本文主要是介绍【从零开始学爬虫】采集亚马逊商品信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
l 采集网站
【场景描述】采集亚马逊搜索关键词出来的商品信息。
【入口网址】https://www.amazon.com/-/zh/ref=nav_logo

【采集内容】采集亚马逊搜索关键词搜索出来的商品信息,包括商品名称、价格、型号、星级和商品链接。
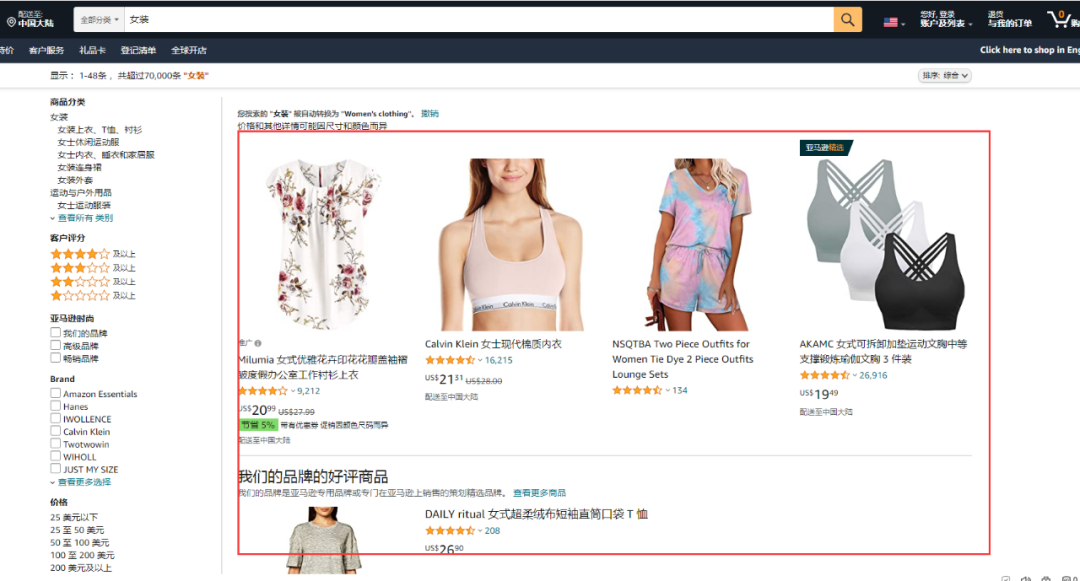
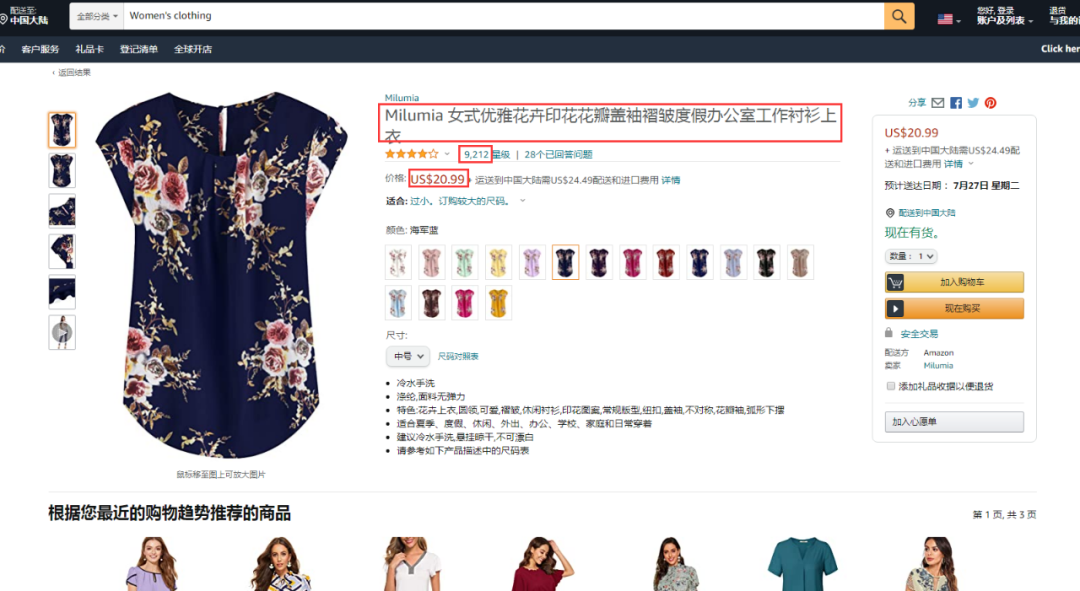
l 思路分析

