本文主要是介绍【从零开始学爬虫】采集全国航班信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
l 采集网站
【场景描述】采集全国航班信息。
【入口网址】http://www.esk365.com/tools/gnhb/
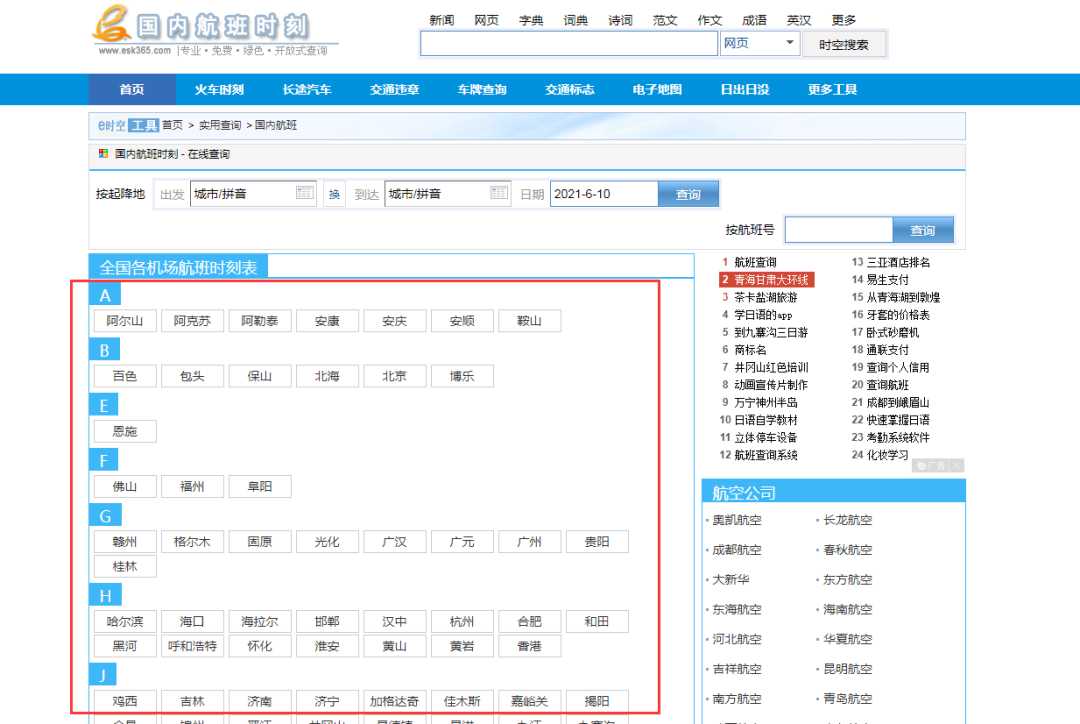
【采集内容】采集全国航班的航班号,起点、终点。

l 思路分析
配置思路概览:

l 配置步骤
一.新建采集任务
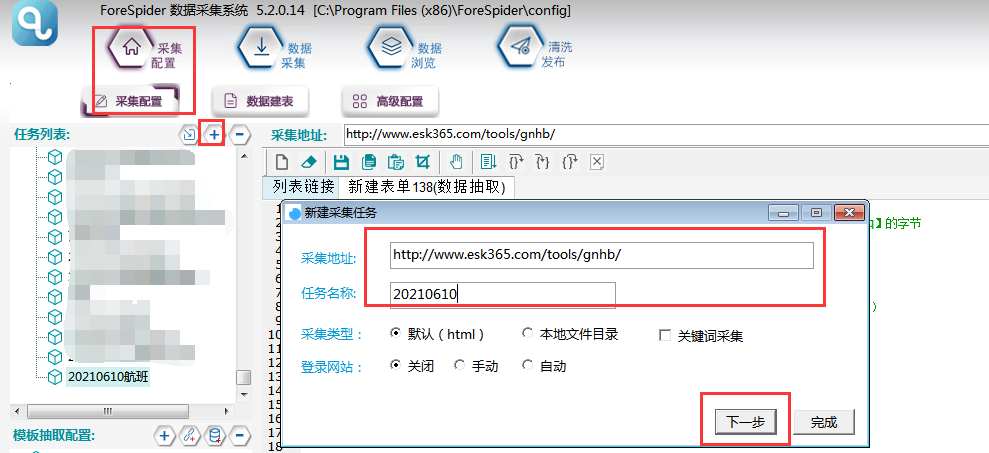
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
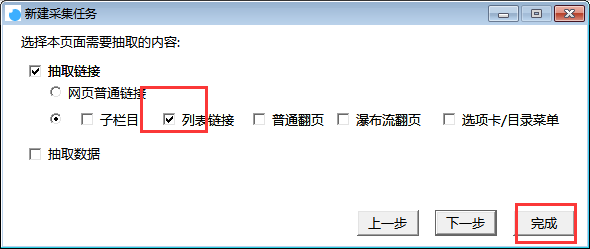
二.链接抽取
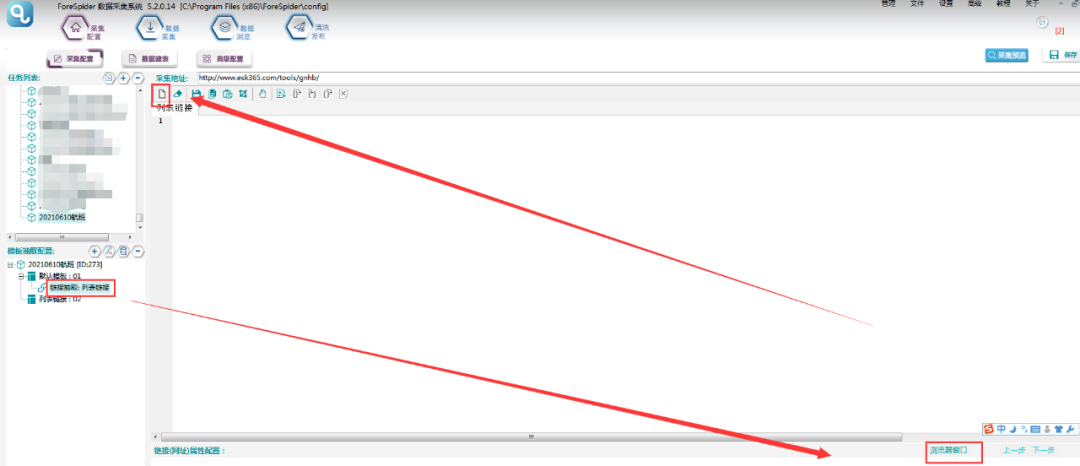
