本文主要是介绍使用pycharm+opencv进行视频抽帧(可以用来扩充数据集)+ labelimg的使用(数据标准),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.视频抽帧
1.新创建一个空Pycharm项目文件,命名为streach zhen
注:然后要做一个前期工作 创建opencv环境
(1)我们在这个pycharm项目的终端里面输入下面的命令:
pip install opencv-python --user -i https://pypi.tuna.tsinghua.edu.cn/simple pip install opencv-contrib-python --user -i https://pypi.tuna.tsinghua.edu.cn/simple这里可能会报错:如果你用的是base环境,那么原样输入上面两个命令。如果创建的是虚拟环境,把上面两条语句中的--user去掉。
(2)使用一个测试python文件看看安装好了没有
·创建一个新的python文件,命名为test.py(注:这个截图里面的其他文件夹是后面创建的,可以先不管)
·这个test.py里面复制下面这个语句,看看有没有报错问题。没有就安装好了
import cv2 as cvsrc = cv.imread("D:/desk.jpg") cv.namedWindow("input image",cv.WINDOW_AUTOSIZE) cv.imshow("input image",src) cv.waitKey(0) cv.destroyAllWindows() print("hi python")
2.将一个预先找好的mp4文件(这里用的是这个BVN.mp4)复制粘贴进这个文件夹里面
(注:这个截图里面的其他文件夹是后面创建的,可以先不管)
我跟着B站博主做的,这个mp4文件可以在大佬的github里面找到,大家可以自己在里面下载
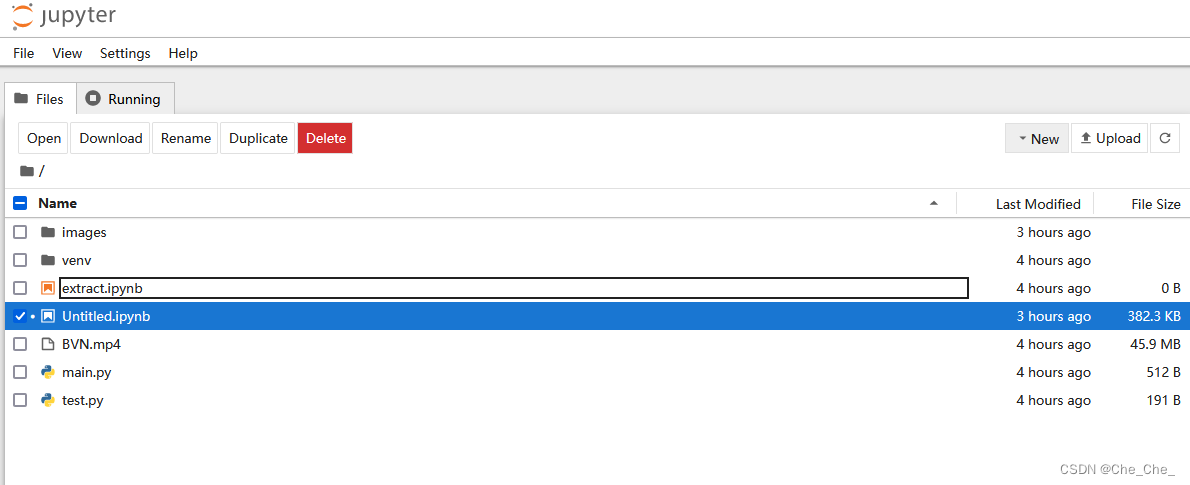
3.在终端输入:
jupyter notebook网页端会自动打开(如图所示)
4.New一个.ipynb文件 ,打开它(自己照着敲一遍)

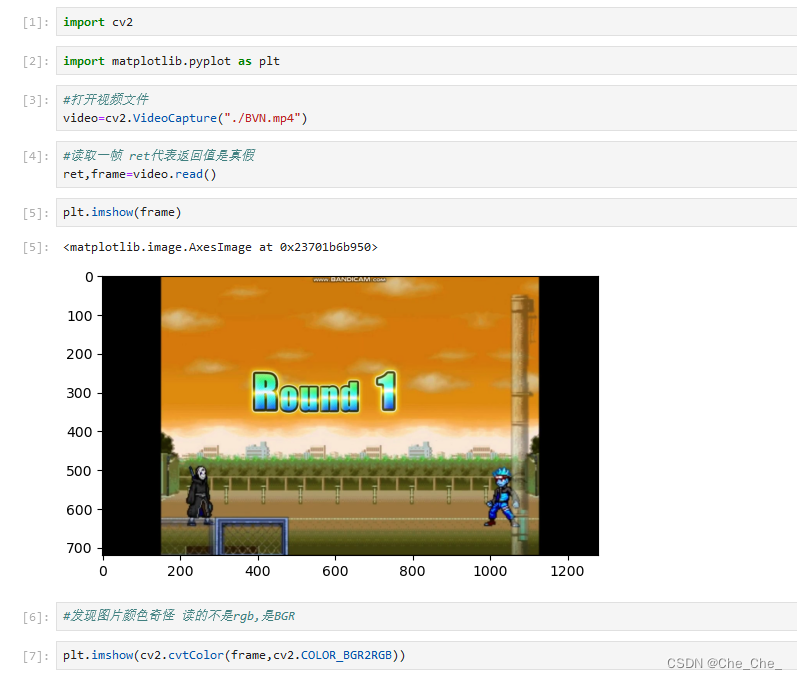
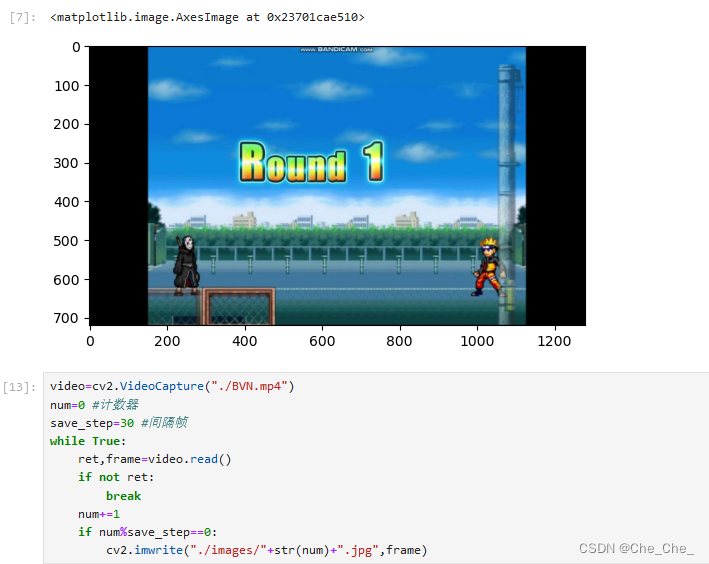
