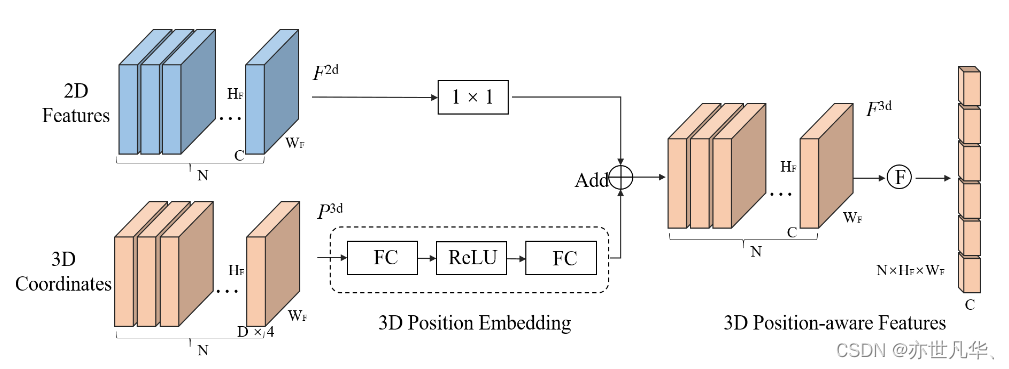
在给定来自N个视角的图像I={Ii∈R3×HI×WI,i=1,2,...,N}I={Ii∈R3×HI×WI,i=1,2,...,N},这些图像被输入到主干网络中,生成2D多视图特征F2d=Fi2d∈RC×HF×WF,i=1,2,...,NF2d=Fi2d∈RC×HF×WF,i=1,2,...,N。在3D坐标生成器中,相机视锥空间首先被离散化为三维网格,然后通过相机参数对网格坐标进行变化,生成3D世界空间中的坐标。3D坐标和2D多视图特征被输入到3D位置编码器中,产生3D位置感知特征F3d=Fi3d∈RC×HF×WF,i=1,2,...,NF3d=Fi3d∈RC×HF×WF,i=1,2,...,N。3D特征进一步输入到Transformer解码器,并与查询生成器生成的对象查询进行交互。更新后的对象查询用于预测对象类和3D边界框,如下图所示:

为了构建2D图像和3D空间之间的关系,PETR将相机视锥空间中的点投影到3D空间。PETR首先将相机视锥空间离散化以生成大小为(WF,HF,D)(WF,HF,D)的网格。网格中的每个点可以表示为pjm=(uj×dj,vi×dj,dj,1)Tpjm=(uj×dj,vi×dj,dj,1)T,其中(uj,vj)(uj,vj)是图像中的像素坐标,djdj是沿与图像平面正交的轴的深度值。由于网格由不同的视觉共享,因此可以通过3D逆投影来计算3D世界空间中对应的3D坐标 ,如下:
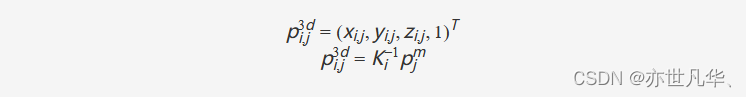
其中Ki∈R4×4Ki∈R4×4是第i个视图的变换矩阵,它建立了从3D空间到相机视锥空间的转换。所有视图的3D坐标在变换后覆盖场景的全景图。PETR进一步对3D坐标进行归一化。
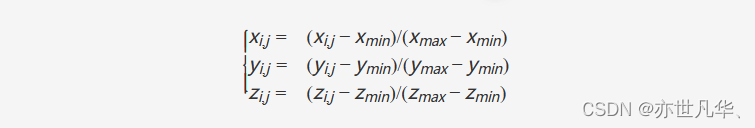
其中[xmin,ymin,zmin,xmax,ymax,zmax][xmin,ymin,zmin,xmax,ymax,zmax]是3D世界空间中的感兴趣区域(RoI),HF×WF×DHF×WF×D点的归一化坐标最终转置为P3d={Pi3d∈R(D×4)×HF×WF,i=1,2,…,N}P3d={Pi3d∈R(D×4)×HF×WF,i=1,2,…,N}。
3D位置编码的目的是通过将2D图像特征与3D位置信息相关联来获得3D特征,3D位置编码器可以公式化为:Fi3d=ψ(Fi2d,Pi3d),i=1,2,…,N,ψ的方法如下图所示,给定2D特征F2dF2d和3D坐标P3dP3d,P3dP3d首先输入到一个多层感知机网络中转换到3D位置编码(PE)之后,3D特征通过一个1x1的卷积层和3D PE相加形成3D位置感知特征。最终,PETR将3D位置感知特征作为transformer解码器中的key:
查询生成器:原始DETR直接使用一组可学习参数作为初始对象查询,可变形DETR和DETR3D基于初始化的对象查询预测参考点。为了缓解3D场景中的收敛困难,PETR首先在3D世界空间中初始化一组可学习的锚点,这些锚点具有从0到1的均匀分布。然后将3D锚点的坐标输入到具有两个线性层的小型MLP网络,生成初始对象查询Q0Q0。
解码器:对于解码器网络,PETR遵循DETR中的标准Transformer解码器,它包含了L个解码层,PETR将解码层中的交互过程公式化为Ql=Ωl(F3d,Ql−1),l=1,…,LQl=Ωl(F3d,Ql−1),l=1,…,L。在每个解码器层中,对象查询通过多头注意力和前馈网络与3D位置感知特征交互,迭代交互后,更新后的对象查询具有高级表示,可用于预测相应的对象。
演示效果
其中红色边界框表示自车车辆,Radar结果如下:

lidar 结果如下:

6个相机的结果如下:

核心代码
下面这段代码通过对图像特征进行位置编码,实现了将图像特征映射到现实世界的坐标空间,并生成对应的位置嵌入向量:
def position_embeding(self, img_feats, img_metas, masks=None):eps = 1e-5# 首先将所有的特征图都填充到原始图像的大小pad_h, pad_w, _ = img_metas[0]['pad_shape'][0]# 在特征图较大的情况下来获取它的位置信息B, N, C, H, W = img_feats[self.position_level].shape# 32但是每个间隔维16,因此定义每个图像放大的倍数为16的形式coords_h = torch.arange(H, device=img_feats[0].device).float() * pad_h / Hcoords_w = torch.arange(W, device=img_feats[0].device).float() * pad_w / Wif self.LID:# 此时定义的是深度信息,目的是为了转换吗index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()index_1 = index + 1# 获得每个网格的深度箱的大小,但是为什么还要除以65bin_size = (self.position_range[3] - self.depth_start) / (self.depth_num * (1 + self.depth_num))# 此时的结果也是64,但是此时深度箱的大小用来表示什么coords_d = self.depth_start + bin_size * index * index_1else:index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()bin_size = (self.position_range[3] - self.depth_start) / self.depth_numcoords_d = self.depth_start + bin_size * indexD = coords_d.shape[0]# [3,88,32,64]->[88,32,64,3] 通过将特征图进行离散化形成坐标来生成网格和视锥的形式coords = torch.stack(torch.meshgrid([coords_w, coords_h, coords_d])).permute(1, 2, 3, 0) # W, H, D, 3# 生成齐次坐标系,获得[x,y,z,1]形式的坐标coords = torch.cat((coords, torch.ones_like(coords[..., :1])), -1)# [88,32,64,2] x,y处也包含了深度的信息torch.tensorcoords[..., :2] = coords[..., :2] * torch.maximum(coords[..., 2:3], torch.ones_like(coords[..., 2:3])*eps)img2lidars = []for img_meta in img_metas:img2lidar = []# 针对6副图像,使用np将旋转矩阵的逆求解处出来for i in range(len(img_meta['lidar2img'])):img2lidar.append(np.linalg.inv(img_meta['lidar2img'][i]))# 将一个batch内的图像到雷达的数据计算出来img2lidars.append(np.asarray(img2lidar))# [1,6,4,4]img2lidars = np.asarray(img2lidars)# 使img2lidars获得coords相同的类型和device情况img2lidars = coords.new_tensor(img2lidars) # (B, N, 4, 4)# [1,1,88,32,64,4,1]->[1,6,88,32,64,4,1]coords = coords.view(1, 1, W, H, D, 4, 1).repeat(B, N, 1, 1, 1, 1, 1)# [1,6,1,1,1,4,4,4]->[1,6,88,32,64,4,4]img2lidars = img2lidars.view(B, N, 1, 1, 1, 4, 4).repeat(1, 1, W, H, D, 1, 1)# 6个图像分别进行相乘形成新的坐标系,从相机视锥空间生成6个视图现实空间的坐标。# 并且只选取x,y,z三个数据coords3d = torch.matmul(img2lidars, coords).squeeze(-1)[..., :3]# 位置坐标来进行归一化处理,pos_range是3D感兴趣区域,先前都设置好了coords3d[..., 0:1] = (coords3d[..., 0:1] - self.position_range[0]) / (self.position_range[3] - self.position_range[0])coords3d[..., 1:2] = (coords3d[..., 1:2] - self.position_range[1]) / (self.position_range[4] - self.position_range[1])coords3d[..., 2:3] = (coords3d[..., 2:3] - self.position_range[2]) / (self.position_range[5] - self.position_range[2])# 除去不再目标范围内的数据coords_mask = (coords3d > 1.0) | (coords3d < 0.0) # [1,6,88,32,64,3]->[1,6,88,32,192]->[1,6,88,32] 设定一个阈值,超过该阈值我们不再需要coords_mask = coords_mask.flatten(-2).sum(-1) > (D * 0.5)# 当取值为1的时候,此时是我们希望屏蔽的数据coords_mask = masks | coords_mask.permute(0, 1, 3, 2)# [1,6,88,32,64,3]->[1,6,64,3,32,88]->[6,192,32,88]coords3d = coords3d.permute(0, 1, 4, 5, 3, 2).contiguous().view(B*N, -1, H, W)# 将其转换为现实世界的坐标coords3d = inverse_sigmoid(coords3d)# embedding_dim是depth的四倍coords_position_embeding = self.position_encoder(coords3d)return coords_position_embeding.view(B, N, self.embed_dims, H, W), coords_mask下面这段代码主要功能是将输入的特征进行处理,然后输入到 Transformer 网络中进行计算。具体来说,该函数的执行过程如下:
1)从 mlvl_feats 中选择第一个特征,并获取其大小信息。
2)根据输入的大小信息,生成一个掩码 masks,用于遮挡无效区域。
3)对特征进行扁平化,并通过线性层进行变换,得到查询嵌入 query_embeds。
4)如果需要,生成位置编码,将其与查询嵌入相加得到最终的查询嵌入。
5)将查询嵌入输入到 Transformer 网络中进行计算,得到输出结果 outs_dec。
6)对输出结果进行后处理,得到分类分数和回归预测值。