1.列表链接需要脚本配置,操作如下图所示:
2.查看页面源码,打开浏览器中该页面,点击F12,点击指针按钮,如下图所示,用指针按钮选中所需要的地点链接,这时在右侧出现对应源码内容。观察发现所需要的地点链接,在class为【p_l2】的节点后的class为【wq ws】的节点下的class为【fa_wk3】的节点中。
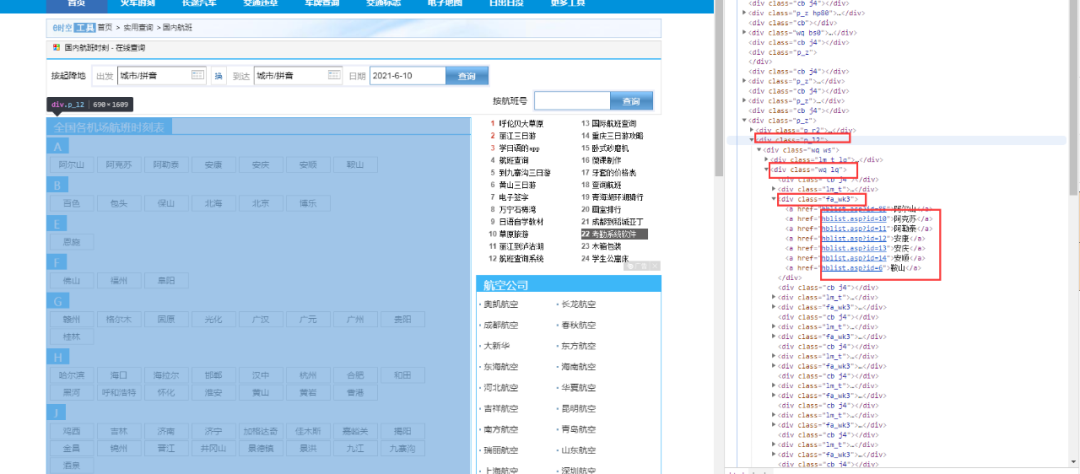
3.根据以上思路,具体配置脚本如下,配置好脚本后点击右上角【保存】。
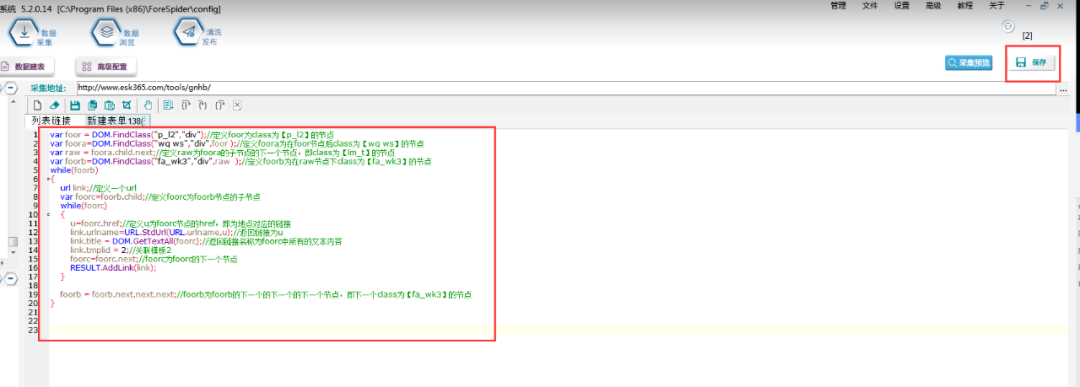
脚本文本如下:
var foor = DOM.FindClass("p_l2","div");//定义foor为class为【p_l2】的节点
var foora=DOM.FindClass("wq ws","div",foor );//定义foora为在foor节点后class为【wq ws】的节点
