本文主要是介绍使用Streamlit和MistralAI创建AI聊天机器人应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,创建交互式和用户友好型的应用程序通常需要复杂的框架和耗时的开发过程。Streamlit是一个Python库,它简化了以数据为重点的网络应用程序的创建过程,使开发人员和数据科学家能够快速将他们的想法转化为交互式仪表盘和原型。本文将介绍使用 Streamlit 和 Mistral AI 构建自己的聊天机器人。
1.Mistral AI简介
Mistral AI是一家位于法国的公司,致力于成为开放人工智能的领军者,其核心使命是为开发者社区带来顶尖的开放模型。该公司以对开源精神的坚守而闻名,不仅向公众提供了遵循Apache 2.0许可的模型,还提供了原始模型权重,以支持和促进研究工作。
Mistral AI 不仅向公众开放了其预训练和微调模型的源代码,还提供了模型的原始权重,以支持更深层次的研究和开发。以下是他们发布的几个模型及其对应的 Hugging Face 链接和原始权重的校验和(md5sum):
-
Mistral-7B-v0.1: Hugging Face(https://huggingface.co/mistralai/Mistral-7B-v0.1) // 原始权重 (md5校验和:
37dab53973db2d56b2da0a033a15307f). -
Mistral-7B-Instruct-v0.2: Hugging Face(https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) // 原始权重 (md5校验和:
fbae55bc038f12f010b4251326e73d39). -
Mixtral-8x7B-v0.1: Hugging Face(https://huggingface.co/mistralai/Mixtral-8x7B-v0.1).
-
Mixtral-8x7B-Instruct-v0.1: Hugging Face(https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) // 原始权重 (md5校验和:
8e2d3930145dc43d3084396f49d38a3f).
通过这些开放资源,Mistral AI 为人工智能社区的研究者和开发者提供了宝贵的工具和数据,进一步推动了开放科学的进步。
2.Mistral AI 模型
Mistral AI 提供多种模型,包括小型、中型、大型以及嵌入模型,以满足不同应用场景的需求。
2.1 Tiny(小型)模型
-
用途:非常适合执行大规模数据处理任务,特别是那些对成本较为敏感而对模型的推理能力要求不高的应用场景。
-
当前版本:由Mistral-7B-v0.2驱动,该模型是Mistral-7B的优化微调版,其改进受到了社区贡献的启发。
-
API名称:mistral-tiny
2.2 Small(中型)模型
-
特点:具备更高的推理能力和更丰富的功能。
-
支持语言:支持英语、法语、德语、意大利语和西班牙语,并且能够生成代码以及对代码进行推理。
-
当前版本:由Mixtral-8X7B-v0.1驱动,该模型是一个先进的稀疏专家混合模型,拥有高达12亿个活跃参数。
-
API名称:mistral-small
2.3 Medium(大型)模型
-
说明:这个端点目前依赖于一个内部原型模型,该模型目前尚未对外公开发布。
-
API名称:mistral-medium
Mistral AI 还提供了嵌入模型:
-
Mistral AI通过其API端点提供了嵌入模型,这些模型能够支持检索(retrieval)和增强检索的生成应用(retrieval-augmented generation applications)。
-
该端点输出的是1024维的向量。在MTEB(可能是一个特定的评估指标或数据集)上,该模型达到了55.26的检索得分。
-
提供的API名为mistral-embed。
3.定价
定价是按使用量计费,如图所示。

Mistral AI 有个很棒的仪表板,可以显示使用情况。

与其他模型的比较:

Mistral-中型模型以其出色的性能令人印象深刻,完美地位于 GPT-3.5 和 GPT-4 之间。基于实践经验,对于那些在使用GPT-3.5时遇到一致性或质量问题的用户,Mistral-中型无疑是一个理想的选择。