def forward(self, mlvl_feats, img_metas):"""Forward function.Args:mlvl_feats (tuple[Tensor]): Features from the upstreamnetwork, each is a 5D-tensor with shape(B, N, C, H, W).Returns:all_cls_scores (Tensor): Outputs from the classification head, \shape [nb_dec, bs, num_query, cls_out_channels]. Note \cls_out_channels should includes background.all_bbox_preds (Tensor): Sigmoid outputs from the regression \head with normalized coordinate format (cx, cy, w, l, cz, h, theta, vx, vy). \Shape [nb_dec, bs, num_query, 9]."""# 因为此时两者的结构式一致的,因此选择第一个,且选择特征图较大的情况、x = mlvl_feats[0]batch_size, num_cams = x.size(0), x.size(1)# batch为1,且6个相机视角,每个视角下的大小都一致,因此选取第一个的形式input_img_h, input_img_w, _ = img_metas[0]['pad_shape'][0] masks = x.new_ones( # [1,6,512,1408] 不太确定此时的mask用来遮挡什么物体(batch_size, num_cams, input_img_h, input_img_w))for img_id in range(batch_size):for cam_id in range(num_cams):img_h, img_w, _ = img_metas[img_id]['img_shape'][cam_id]masks[img_id, cam_id, :img_h, :img_w] = 0# x.flatten(0,1)将第0维到第1维拍成第0维,其余保持不变 # x: [1,6,256,32,88]->[6,256,32,88]->[6,256,32,88] 不理解input的目的,是为了多加一个非线性吗x = self.input_proj(x.flatten(0,1)) x = x.view(batch_size, num_cams, *x.shape[-3:])# interpolate masks to have the same spatial shape with x [1,6,512,1408]->[1,6,32,88]# 在mask上进行采样,生成新的mask的形式,但此时mask的作用是什么呢masks = F.interpolate(masks, size=x.shape[-2:]).to(torch.bool)if self.with_position:# pos_embedding是PETR的重点,包含了坐标系的转换等一系列 此时生成的是3D位置嵌入coords_position_embeding, _ = self.position_embeding(mlvl_feats, img_metas, masks)pos_embed = coords_position_embeding# 如果具有多个视角,那么不同的视角也需要使用位置编码来进行操作if self.with_multiview:# [1,6,32,88]->[1,6,384,32,88]->[1,6,256,32,88]sin_embed = self.positional_encoding(masks)sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size())pos_embed = pos_embed + sin_embedelse:pos_embeds = []for i in range(num_cams):xy_embed = self.positional_encoding(masks[:, i, :, :])pos_embeds.append(xy_embed.unsqueeze(1))sin_embed = torch.cat(pos_embeds, 1)sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size())pos_embed = pos_embed + sin_embedelse:if self.with_multiview:pos_embed = self.positional_encoding(masks)pos_embed = self.adapt_pos3d(pos_embed.flatten(0, 1)).view(x.size())else:pos_embeds = []for i in range(num_cams):pos_embed = self.positional_encoding(masks[:, i, :, :])pos_embeds.append(pos_embed.unsqueeze(1))pos_embed = torch.cat(pos_embeds, 1)# [900,3] pos2posemb3d: [900,384]reference_points = self.reference_points.weight# 针对每个query形成一个嵌入的形式[900,256],线形层来生成查询query_embeds = self.query_embedding(pos2posemb3d(reference_points))# query是直接从Embedding生成 [1,900,3]reference_points = reference_points.unsqueeze(0).repeat(batch_size, 1, 1) #.sigmoid()# 利用transformer架构来获取query填充后的信息,之后用于计算class和bboxouts_dec, _ = self.transformer(x, masks, query_embeds, pos_embed, self.reg_branches)# 