注意,在第13行代码的最后,我们把这个mp4里面抽的帧放在了image这个文件夹下面,我跟着博主做的时候,博主用的vscode,会自动生成images这个文件夹,但是我的不行,在jupyter里面运行对于语句之后虽然没有报错,但是发现pycharm项目里面没有新生成一个images文件夹(里面应该存放的是很多抽出来的帧图片)。问了同义千文,发现需要自己在pycharm项目下创建一个images的文件夹,不然它找不到。
咱就是说一整个大成功!
二.使用labelimg
1.在终端输入:
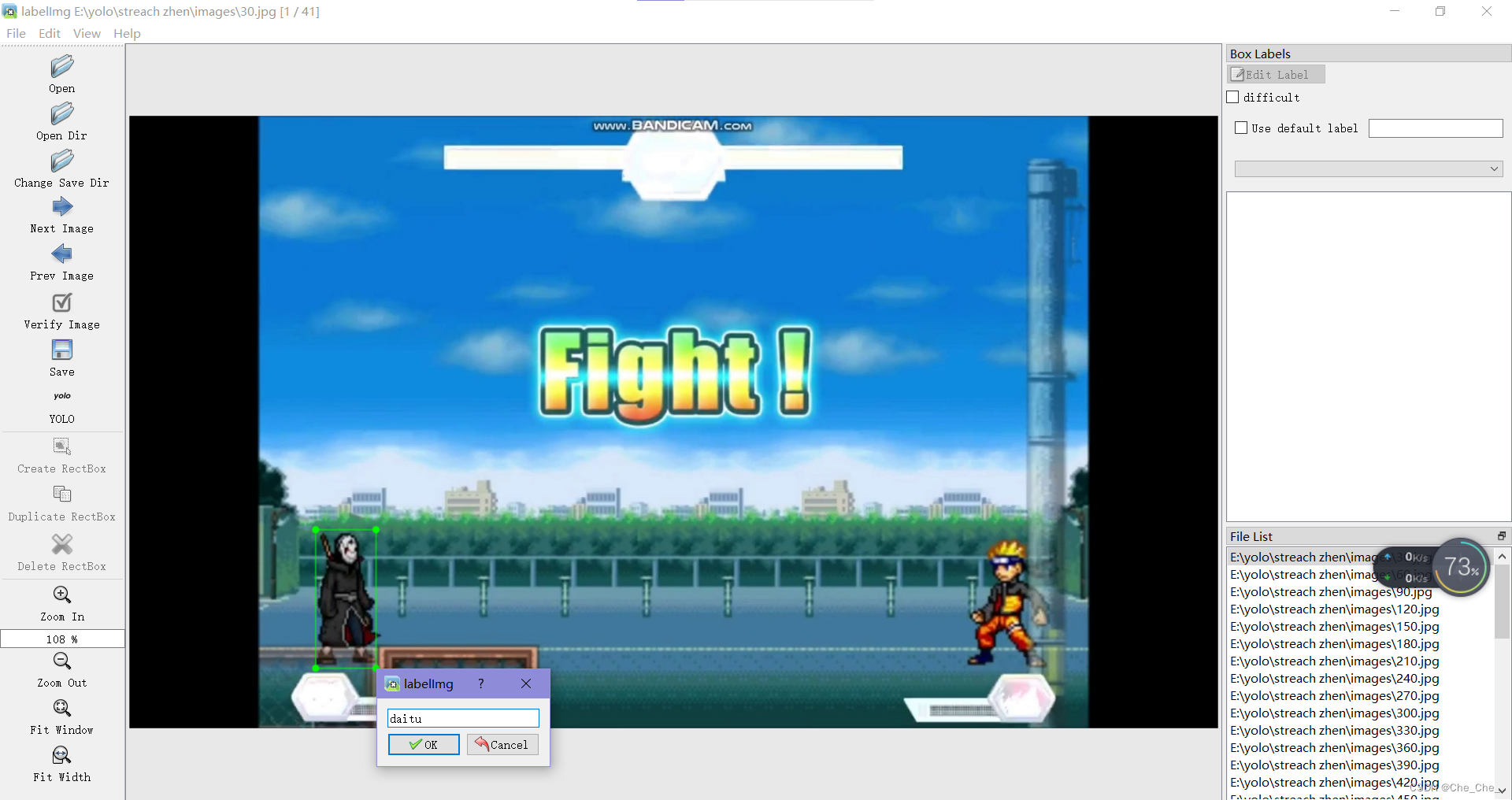
pip install labelimg labelimg会自动打开这个小窗口
。爱了爱了!
2.使用事项
右键
快捷键:A 上一张 D下一张 W快速创建框
接下来就是体力活儿了
3.数据调整

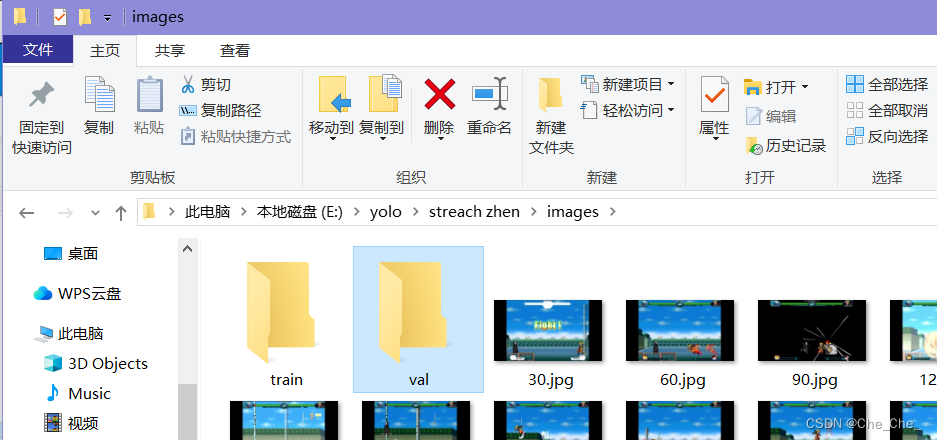
在images文件夹里面新建两个文件夹
·train
·val
300-480放到val里面去,其余的放到train里面去
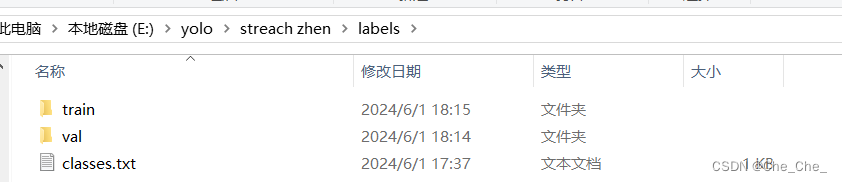