其他主机上更经济的选项:
-
Anyscale: Mistral-小型 (7B) 和 Mistral-中型 (8x7B) 模型的价格分别为 和0.50/M。
-
Deepinfra: 提供 Mixtral,价格为 $0.27/M 输入和输出。
4.构建聊天机器人
4.1 使用简历的示例聊天应用
使用一份简历进行这个演示,可以使用想要的任何文档。

4.2 阅读 PDF
这里简历在数据文件夹中:
from pathlib import Path
from pypdf import PdfReaderpdf_files = Path("data").glob("*.pdf")
text = ""for pdf_file in pdf_files:reader = PdfReader(pdf_file)
for page in reader.pages:text += page.extract_text() + "\n\n"
使用 pathlib Path 读取数据文件夹,并使用 pypdf 读取 pdf 文件,将所有内容存储在 text 变量中。
查看前 100 个字符:
print(text[:100])
print(len(text))
Benedict Neo
/envel⌢pebenedict.neo@outlook.com /linkedinin/benedictneo /github@benthecoder
Education
3817
4.3 分块
为了高效执行检索增强生成(RAG),向大型语言模型(LLMs)提供上下文数据,以降低生成响应中的误差。要实现RAG,首先需要将文档切分成较小的片段,这样做有助于更精确地识别和提取相关信息。
根据不同的应用场景,选择合适的片段大小对于RAG准确捕捉和抽取关键信息至关重要。较大的文本片段可能包含冗余内容,这会干扰模型对语义的理解。
以本次操作为例,将文档按500字一段进行合并,最终得到了8个信息块。
chunk_size = 500
chunks = [text[i : i + chunk_size] for i in range(0, len(text), chunk_size)]
len(chunks)8
4.4 嵌入
为了将文本数据转换为机器学习模型能够处理的格式,这里为每个文本块生成了一个文本嵌入,也就是文本在向量空间中的数值表示。简单来说,就是将每个单词转换成一个向量。
在这个向量空间里,语义相近的单词会被映射到彼此接近的位置。
利用Mistral AI提供的嵌入API端点来生成这些嵌入。此外,还编写了一个简洁的嵌入函数,能够从单个文本块中提取嵌入,并将它们统一存储在一个NumPy数组中,以便于后续处理和分析。
from mistralai.client import MistralClient
import numpy as npclient = MistralClient(api_key="YOUR_MISTRAL_KEY")def embed(input: str):return client.embeddings("mistral-embed", input=input).data[0].embeddingembeddings = np.array([embed(chunk) for chunk in chunks])
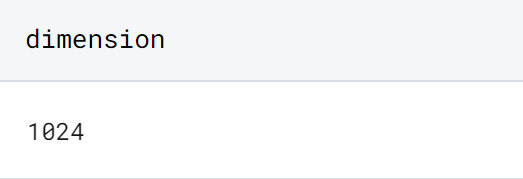
dimension = embeddings.shape[1]
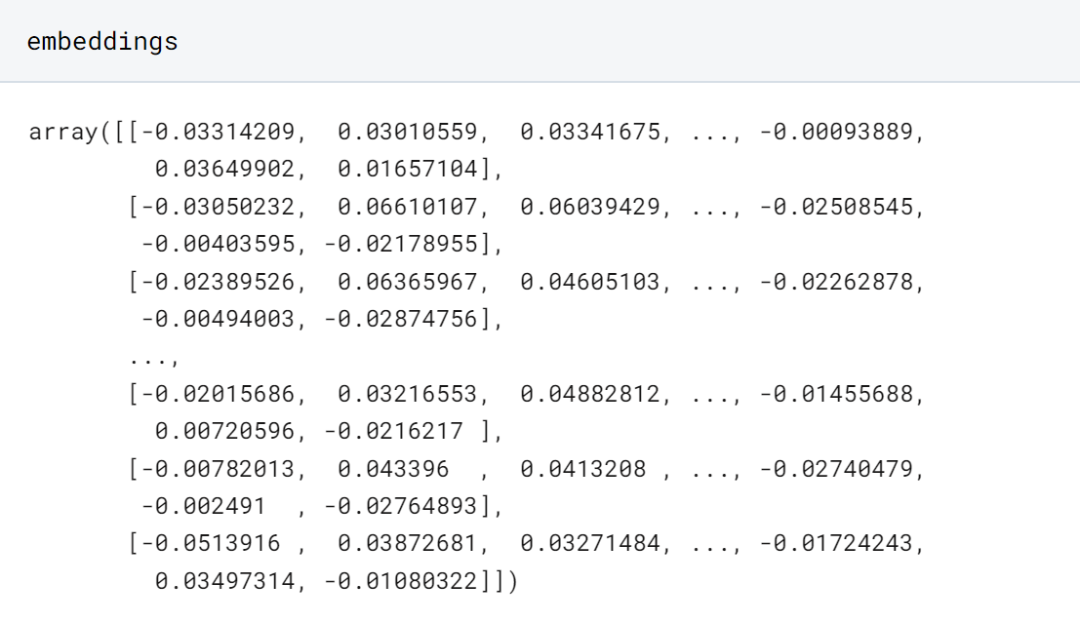
这些嵌入的维度为 1024,这意味着单词向量的大小为 1024。
4.5 向量数据库
生成文本嵌入后,将其存储在向量数据库中,以便于进行高效的处理和检索。这里选择 Faiss,这是一款由 Meta(原Facebook公司)开发的开源向量数据库,来实现这一功能。
为了存储嵌入,构建了一个索引。除了选择的索引类型外,还有其他多种索引选项可供使用。
import faissd = embeddings.shape[1]
index = faiss.IndexFlatL2(d)
index.add(embeddings)
现在有一个存储所有嵌入的索引,就可以处理用户的问题了。
4.6 查询
当用户提出问题时,使用相同的模型创建嵌入,这样就可以比较用户的问题和我们存储的嵌入。
question = "Who is Benedict Neo?"