l 配置步骤
一.新建采集任务
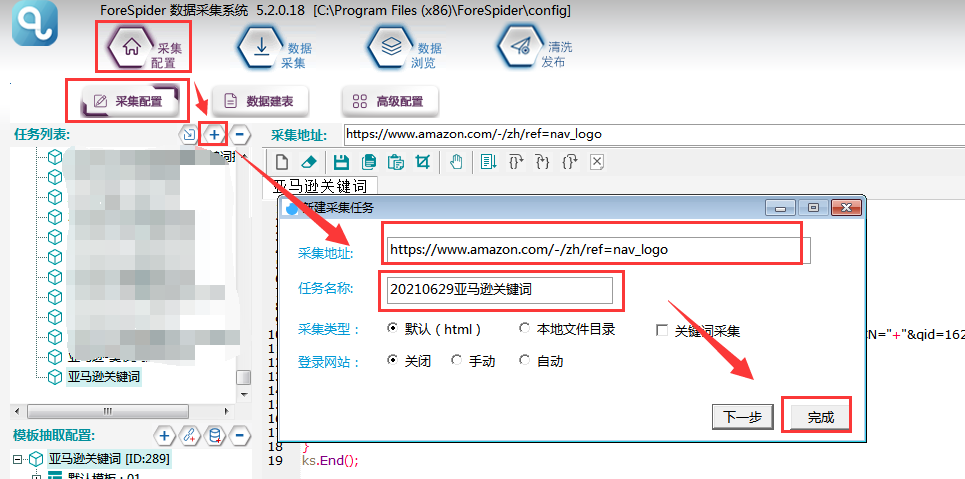
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
二.关键词配置及翻页链接
1.查找规律
在亚马逊首页页搜索不同关键词,发现不同关键词搜索结果的链接,只更换了图中红框部分,而红框部分正是经过转码后的关键词。
关键词为:女装第一页链接
https://www.amazon.com/-/zh/s?k=%E5%A5%B3%E8%A3%85&page=2&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&qid=1624952544&ref=sr_pg_1
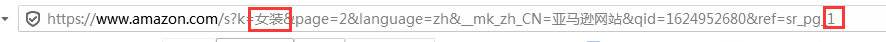
关键词为:女装第二页链接
https://www.amazon.com/s?k=%E5%A5%B3%E8%A3%85&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&ref=nb_sb_noss_2

关键词为:男装第一页链接
https://www.amazon.com/s?k=%E7%94%B7%E8%A3%85&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&ref=nb_sb_noss_1
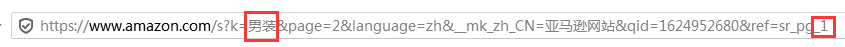
关键词为:男装第二页链接
https://www.amazon.com/s?k=%E7%94%B7%E8%A3%85&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&ref=nb_sb_noss_2
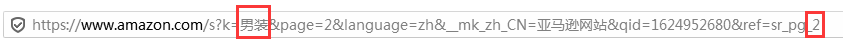
说明不同关键词和页数搜索出来的链接规律为
https://www.amazon.com/s?k=【关键词转码】&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&ref=nb_sb_noss_【页数】
2.高级配置
得到关键词链接拼接规则后,开始配置关键词搜索:
点击屏幕右下角【高级配置】,将采集地址填写到【请求地址】中,点击【+】添加一个参数,名称可以自定义。
此项配置是用于后期脚本能将关键词从关键词列表中取出,配置完成点击【确定】即可。

