本文主要是介绍K210视觉识别模块学习笔记4: 训练与使用自己的模型_识别字母,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今日开始学习K210视觉识别模块: 模型训练与使用_识别字母
亚博智能的K210视觉识别模块......
固件库: maixpy_v0.6.2_52_gb1a1c5c5d_minimum_with_ide_support.bin
文章提供测试代码讲解、完整代码贴出、测试效果图、测试工程下载
这里也算是正式开始进入到视觉识别的领域了,先从训练模型 与 识别字母开始吧......
本文目标很简单,就是尝试训练自己的模型识别字母A与B
目录
工具软件准备:
工具软件打包下载:
拍摄图片:
文件与图片处理:
新建文件夹:
Image_tool 图片处理:
labeling软件标注训练集:
打开文件夹:
更改保存输出:
打开自动保存:
框注限制识别的区域:
检查xml文件夹:
labels填写标签:
网站创建项目:
部署模型文件:
修改主函数:
测试程序前有些固件问题需要调整:
下载适配的固件:
先擦除固件:
然后使用kflash_kui烧录以下固件库到flash:
重启开机测试效果展示:
固件与模型打包下载:
网上学习资料贴出:
OpenCV Label标注软件
之前尝试下载使用多个固件的尝试:
工具软件准备:
自己训练模型主要有俩个工具软件需要准备:
1、 Image_tool (用于图像格式清晰度转换)
2、 labelImg(用于打标签)
工具软件打包下载:
当然你也可以不使用和我一样的工具软件,网上有许多各种各样的功能更多的软件:(文末有链接可以了解其他软件)
https://download.csdn.net/download/qq_64257614/89383899
拍摄图片:
1、确保拍摄角度与实际应用场景相匹配。
2、如果可能,模拟K210模块如何查看这些图片。即使用K210来取图,(这需要自己编程K210拍摄图片的例程):
K210视觉识别模块学习笔记3:内存卡写入拍摄图片_LED三色灯的操作_按键操作_定时器的配置使用-CSDN博客
3、光线要充足且均匀,避免过曝或欠曝,以及阴影和反光。
4、拍摄不同角度、不同光照条件、不同背景、不同大小和形状的图像,以增加模型的泛化能力。
5、考虑图像的各种旋转、缩放和倾斜,以模拟实际应用中的变化。
这里我也是拍摄了一共25张AB各个角度的照片:

文件与图片处理:
新建文件夹:
像我一样新建一个文件夹 (这个文件夹名称任意)
但是在里面新建以下的几个项目名称必须一致:

Image_tool 图片处理:
这个是选择图像所在文件夹进行转换的:
转换完成会在图像目录产生一个新的文件夹inages_out
然后我们删掉原来的文件夹,将"inages_out"名称改为"inages"



labeling软件标注训练集:
注意点:
有些人可能会出现双击程序,弹出了一个命令控制台,结果2秒就退出,无法打开labeling的情况,这时应检查它的所在目录有无中文字符,如果有,请不要放在有中文字符的目录!
其余打不开情况请检查你的Python环境
打开文件夹:
更改保存输出:
打开自动保存:
框注限制识别的区域:
然后像这样将图片中所有A\B都框柱出来:
检查xml文件夹:
全部标注完后应该有相应数量的xml文件生成在文件夹:
labels填写标签:
这一步是要在之前创建的labels.txt中填写我们用到的标注:
我们用到了A\B,俩个标注用换行隔开







网站创建项目:
在线训练模型网址如下:
MaixHub
先准备好之前整个文件准备的压缩包(zip格式):

跟着以下步骤进行点击创建:






我们发现其实这个网站也可以进行数据标注:

然后回到刚才的项目,选择了数据集后创建任务:
这里我也没研究这些参数有何意义,但我问了AI,并将它的解释放在下文:

- 迭代次数(Epochs):
- 迭代次数决定了模型在整个数据集上训练的次数。
- 如果迭代次数太少,模型可能无法充分学习数据的特征;如果迭代次数太多,模型可能会过拟合。
- 建议从较小的迭代次数开始(如10个epochs),然后根据验证集的性能逐渐增加。
- 批数据量大小(Batch Size):
- 批数据量大小决定了在更新模型参数之前用于计算梯度损失的数据样本数量。
- 较大的批数据量可以加速训练,但可能会消耗更多的内存;较小的批数据量可以更有效地适应不同的数据分布,但可能会降低训练速度。
- 根据硬件资源和数据集大小选择合适的批数据量大小,常见的选择包括32、64、128等。
- 最大学习率(Learning Rate):
- 学习率决定了模型参数在每次迭代中更新的幅度。
- 如果学习率太大,模型可能无法收敛;如果学习率太小,训练可能会非常缓慢。
- 可以使用学习率衰减策略(如指数衰减、余弦衰减等),在训练过程中逐渐减小学习率。
- 初始学习率的选择通常需要根据实验来确定,常见的选择包括0.01、0.001等。
- 标注框限制(Bounding Box Constraints):
- 在目标检测任务中,标注框限制可能涉及标注框的大小、比例或位置等。
- 这些限制可以根据具体任务和数据集进行调整,以确保标注框的准确性和一致性。
- 数据均衡(Data Balancing):
- 如果数据集中不同类别的样本数量差异很大,可能会导致模型对某些类别的识别性能较差。
- 可以使用数据均衡技术(如过采样少数类、欠采样多数类等)来平衡不同类别的样本数量。
- 标准化平均值(Mean Normalization)和标准差(Standard Deviation Normalization):
- 在数据预处理阶段,对输入数据进行标准化可以提高模型的训练速度和性能。
- 标准化平均值和标准差通常根据训练数据的统计信息来确定。对于图像数据,常见的做法是对每个颜色通道分别计算平均值和标准差,并在输入模型之前将数据减去平均值并除以标准差。
需要注意的是,以上参数的具体调整值需要根据实际任务和数据集进行确定。在训练过程中,可以使用交叉验证、早停(Early Stopping)等技术来监控模型的性能,并根据验证集的性能调整训练参数。此外,还可以使用网格搜索(Grid Search)等调参方法来系统地搜索最佳参数组合。
就是需要我们调整各个参数进行训练,使得准确率提升:
像我这就最终通过多次调整参数训练出来了100准确率的模型了:

然后就是训练出高准确率的模型后,选择手动部署模型,来下载模型文件:

部署模型文件:
解压模型后直接把内容都复制到SD卡:

修改主函数:
它的主函数写的有些问题,需要我们添加一行代码在头部:
from machine import UART

测试程序前有些固件问题需要调整:
K210固件库支持多下载码(或称为多固件、多版本固件)
下载适配的固件:
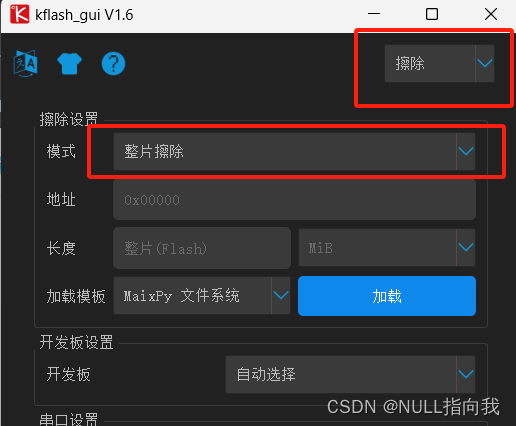
先擦除固件:
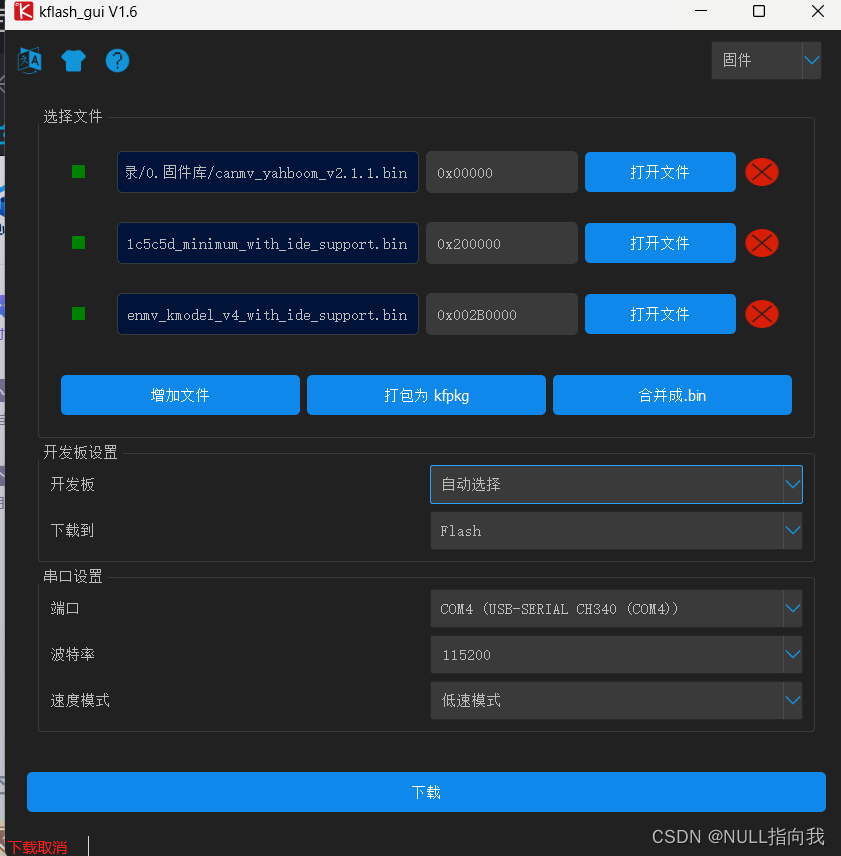
然后使用kflash_kui烧录以下固件库到flash:
maixpy_v0.6.2_52_gb1a1c5c5d_minimum_with_ide_support.bin


重启开机测试效果展示:

固件与模型打包下载:
https://download.csdn.net/download/qq_64257614/89385496
网上学习资料贴出:
K210 Mx-yolov3模型训练和物体识别-CSDN博客
[教程]从0自制模型,实现多物体识别(以k210多数字识别举例)_哔哩哔哩_bilibili
OpenCV Label标注软件
之前尝试下载使用多个固件的尝试:
之前尝试过下载多个固件,但貌似没法使用......
也许只是我操作不太对......
这篇关于K210视觉识别模块学习笔记4: 训练与使用自己的模型_识别字母的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