question_embeddings = np.array([embed(question)])
4.7 检索
为了精准地检索出最能满足用户查询需求的信息,采用了向量数据库的索引搜索功能。具体来说,这里调用了index.search方法,它主要依赖两个参数:一是用户问题的嵌入向量,二是我们需要检索的相似向量的数量,记作k。
执行搜索后,该函数会返回两个列表:一个是与查询最相似的向量与原向量之间的距离列表(记为D),另一个是这些最相似向量在数据库中的索引列表(记为I)。通过这些索引,就能够定位并返回对应的原始文本内容。
4.8 提示
创建一个提示模板,将检索到的数据块和问题结合起来。
prompt = f"""
Context information is below.
---------------------
{retrieved_chunk}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {question}
Answer:
"""
4.9 聊天模型
为了生成答案,这里采用Mistral聊天完成API和相应的Mistral模型。本例选择了mistral-medium模型,利用这个模型能够结合用户的问题以及检索到的相关上下文信息,生成准确且富有洞见的答案。
from mistralai.client import ChatMessagedef run_mistral(user_message, model="mistral-medium"):messages = [ChatMessage(role="user", content=user_message)]chat_response = client.chat(model=model, messages=messages)return chat_response.choices[0].message.contentrun_mistral(prompt)
4.10 整合与测试
可以将上述各个环节整合起来,构建一个名为ask的函数。这个函数十分简洁,仅需传入一个问题作为参数,便能够自动执行整个查询流程,并最终返回一个经过处理的响应结果。
接下来,建议通过几个具体问题来测试这个函数,以验证其性能和准确性。
from faiss import IndexFlatL2prompt = """
Context information is below.
---------------------
{context}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {query}
Answer:
"""def ask(query: str, index: IndexFlatL2, chunks):embedding = embed(query)embedding = np.array([embedding])_, indexes = index.search(embedding, k=2)context = [chunks[i] for i in indexes.tolist()[0]]user_message = prompt.format(context=context, query=query)messages = [ChatMessage(role="user", content=user_message)]chat_response = client.chat(model="mistral-medium", messages=messages)return chat_response.choices[0].message.contentask("What work experience does he have?", index, chunks)
ask("Does he know how to code in Python?", index, chunks)
ask("What projects has he worked on?", index, chunks)
ask("Is he on the job market?", index, chunks)
了解构成应用程序的各个部分后,让我们了解streamlit 应用程序。
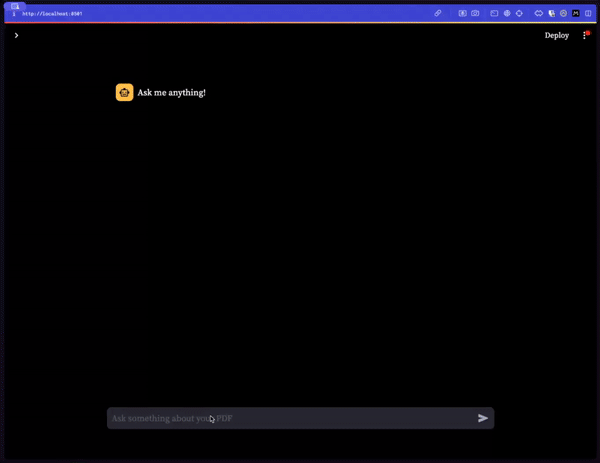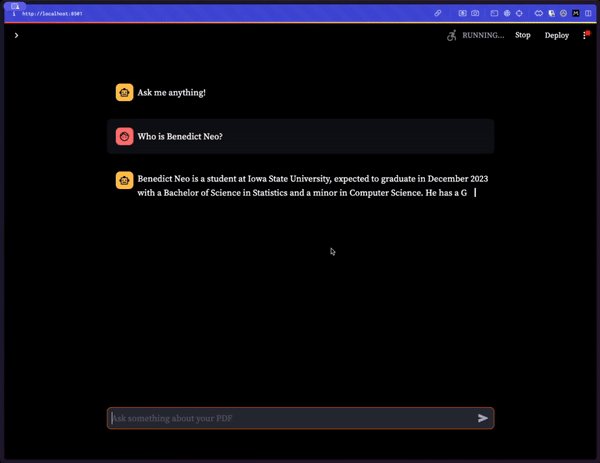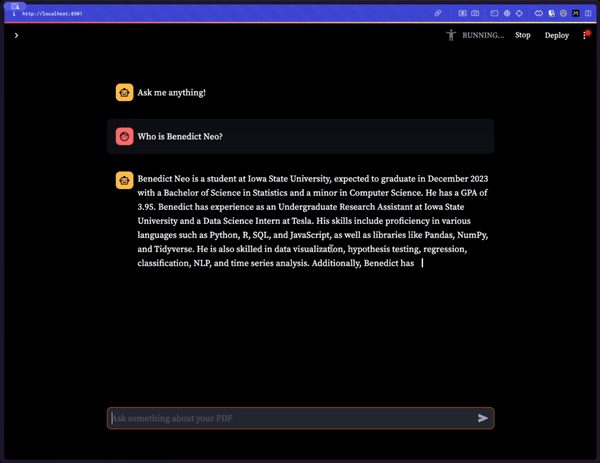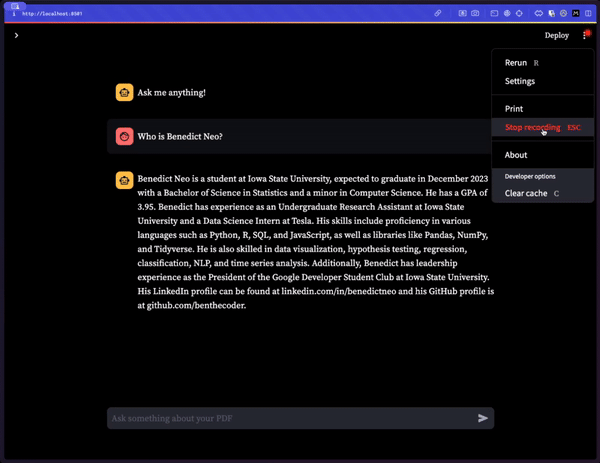
5.Streamlit 应用程序
进行应用程序的演示,包括文本流。
5.1 构建索引
这里设计了一个函数,负责创建索引并返回索引及其对应的块。这些块在处理新的查询时至关重要,因为它们将被用于检索操作。
为了提高效率,利用st.cache_resource对索引进行了缓存。这样在使用Streamlit应用时,就不需要每次都重新创建索引,从而节约了计算资源,加快了应用的响应速度。
# 构建并缓存目录中的PDF文件的索引的函数
@st.cache_resource