通过nan_to_num()将NaN转换为可处理的数字 [6,1,900,256]outs_dec = torch.nan_to_num(outs_dec)outputs_classes = []outputs_coords = []for lvl in range(outs_dec.shape[0]):reference = inverse_sigmoid(reference_points.clone())assert reference.shape[-1] == 3outputs_class = self.cls_branches[lvl](outs_dec[lvl])tmp = self.reg_branches[lvl](outs_dec[lvl])tmp[..., 0:2] += reference[..., 0:2]tmp[..., 0:2] = tmp[..., 0:2].sigmoid()tmp[..., 4:5] += reference[..., 2:3]tmp[..., 4:5] = tmp[..., 4:5].sigmoid()outputs_coord = tmpoutputs_classes.append(outputs_class)outputs_coords.append(outputs_coord)all_cls_scores = torch.stack(outputs_classes)all_bbox_preds = torch.stack(outputs_coords)# 转换为3D场景下的数据all_bbox_preds[..., 0:1] = (all_bbox_preds[..., 0:1] * (self.pc_range[3] - self.pc_range[0]) + self.pc_range[0])all_bbox_preds[..., 1:2] = (all_bbox_preds[..., 1:2] * (self.pc_range[4] - self.pc_range[1]) + self.pc_range[1])all_bbox_preds[..., 4:5] = (all_bbox_preds[..., 4:5] * (self.pc_range[5] - self.pc_range[2]) + self.pc_range[2])outs = {'all_cls_scores': all_cls_scores,'all_bbox_preds': all_bbox_preds,'enc_cls_scores': None,'enc_bbox_preds': None, }return outs下面这段代码是一系列指令,用于配置并准备运行一个复杂的3D目标检测项目所需的环境和依赖:
# 新建一个虚拟环境
conda activate petr
# 下载cu111 torch1.9.0 python=3.7 linux系统
wget https://download.pytorch.org/whl/cu111/torch-1.9.0%2Bcu111-cp37-cp37m-linux_x86_64.whl
pip install 'torch下载的位置'
wget https://download.pytorch.org/whl/cu111/torchvision-0.10.0%2Bcu111-cp37-cp37m-linux_x86_64.whl
pip install 'torchvison下载的地址'
# 安装MMCV
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
# 安装MMDetection
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
git checkout v2.24.1
sudo pip install -r requirements/build.txt
sudo python3 setup.py develop
cd ..# 安装MMsegmentation
sudo pip install mmsegmentation==0.20.2# 安装MMdetection 3D
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.1
sudo pip install -r requirements/build.txt
sudo python3 setup.py develop
cd ..# 安装PETR
git clone https://github.com/megvii-research/PETR.git
cd PETR
mkdir ckpts ###pretrain weights
mkdir data ###dataset
ln -s ../mmdetection3d ./mmdetection3d
ln -s /data/Dataset/nuScenes ./data/nuscenes写在最后
在本文中,我们深入探讨了多视图3D目标检测中的位置嵌入变换技术,这一领域不仅是当前计算机视觉研究的热点,更是未来诸多智能应用系统的核心技术支撑。通过详细解析位置嵌入变换的原理、算法以及其在多视图3D目标检测中的应用,我们不难发现,这一技术正逐步改变着我们对于目标检测与定位的认知。.
视图3D目标检测位置嵌入变换技术将在更多领域得到应用。自动驾驶汽车、无人机导航、增强现实技术、智能安防系统等等,都将受益于这一技术的突破。我们有理由相信,在不远的将来,这一技术将如同今天的智能手机一样,深入到我们生活的方方面面,改变我们的世界。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号

这篇关于【传知代码】多视图3D目标检测位置嵌入变换(论文复现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



