本文主要是介绍爬取京东本周热卖商品所有用户评价存入MySQL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取京东本周热卖商品所有用户评价存入MySQL
说明
本项目是对(爬取京东本周热卖商品基本信息存入MySQL)项目的追加,所以会有一些内容上的衔接,例如工具的使用方法等在此篇就不赘述,大家可以直接去看上一个项目中的介绍。爬取京东本周热卖商品基本信息存入MySQL的链接:http://blog.csdn.net/u011204847/article/details/51292512
项目简介
需求概要
1、按照下面所述进入京东本周热卖页面,抓取本周热卖页面所有商品链接。
2、抓取评价中的商品评价、用户印象、全部评价。
3、将抓取的所有信息存入设计好的MySQL表中。
注意事项
1、由于抓取多个页面,所以需要用多线程。
2、京东商品的价格以及评价都是通过JS异步传输的,所以从网页源码中无法获取商品这些信息,需要用调试工具加载页面所有内容,然后找到JS异步传输所请求的URL,然后继续请求并获取Response(商品价格和评价)。
3、我所使用的环境为浏览器(Chrome)、IDE(Eclipse)、项目(Maven)、Maven依赖(junit4.12、httpclient 4.4、htmlcleaner2.10、json 20140107)。
4、依赖中的httpclient、htmlcleaner、json的版本最好使用我所指定的,其他的版本很容易出现问题。同时获取XPath最好用Chrome抓,火狐等容易出错。
5、抓取日期为2016/4/30日,京东页面以后很可能会改动,所以这套代码之后可能抓不到正确数据。所以大家要注重爬取过程和原理。
6、由于我对每个页面用了一个线程,所以爬取的商品超过100的时候,插入商品信息到数据库时,可能会出现超过MySQL最大连接数错(默认100),可以在配置文件my.ini中修改(打开 MYSQL 安装目录,打开 my.ini 找到 max_connections ,默认是 100, 一般设置到500~1000比较合适,然后重启MySQL)。
爬取的页面导航
首先进入京东首页,然后鼠标移到全部商品分类—》电脑、办公—》玩3C—》本周热卖。
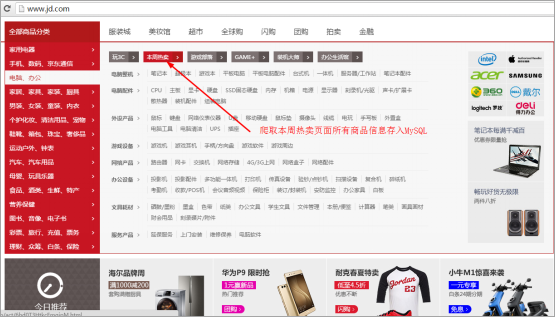
进入本周热卖(要抓取的网页,抓取这个页面所有商品的所有评价)
获取商品评价流程
1、商品页面:(通过本周热卖的第二个商品[雷蛇鼠标]进行测试)
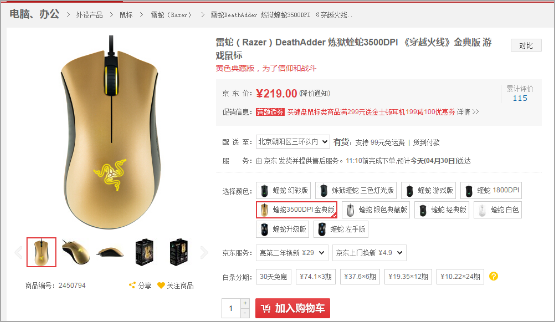
商品评价页面展示:
2、查找JS异步获取评价所请求的URL(具体步骤见下图)
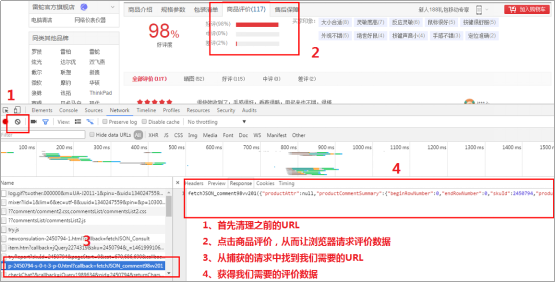
3、得到初始URL:http://club.jd.com/productpage/p-2450794-s-0-t-3-p-0.html?callback=fetchJSON_comment98vv201
去除不需要的后缀 ?callback=fetchJSON_comment98vv201 之后,在URL中请求到的结果为:
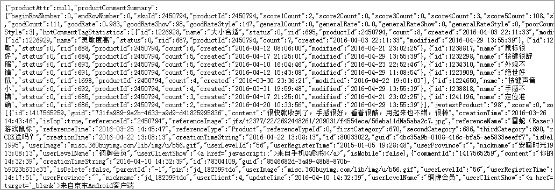
这是一个比较大的Json格式字符串,里面包含了商品评价的所有内容。
通过Json解析器查看结果为:
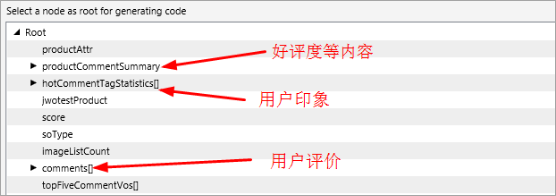
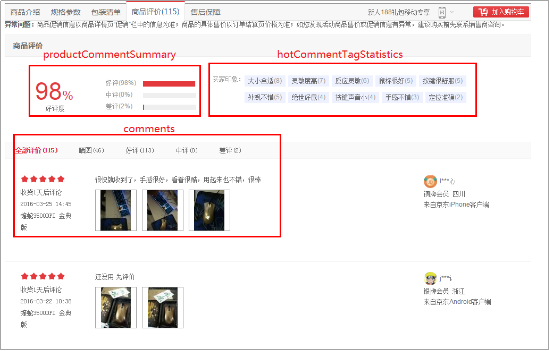
之后我们的任务就是使用代码解析获得的数据。分别解析好评度、用户印象、用户评价。
获取商品评价好评度
1、商品好评度处的Json字符串:
"productCommentSummary":{"beginRowNumber":0,"endRowNumber":0,"skuId":2450794,"productId":2450794,"score1Count":2,"score2Count":0,"score3Count":0,"score4Count":3,"score5Count":108,"showCount":25,"commentCount":113,"averageScore":5,"goodCount":111,"goodRate":0.983,"goodRateShow":98,"goodRateStyle":147,"generalCount":0,"generalRate":0.0,"generalRateShow":0,"generalRateStyle":0,"poorCount":2,"poorRate":0.017,"poorRateShow":2,"poorRateStyle":3}
2、代码和打印结果:
代码示例:
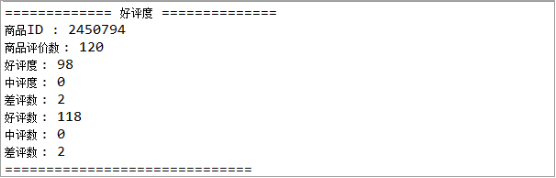