3.设置搜索关键词
在关键词列表添加多个关键词用英文分号或换行隔开。

4.新建脚本
关键词需要写脚本,新建一个脚本,如下所示:
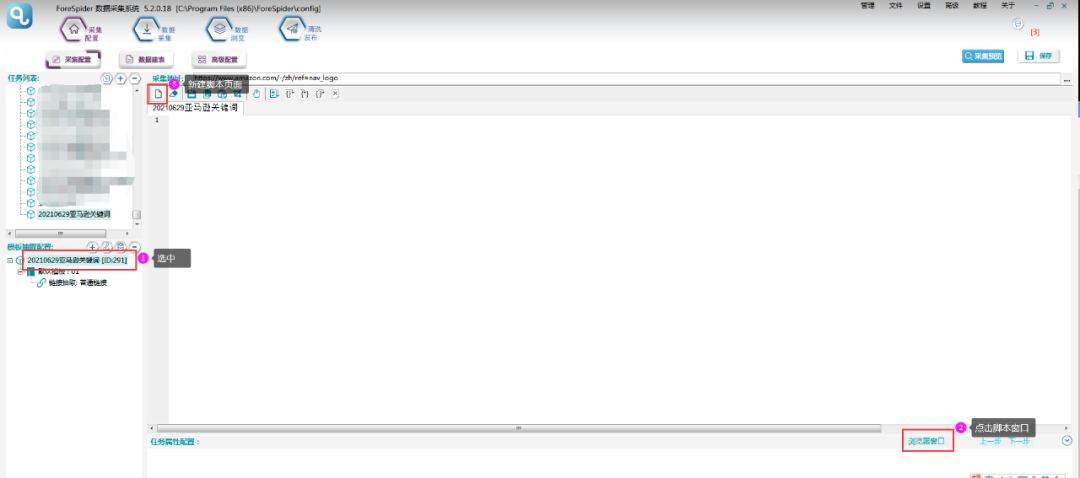
5.脚本配置
根据刚才的链接规律,具体配置脚本如下:
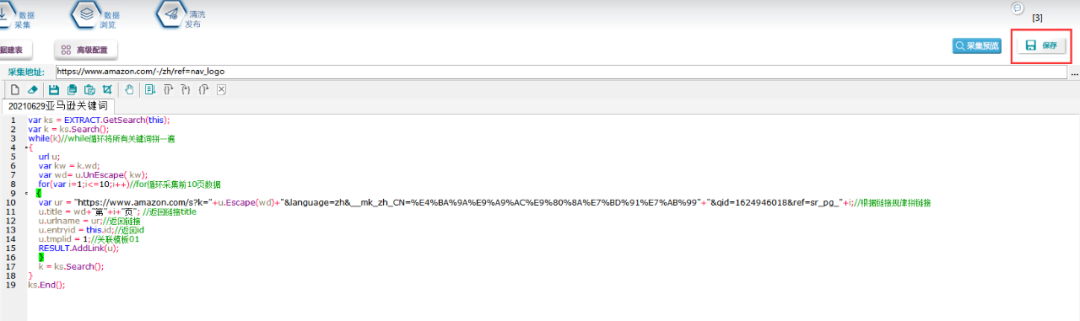
脚本文本如下:
var ks = EXTRACT.GetSearch(this);var k = ks.Search();while(k)//while循环将所有关键词拼一遍{url u;var kw = k.wd;var wd= u.UnEscape( kw);for(var i=1;i<=10;i++)//for循环采集前10页数据{var ur = "https://www.amazon.com/s?k="+u.Escape(wd)+"&language=zh&