var raw = foora.child.next;//定义raw为foora的子节点的下一个节点,即class为【lm_t】的节点
var foorb=DOM.FindClass("fa_wk3","div",raw );//定义foorb为在raw节点下class为【fa_wk3】的节点
while(foorb)
{url link;//定义一个urlvar foorc=foorb.child;//定义foorc为foorb节点的子节点while(foorc){u=foorc.href;//定义u为foorc节点的href,即为地点对应的链接link.urlname=URL.StdUrl(URL.urlname,u);//返回链接为ulink.title = DOM.GetTextAll(foorc);//返回链接名称为foorc中所有的文本内容link.tmplid = 2;//关联模板2foorc=foorc.next;//foorc为foorc的下一个节点RESULT.AddLink(link);}foorb = foorb.next.next.next;//foorb为foorb的下一个的下一个的下一个节点,即下一个class为【fa_wk3】的节点
}⑥采集预览如下所示:
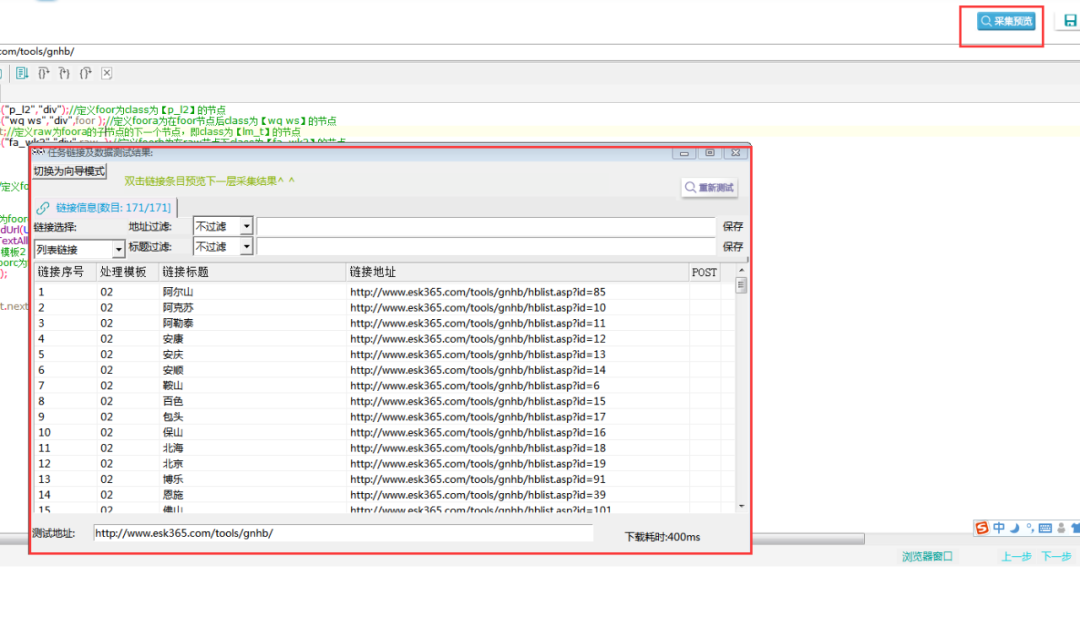
三. 数据抽取
1.链接抽取完成进入数据页,在模板02中,添加数据抽取,具体操作如下所示:
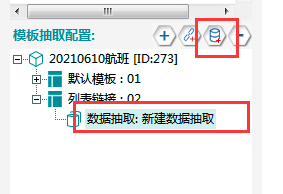
2.此时要完成数据建表的工作:选择【数据建表】,点击【采集数据表结构】中的【+】,即可添加数据表,名称可以自定义,在此命名为房天下表单。
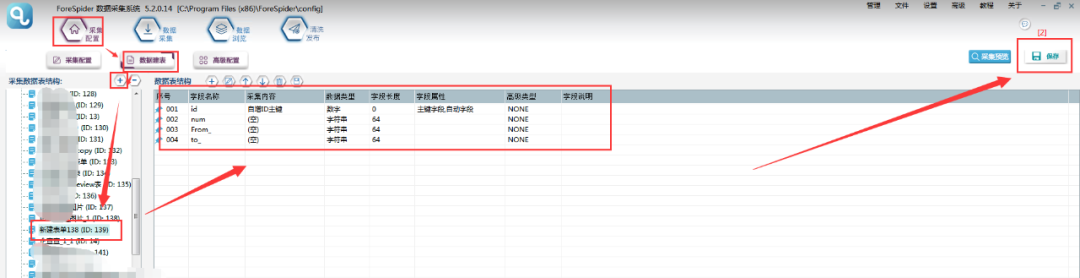
3.数据表配置完成,选择【数据抽取】右侧数据属性配置,表单选择刚建立的数据表,则可看到表单中的字段在左侧显示。
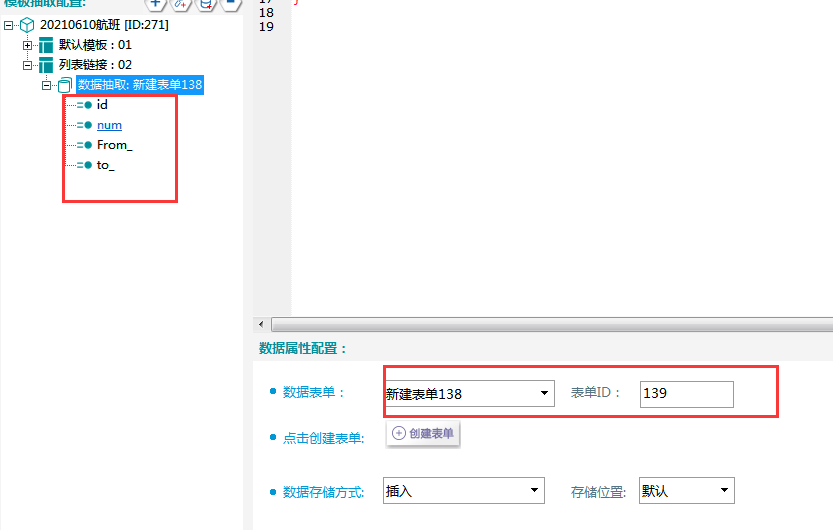