@Test //单元测试 :解析商品评价详情中的=》好评度
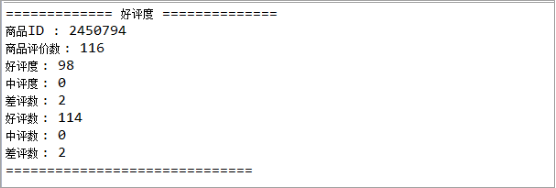
public void test12() {String url = "http://club.jd.com/productpage/p-2450794-s-0-t-3-p-0.html";String content = SpiderUtils.download(url);JSONObject jsonObject = new JSONObject(content);Object Obj = jsonObject.get("productCommentSummary");JSONObject j_Obj = new JSONObject(Obj.toString());System.out.println("============= 好评度 ==============");Object productId = j_Obj.get("productId"); //商品IDObject commentCount = j_Obj.get("commentCount"); //商品评价数Object goodRateShow = j_Obj.get("goodRateShow"); //好评度Object generalRateShow = j_Obj.get("generalRateShow"); //中评度Object poorRateShow = j_Obj.get("poorRateShow"); //差评度Object goodCount = j_Obj.get("goodCount"); //好评数Object generalCount = j_Obj.get("generalCount"); //中评数Object poorCount = j_Obj.get("poorCount"); //差评数System.out.println("商品ID : " + productId.toString());System.out.println("商品评价数 : " + commentCount.toString());System.out.println("好评度 : " + goodRateShow.toString());System.out.println("中评度 : " + generalRateShow.toString());System.out.println("差评数 : " + poorRateShow.toString());System.out.println("好评数 : " + goodCount.toString());System.out.println("中评数 : " + generalCount.toString());System.out.println("差评数 : " + poorCount.toString());System.out.println("==============================");}打印结果:
获取商品评价买家印象
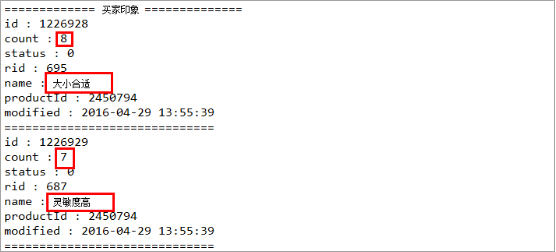
1、用户印象页面示例

2、用户印象也是包含在上面请求的URL返回的Json字符串中。并且不同的商品,买家印象不同,但是它们的个数都是10。所以当要获取所有商品的这些数据时,用户印象不可以写死。
3、代码和打印结果:
代码示例:
@Test //解析商品评价详情中的=》买家印象
public void test4() {String url = "http://club.jd.com/productpage/p-2450794-s-0-t-3-p-0.html";String content = SpiderUtils.download(url);JSONObject jsonObject = new JSONObject(content);Object object = jsonObject.get("hotCommentTagStatistics");JSONArray jsonArray = new JSONArray(object.toString());System.out.println("============= 买家印象 ==============");for (int i = 0; i < jsonArray.length(); i++) {JSONObject j_Obj = jsonArray.getJSONObject(i);Object id = j_Obj.get("id");Object count = j_Obj.get("count");Object status = j_Obj.get("status");Object rid = j_Obj.get("rid");Object name = j_Obj.get("name");Object