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99"+"&qid=1624946018&ref=sr_pg_"+i;//根据链接规律拼链接u.title = wd+"第"+i+"页"; //返回链接titleu.urlname = ur;//返回链接u.entryid = this.id;//返回idu.tmplid = 1;//关联模板01RESULT.AddLink(u);}k = ks.Search();}ks.End();
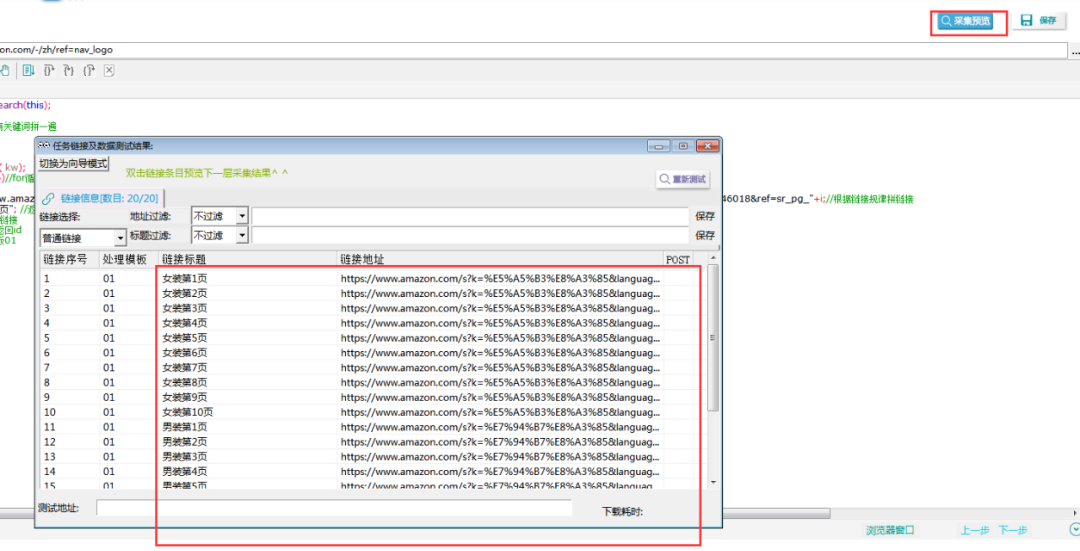
6.效果预览:
点击【采集预览】,即可看到配置效果。
三.商品链接抽取
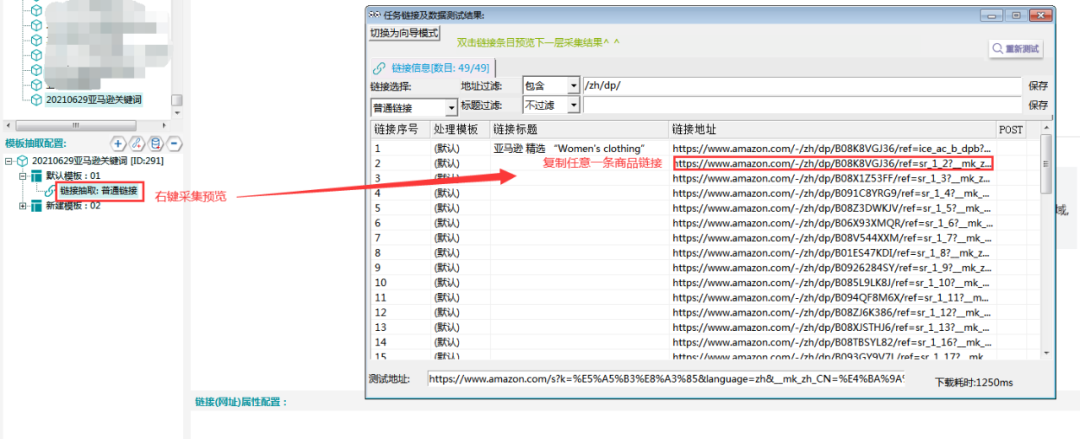
1.从采集预览中任意复制一条链接。
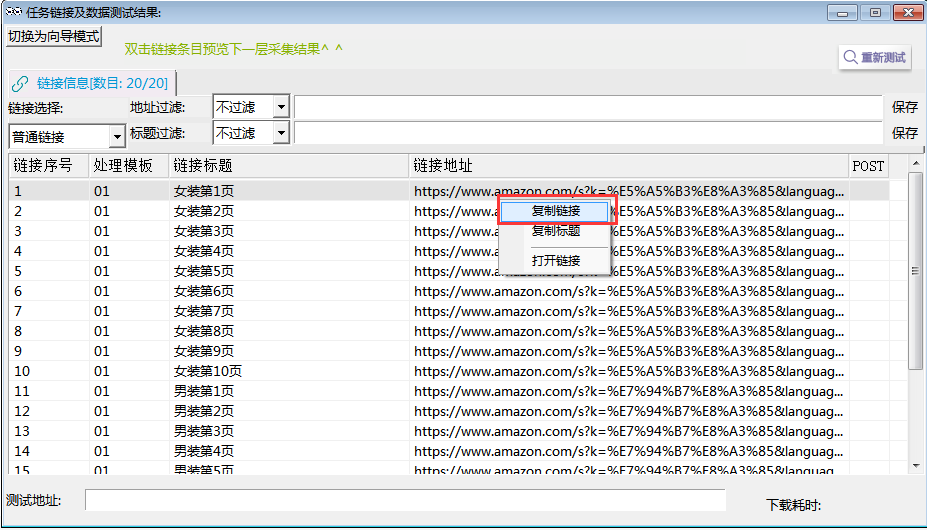
2.将链接复制到默认模板01的示例地址中。