def build_and_cache_index():"""Builds and caches the index from PDF documents in the specified directory."""pdf_files = Path("data").glob("*.pdf")text = ""for pdf_file in pdf_files:reader = PdfReader(pdf_file)for page in reader.pages:text += page.extract_text() + "\n\n"chunk_size = 500chunks = [text[i : i + chunk_size] for i in range(0, len(text), chunk_size)]embeddings = np.array([embed(chunk) for chunk in chunks])dimension = embeddings.shape[1]index = IndexFlatL2(dimension)index.add(embeddings)return index, chunks
5.2 实现流式输出
为了模拟流式传输,编写了一个生成器 stream_response,它产生 AI 的响应,另一个生成器 stream_str 逐个字符地产生字符串中的字符,并通过 st.write_stream 传递。
# 用于延时流式输出字符串的函数
def stream_str(s, speed=250):"""Yields characters from a string with a delay to simulate streaming."""for c in s:yield ctime.sleep(1 / speed)# 用于流式输出AI的响应的函数
def stream_response(response):"""Yields responses from the AI, replacing placeholders as needed."""for r in response:content = r.choices[0].delta.content# prevent $ from rendering as LaTeXcontent = content.replace("$", "\$")yield content
5.3 存储消息
为了在应用程序中维护聊天历史记录,在会话状态变量 messages 中填充聊天。
# 用于向聊天界面添加消息的函数
def add_message(msg, agent="ai", stream=True, store=True):"""Adds a message to the chat interface, optionally streaming the output."""if stream and isinstance(msg, str):msg = stream_str(msg)with st.chat_message(agent):if stream:output = st.write_stream(msg)else:output = msgst.write(msg)if store:st.session_state.messages.append(dict(agent=agent, content=output))
5.4 主程序
在我们的主程序中,设置了一个侧边栏按钮,它的作用是重置对话。点击这个按钮,可以清除当前的会话状态,从而开始一个新的对话。
为了打造一个完整的对话系统,这里把所有的功能模块整合到了一起。首先,在界面上添加了一条欢迎消息,鼓励用户“问我任何问题!”。每当用户输入一个查询,都会在对话历史中添加一条新的消息,并把这个查询传递给reply函数,以此来生成并返回相应的回答。
# 主应用程序逻辑
def main():"""Main function to run the application logic."""if st.sidebar.button("🔴 Reset conversation"):st.session_state.messages = []index, chunks = build_and_cache_index()for message in st.session_state.messages:with st.chat_message(message["agent"]):st.write(message["content"])query = st.chat_input("Ask something about your PDF")if not st.session_state.messages:add_message("Ask me anything!")if query:add_message(query, agent="human", stream=False, store=True)reply(query, index, chunks)这篇关于使用Streamlit和MistralAI创建AI聊天机器人应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