productId = j_Obj.get("productId");Object modified = j_Obj.get("modified");System.out.println("id : " + id.toString());System.out.println("count : " + count.toString());System.out.println("status : " + status.toString());System.out.println("rid : " + rid.toString());System.out.println("name : " + name.toString());System.out.println("productId : " + productId.toString());System.out.println("modified : " + modified.toString());System.out.println("==============================");}}打印结果:
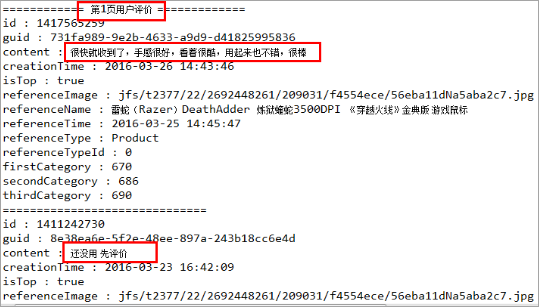
获取所有用户评价
1、用户评价页面展示
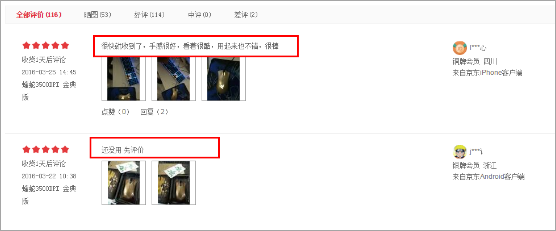
2、用户评价每页为10个,有很多页。例如:
第一页:http://club.jd.com/productpage/p-2450794-s-0-t-3-p-0.html
第二页:http://club.jd.com/productpage/p-2450794-s-0-t-3-p-1.html
它们只有p后面的值不同,我们可以通过评价总数计算出页面总数,然后抓取所有页。
3、代码和打印结果
代码示例:
@Test //解析商品评价详情中的=》用户评价
public void test5() {//获取评论总数int count = getCommentCount();//通过评论总数计算页面总数int pageCount = count / 10 + 1;//遍历打印每个页面的评论for (int j = 0; j < pageCount; j++) {//拼接JS异步请求的URLString url = "http://club.jd.com/productpage/p-2450794-s-0-t-3-p-" + j + ".html";//获取请求的数据String contents = SpiderUtils.download(url);//把返回的Json字符串转化为Json对象JSONObject jsonObject = new JSONObject(contents);//获取Json对象中commonts对应的值String val = jsonObject.get("comments").toString();//commonts对应的值为Json数组字符串,转化为Json数组JSONArray jsonArray = new JSONArray(val);System.out.println("============ 第" + (j + 1) + "页用户评价 =============");//遍历打印每页用户评价for (int i = 0; i < jsonArray.length(); i++) {JSONObject j_Obj = jsonArray.getJSONObject(i);Object id = j_Obj.get("id");Object guid = j_Obj.get("guid");Object content = j_Obj.get("content");Object creationTime = j_Obj.get("creationTime");Object isTop = j_Obj.get("isTop");Object referenceImage = j_Obj.get("referenceImage");Object referenceName = j_Obj.get("referenceName");Object referenceTime = j_Obj.get("referenceTime");Object referenceType = j_Obj.get("referenceType");Object referenceTypeId = j_Obj.get("referenceTypeId");Object firstCategory = j_Obj.get("firstCategory");Object secondCategory = j_Obj.get("secondCategory");Object thirdCategory = j_Obj.get("thirdCategory");System.out.println("id : " + id.toString());System.out.println("guid : " + guid.toString());System.out.println("content : " + content.toString());System.out.println("creationTime : " + creationTime.toString());System.out.println("isTop : " + isTop.toString());System.out.println("referenceImage : " + referenceImage.toString());System.out.println("referenceName : " + referenceName.toString());System.out.println("referenceTime : " + referenceTime.toString());System.out.println("referenceType : " + referenceType.toString());System.out.println("referenceTypeId : " + referenceTypeId.toString());System.out.println("firstCategory : " + firstCategory.toString());System.out.println("secondCategory : " + secondCategory.toString());System.out.println("thirdCategory : " + thirdCategory.toString());System.out.println("==============================");}}
}打印结果:
保存爬取的数据到MySQL
注意事项
1、由于本周热卖每个页面都用一个线程去跑,每个线程都有一个数据库链接,所以Mysql的数据库连接数需要修改大一点。
解决方式:打开 MYSQL 安装目录打开 my.ini 找到 max_connections 默认是 100, 一般设置到500~1000比较合适,然后重启MySQL。
2、这里只是演示爬取数据插入表格,所以表格的设计不是很合理。
3、需要插入的页面模块展示
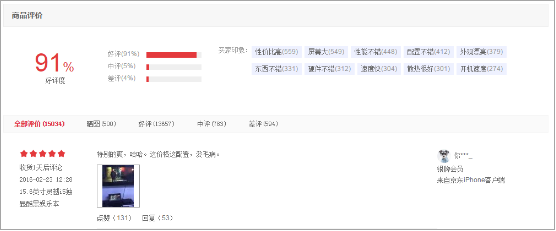
插入好评度信息
1、好评度模块图示:
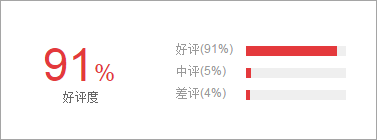
2、数据库表设计
数据表说明:

数据表创建语句:
CREATE TABLE `productCommentSummary` (`id` int(10) NOT NULL AUTO_INCREMENT,`goodId` varchar(20) DEFAULT NULL,`productId` varchar(20) DEFAULT NULL,`commentUrl` varchar(300) DEFAULT NULL,`commentCount` varchar(20) DEFAULT NULL,`goodRateShow` varchar(20) DEFAULT NULL,`generalRateShow` varchar(20) DEFAULT NULL,`poorRateShow` varchar(20) DEFAULT NULL,`goodCount` varchar(20) DEFAULT NULL,`generalCount` varchar(20) DEFAULT NULL,`poorCount` varchar(20) DEFAULT NULL,`current_time` datetime DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;3、代码示例及部分执行结果:
代码示例:
//将每个页面的业务逻辑放在Runnable接口的run()方法中,这样可以调用多线程爬取每个页面。
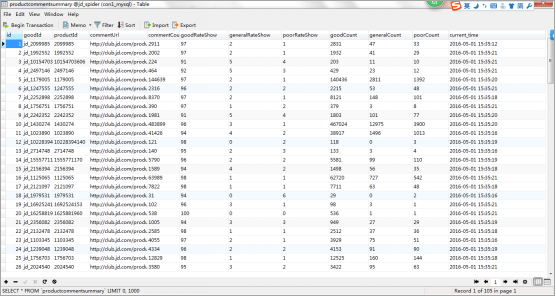