3.右击采集预览,可以看到爬虫抓取出来的所有链接。

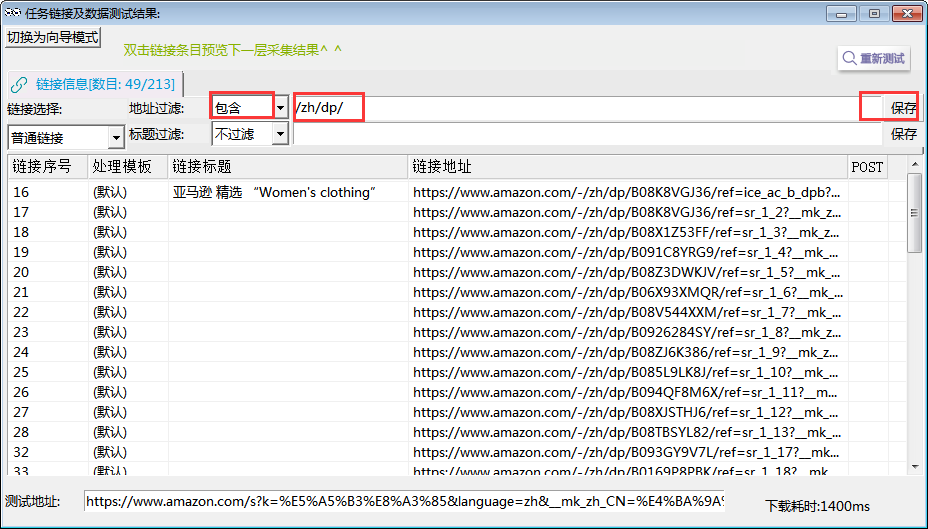
4.观察发现,这些链接就是关键词搜索出来的商品链接。并且链接中都含有【/zh/dp/】。

5.选择地址过滤,选择【包含】,填入【/zh/dp/】,点击保存。则筛选出所有商品链接,商品链接就抽取出来了。
6.关联模板,将模板01链接抽取关联至模板02,具体操作如下图所示:
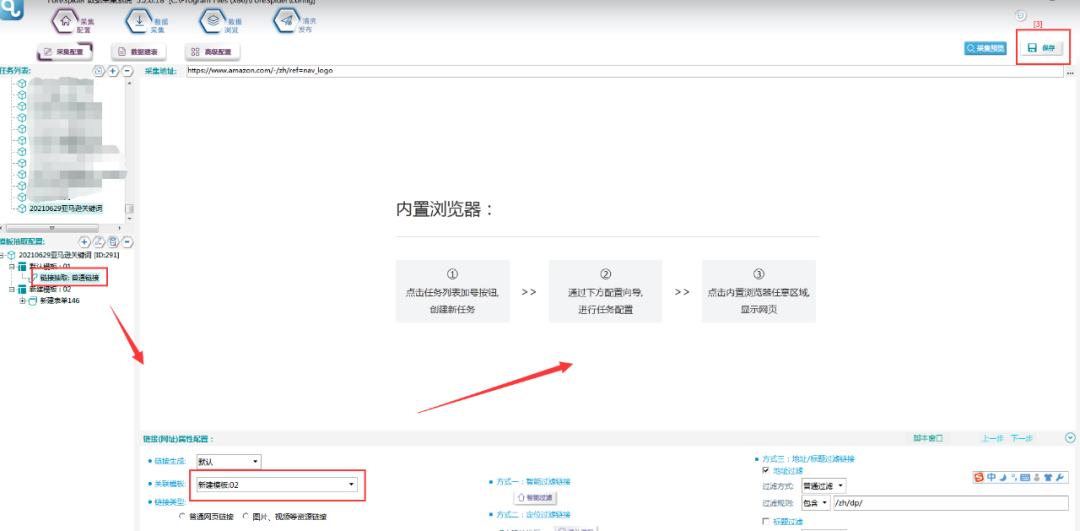
四.商品数据抽取
1.新建数据抽取
新建模板02,在模板02下建一个数据抽取,具体操作如下图所示。