4.点击脚本窗口,选择数据抽取脚本
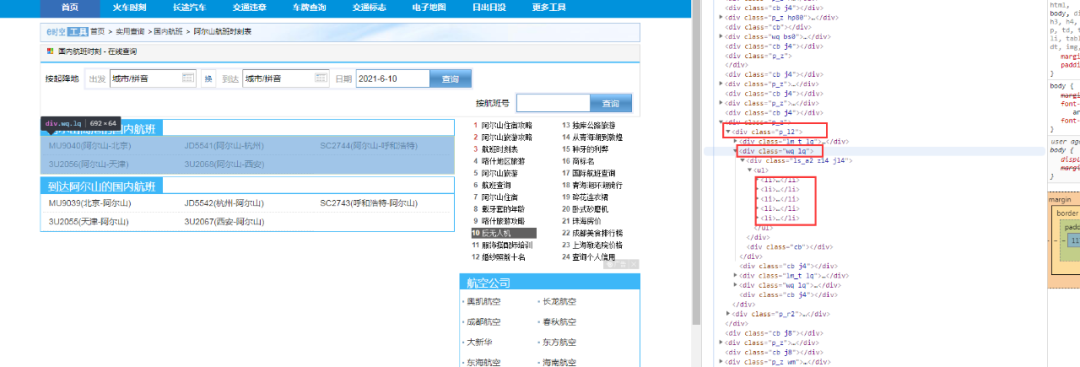
5.观察所需字段在页面中的位置,浏览器打开任意一个地点分类的详情页,点击F12,点击指针按钮,如下图所示,用指针按钮选中所需要的字段信息,这时在右侧出现对应源码内容。
观察可发现,所需的航班数据就在class为【p_l2】后的class为【wq lq】的字节下的所有class为【li】的字节中。
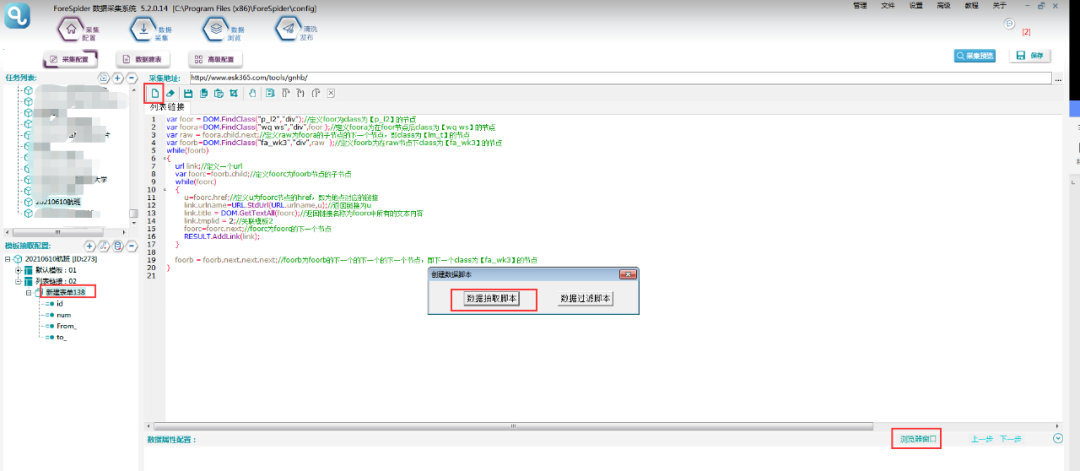
6.根据上述结构,数据抽取脚本如下所示:
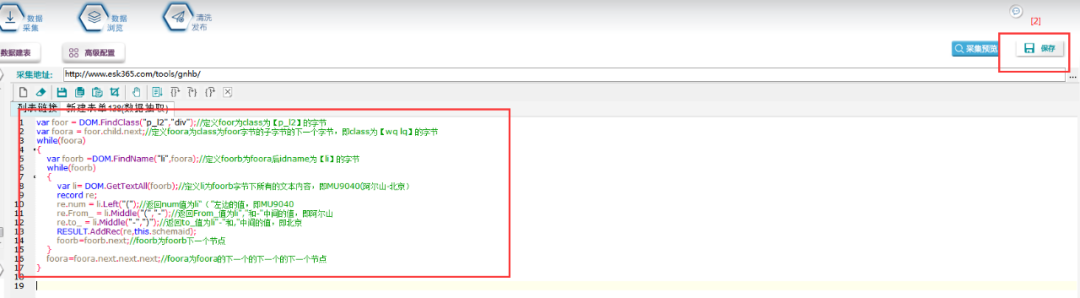
脚本文本如下:
var foor = DOM.FindClass("p_l2","div");//定义foor为class为【p_l2】的字节
var foora = foor.child.next;//定义foora为class为foor字节的子字节的下一个字节,即class为【wq lq】的字节