public void run() {//通过构造函数插入的url,然后获取该URL的响应结果String contents = SpiderUtils.download(url);HtmlCleaner htmlCleaner = new HtmlCleaner();//获取所有节点TagNode tn = htmlCleaner.clean(contents);String goodsId = goodsId(tn);//拼接评价信息URL的首页,好评度信息每页都会加载,所以我们只需要爬第一页就行了String url = "http://club.jd.com/productpage/p-" + goodsId + "-s-0-t-3-p-0.html";String content = SpiderUtils.download(url);JSONObject jsonObject = new JSONObject(content);Object Obj = jsonObject.get("productCommentSummary");JSONObject j_Obj = new JSONObject(Obj.toString());//获取好评度中的信息goodsId = "jd_" + goodsId; //商品ID,添加了"jd_"前缀,用于和其他电商数据区分String productId = j_Obj.get("productId").toString(); //商品IDString commentUrl = url; //商品好评度URLString commentCount = j_Obj.get("commentCount").toString(); //商品评价数String goodRateShow = j_Obj.get("goodRateShow").toString(); //好评度String generalRateShow = j_Obj.get("generalRateShow").toString(); //中评度String poorRateShow = j_Obj.get("poorRateShow").toString(); //差评度String goodCount = j_Obj.get("goodCount").toString(); //好评数String generalCount = j_Obj.get("generalCount").toString(); //中评数String poorCount = j_Obj.get("poorCount").toString(); //差评数Date date = new Date();//MyDateUtils是个人封装的工具类String curr_time = MyDateUtils.formatDate2(date);//MyDbUtils是个人封装的工具类MyDbUtils.update(MyDbUtils.INSERT_LOG2, goodsId, productId, commentUrl, commentCount, goodRateShow, generalRateShow, poorRateShow, goodCount, generalCount, poorCount, curr_time);}打印的部分结果对比:
插入数据库后的部分结果:
插入用户印象信息
1、买家印象模块图示:

2、数据库表设计
数据表说明:

数据表创建语句:
CREATE TABLE `hotCommentTagStatistics` (`id` int(10) NOT NULL AUTO_INCREMENT,`goodId` varchar(20) DEFAULT NULL,`productId` varchar(20) DEFAULT NULL,`tagId` varchar(20) DEFAULT NULL,`count` varchar(20) DEFAULT NULL,`status` varchar(10) DEFAULT NULL,`rid` varchar(20) DEFAULT NULL,`name` varchar(50) DEFAULT NULL,`modified` varchar(20) DEFAULT NULL,`current_time` datetime DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;3、代码和部分执行结果:
代码示例:
//将每个页面的业务逻辑放在Runnable接口的run()方法中,这样可以调用多线程爬取每个页面。
public void run() {//通过构造函数插入的url,然后获取该URL的响应结果String contents = SpiderUtils.download(url);HtmlCleaner htmlCleaner = new HtmlCleaner();//获取所有节点TagNode tn = htmlCleaner.clean(contents);String goodsId = goodsId(tn);//拼接评价信息URL的首页,用户印象信息每页都会加载,所以我们只需要爬第一页就行了String url = "http://club.jd.com/productpage/p-" + goodsId + "-s-0-t-3-p-0.html";String content = SpiderUtils.download(url);//我们抓取到的数据为Json字符串格式,所以我们需要对Json数据进行解析JSONObject