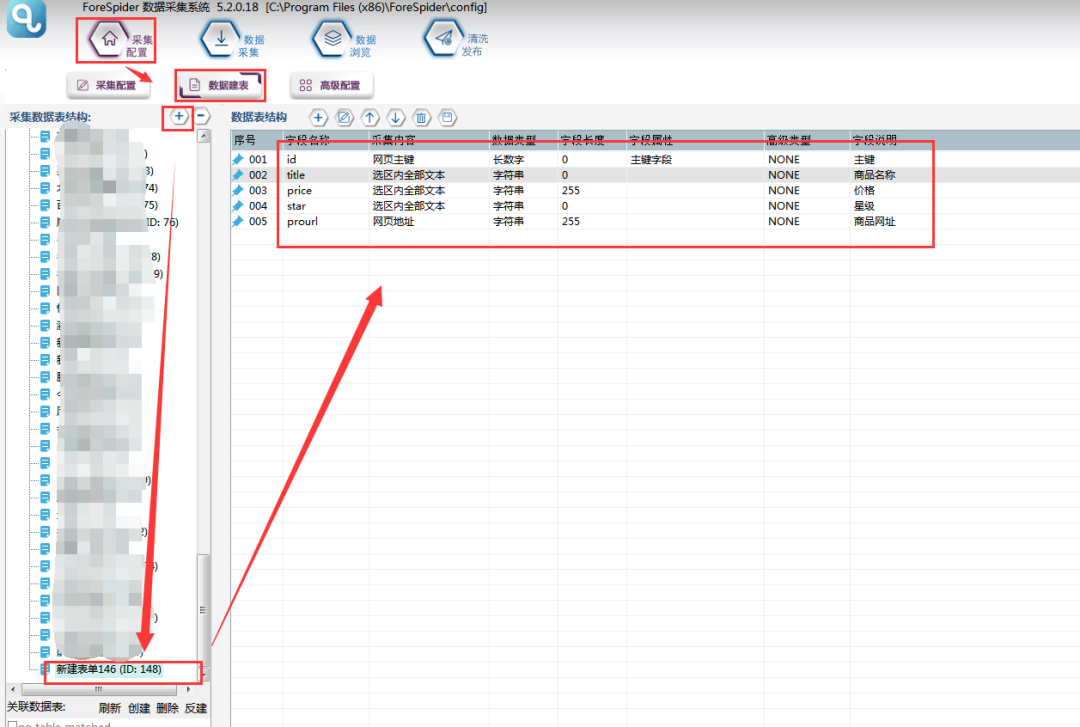
2.数据建表
点击图中加号,新建一个数据表,然后添加字段,各字段属性如下图所示:
3.关联表单
将新建好的数据表,关联到模板中去,如下图所示:

4.填写示例地址
从采集预览中任意复制一条商品的链接,填写到模板02的示例地址中。

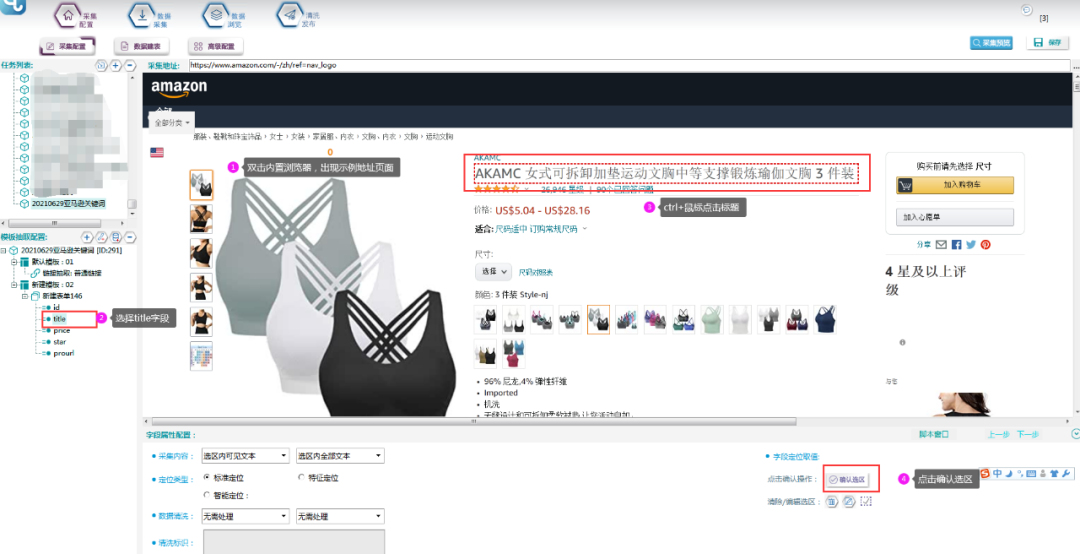
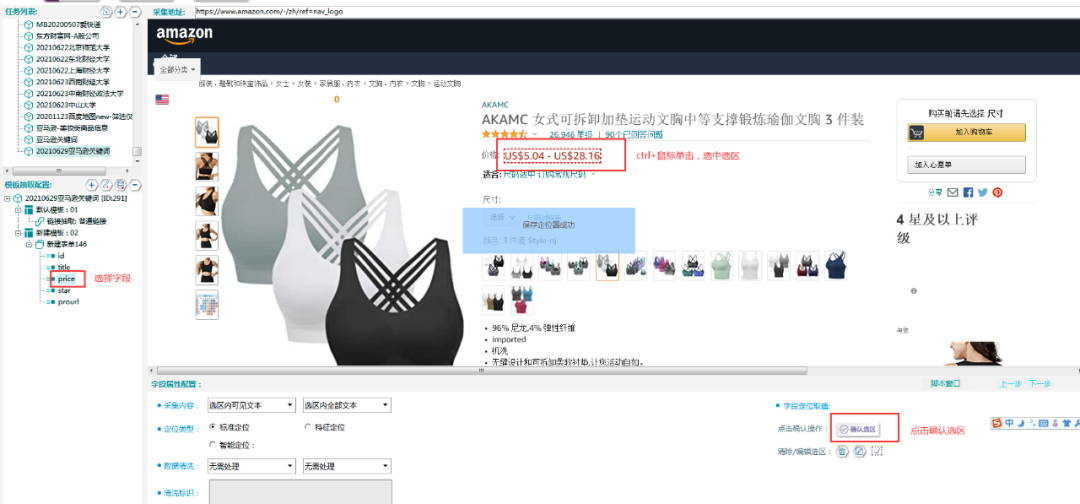
5.字段抽取
字段抽取使用定位抽取的方法,选中选区后,点击【确认选区】按钮即可。

6.采集预览
如下图所示,一层一层双击,进入最后数据页,即取到了数据。

l 采集步骤
模板配置完成,采集预览没有问题后,可以进行数据采集。
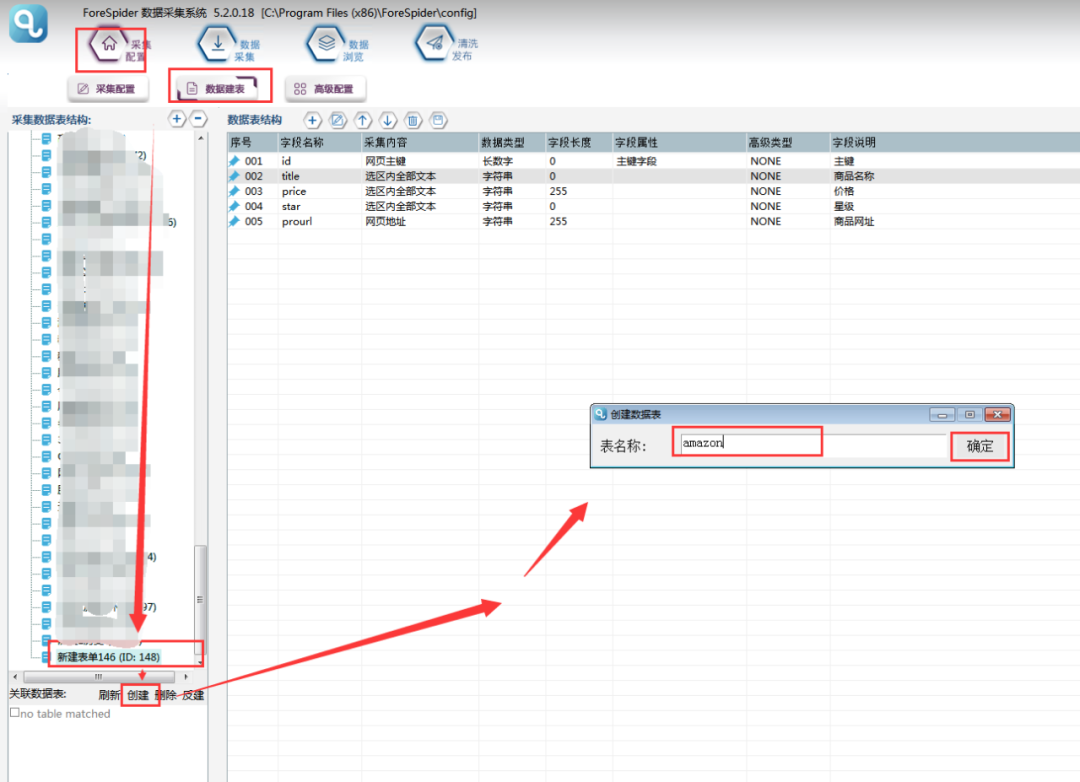
1.建立采集数据表
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为amazon(注意命名不能用数字和特殊符号),点击【确定】。
2.关联数据表
创建完成,勾选数据表并保存。