while(foora)
{var foorb =DOM.FindName("li",foora);//定义foorb为foora后idname为【li】的字节while(foorb){var li= DOM.GetTextAll(foorb);//定义li为foorb字节下所有的文本内容,即MU9040(阿尔山-北京)record re;re.num = li.Left("(");//返回num值为li“(”左边的值,即MU9040re.From_ = li.Middle("(","-");//返回From_值为li","和-"中间的值,即阿尔山re.to_ = li.Middle("-",")");//返回to_值为li"-"和,"中间的值,即北京RESULT.AddRec(re,this.schemaid);foorb=foorb.next;//foorb为foorb下一个节点}foora=foora.next.next.next;//foora为foora的下一个的下一个的下一个节点
}7.以上完成全部字段配置,效果预览如下:
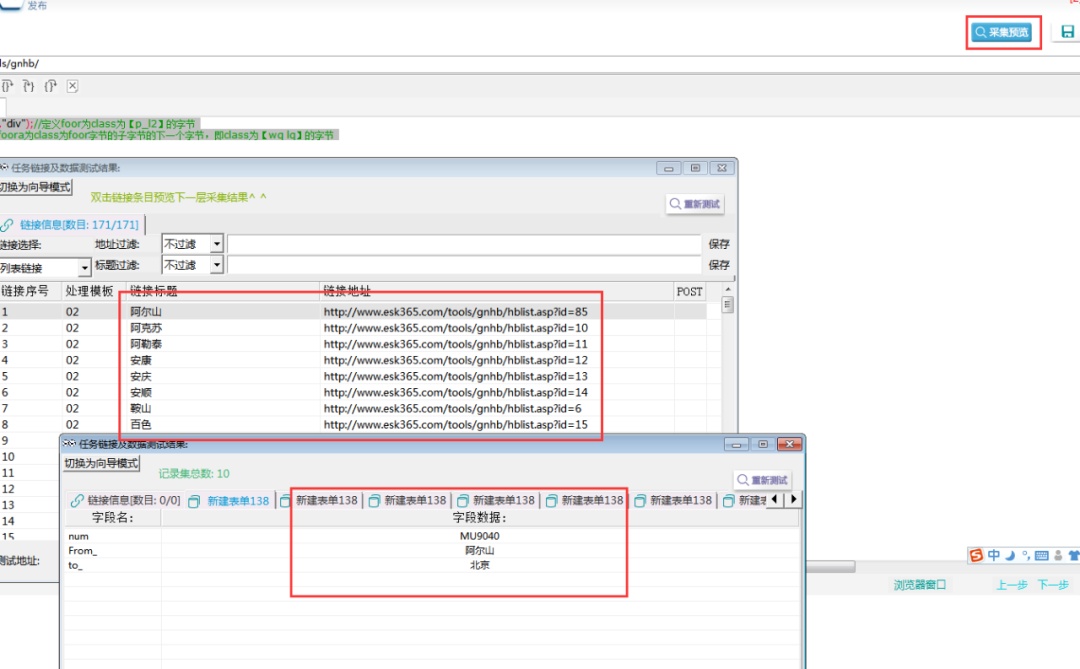
四.采集数据
模板配置完成,采集预览没有问题后,可以进行数据采集。
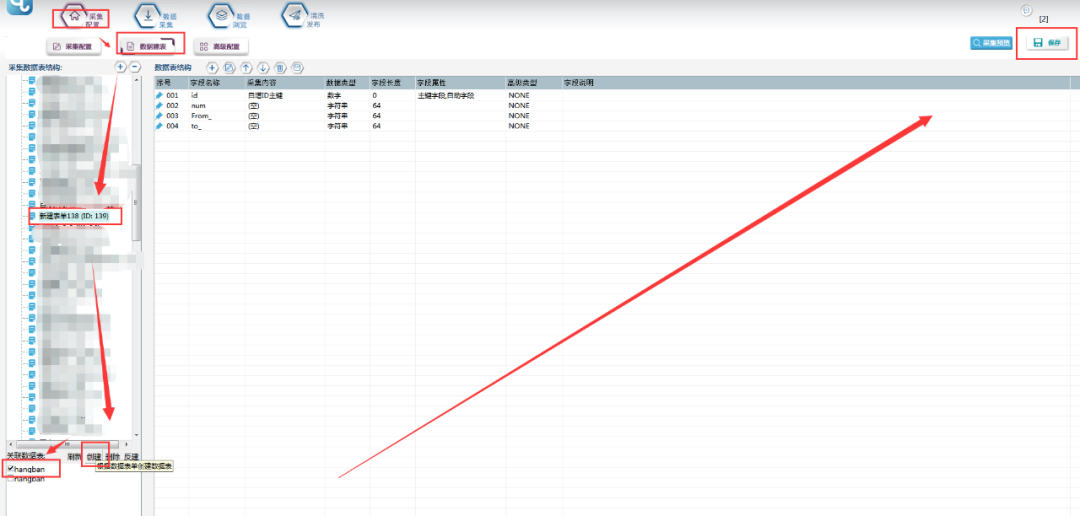
1.新建采集数据表:
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为hangban(注意命名不能用数字和特殊符号),点击【确定】。
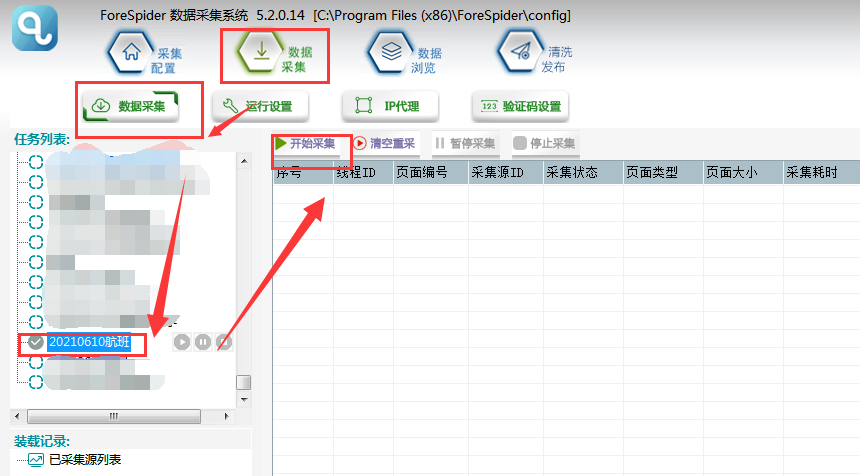
2.选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
3.可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。