labels文件也同上操作 (注意:class文件不要放进去)
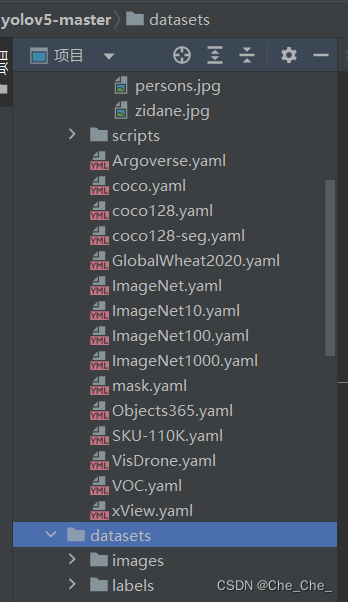
4.把labels和images都放到一个datasets文件夹下面,然后把这个datasets文件夹复制粘贴到我们的yolo项目下面去。这个yolov5-master是在官方github下面下载的,里面的环境配置可以自行搜索怎么配。CSDN上面有很多,我之前的博客里面也有,这里不再赘述。
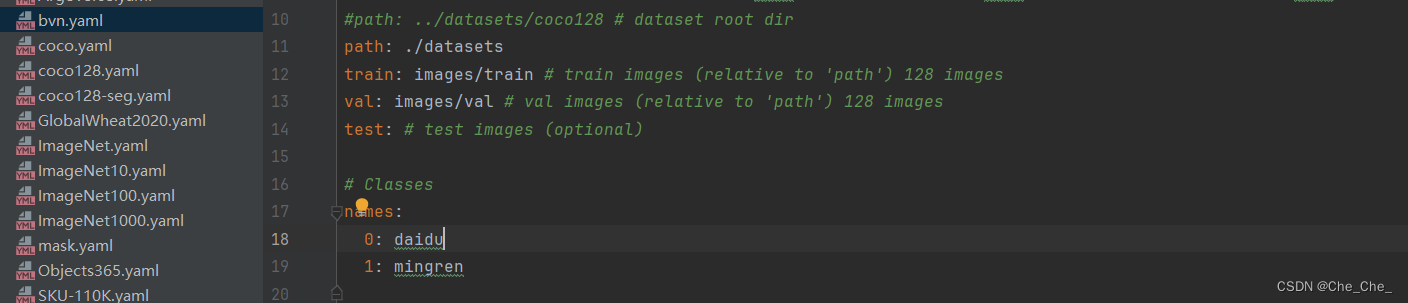
5.修改data里面的数据集描述文件,我们直接复制一份coco128.yaml,并且重命名为BVN.yaml,然后在里面改参数
6.train.py里面把这里改了

7.运行train.py
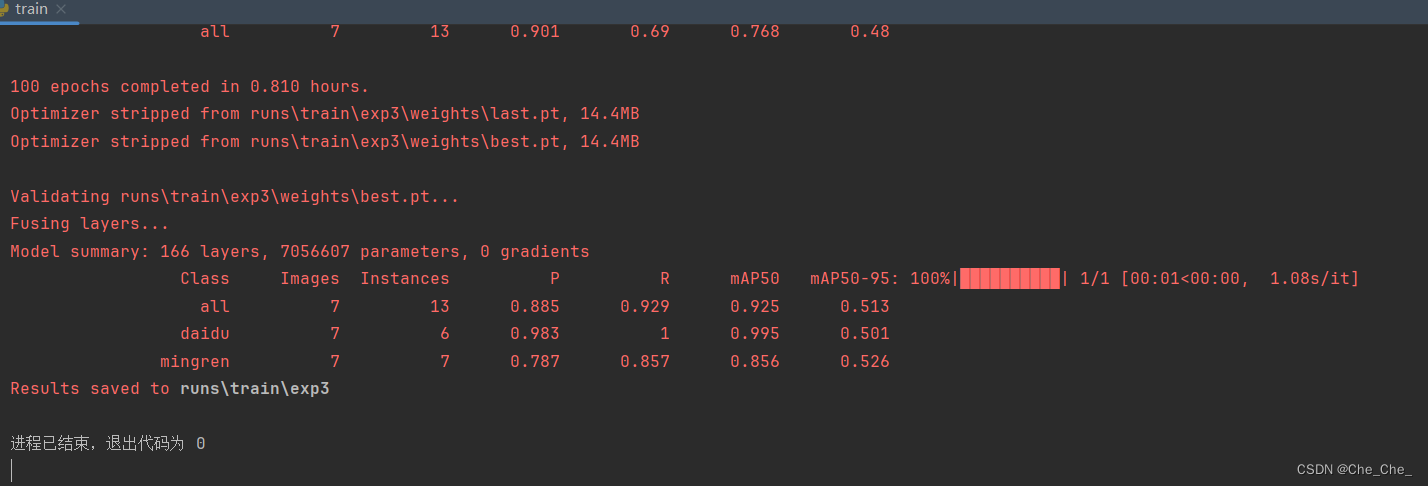
又是一个大成功!!

这篇关于使用pycharm+opencv进行视频抽帧(可以用来扩充数据集)+ labelimg的使用(数据标准)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