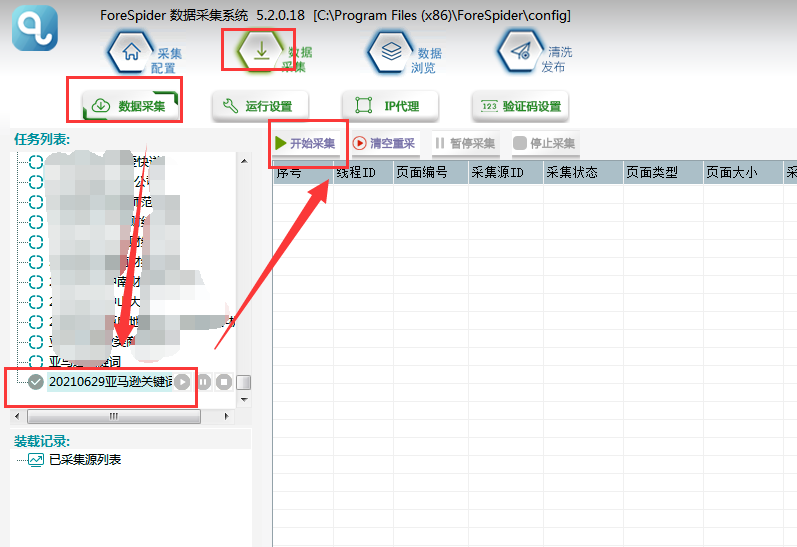
3.开始采集
选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
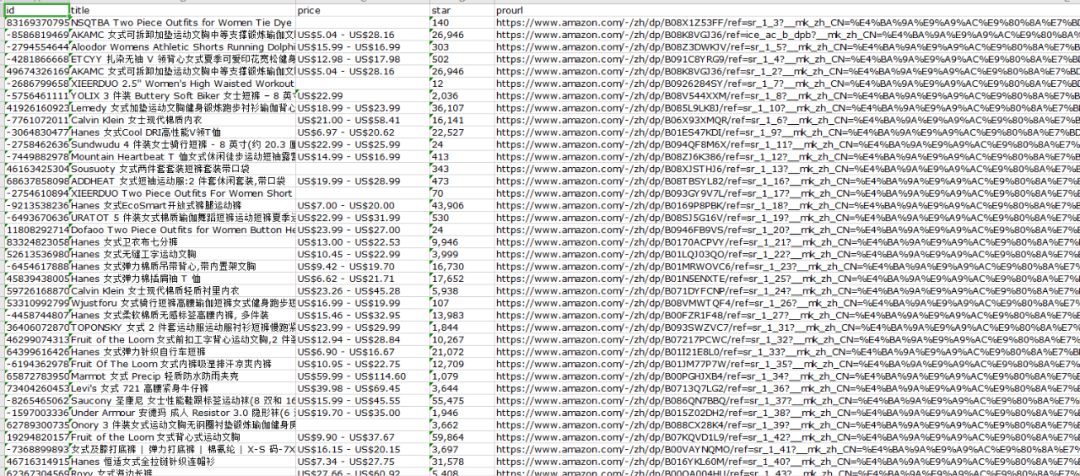
4.导出数据
可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。


导出的文件打开如下图所示:
这篇关于【从零开始学爬虫】采集亚马逊商品信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