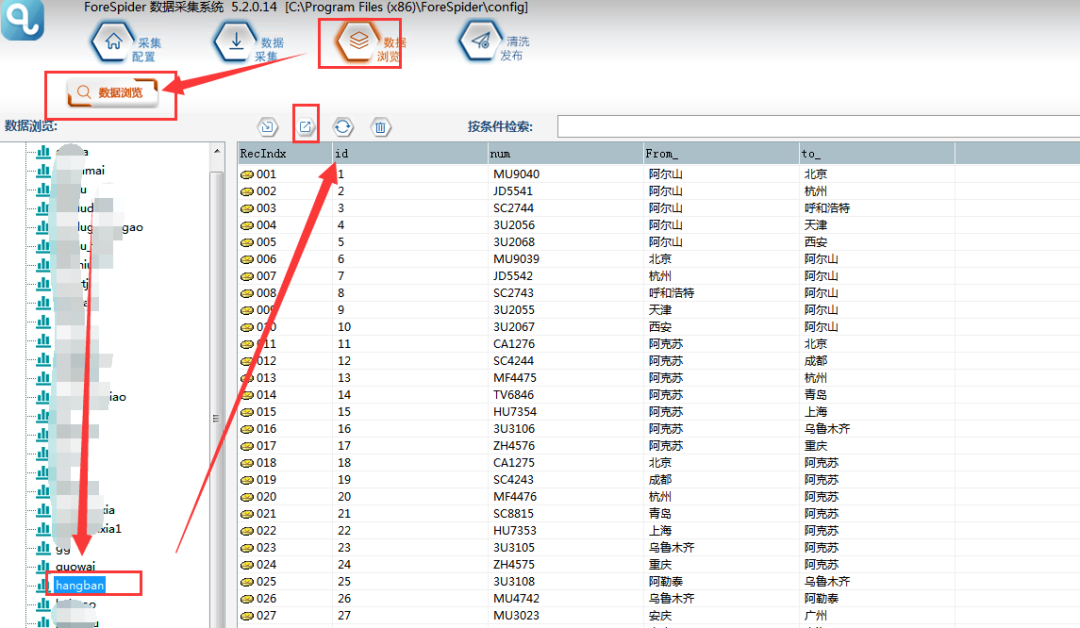
l 课后回顾
FindClass(class名,标签类型,开始查找结点):当符合条件的class名称唯一时,使用class名来查找结点。
FindName(标签名,开始查找结点):当查找范围内,符合条件的数据标签唯一时,可以使用标签名称查找标签结点。
GetTextAll(需要获取文本的结点,使用的字符编码):获取该html标签节点及所有子节点的可见文本。
Child:孩子频道节点。
Next:下一频道节点。
FindId(idVal):通过标签的ID属性值查找标签节点,其中idVal表示待查找标签ID属性值。
Left(分界字符):获得该字符串分解字符左侧所有内内容。

这篇关于【从零开始学爬虫】采集全国航班信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