jsonObject = new JSONObject(content);Object object = jsonObject.get("hotCommentTagStatistics");JSONArray jsonArray = new JSONArray(object.toString());goodsId = "jd_" + goodsId; //加前缀的商品IDfor (int i = 0; i < jsonArray.length(); i++) {JSONObject j_Obj = jsonArray.getJSONObject(i);String productId = j_Obj.get("productId").toString(); //商品IDString tagId = j_Obj.get("id").toString(); //用户某类印象IDString count = j_Obj.get("count").toString(); //用户印象种类数String status = j_Obj.get("status").toString(); //用户某类印象状态String rid = j_Obj.get("rid").toString(); //ridString name = j_Obj.get("name").toString(); //用户某类印象(例如:大小合适,灵敏度高,反应灵敏等)String modified = j_Obj.get("modified").toString(); //一类用户印象最后更新的时间Date date = new Date();//MyDateUtils是个人封装的工具类String curr_time = MyDateUtils.formatDate2(date); //数据插入的时间//MyDbUtils是个人封装的工具类MyDbUtils.update(MyDbUtils.INSERT_LOG3, goodsId, productId, tagId, count, status, rid, name, modified, curr_time);}}打印的部分结果对比:
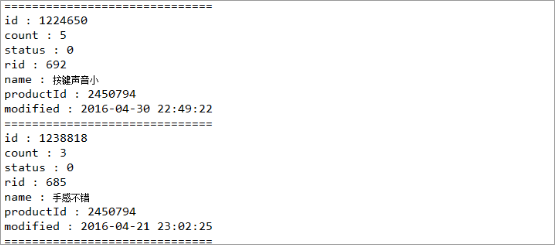
插入数据库的部分结果示例:
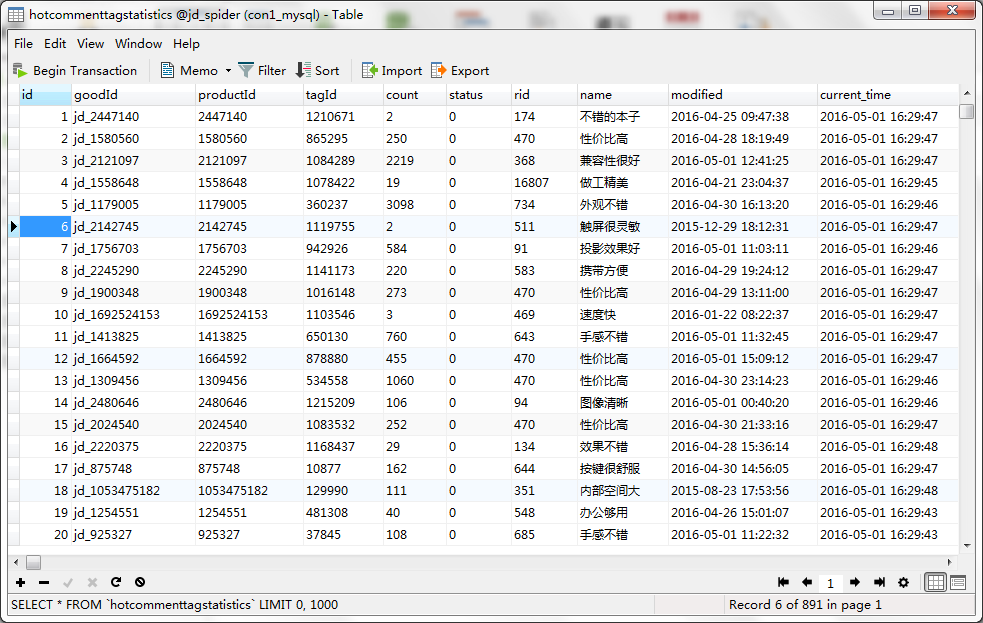
插入用户评价信息
1、用户评价模块图示:
2、数据库表设计
数据表说明:

数据表创建语句:
CREATE TABLE `comments` (`id` int(10) NOT NULL AUTO_INCREMENT,`goodId` varchar(20) DEFAULT NULL,`guid` varchar(50) DEFAULT NULL,`content` text DEFAULT NULL,`creationTime` varchar(50) DEFAULT NULL,`isTop` varchar(10) DEFAULT NULL,`referenceImage` varchar(300) DEFAULT NULL,`referenceName` varchar(300) DEFAULT NULL,`referenceTime` varchar(50) DEFAULT NULL,`referenceType` varchar(50) DEFAULT NULL,`referenceTypeId` varchar(10) DEFAULT NULL,`firstCategory` varchar(20) DEFAULT NULL,`secondCategory` varchar(20) DEFAULT NULL,`thirdCategory` varchar(20) DEFAULT NULL,`current_time` datetime DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
3、代码示例及部分执行结果:
代码示例:
//将每个页面的业务逻辑放在Runnable接口的run()方法中,这样可以调用多线程爬取每个页面。
public void run() {//通过构造函数插入的url,然后获取该URL的响应结果String contents = SpiderUtils.download(url);HtmlCleaner htmlCleaner = new HtmlCleaner();//获取所有节点TagNode tn = htmlCleaner.clean(contents);String goodsId = goodsId(tn);//拼接评价信息URL的首页,好评度信息每页都会加载,所以我们只需要爬第一页就行了String url = "http://club.jd.com/productpage/p-" + goodsId + "-s-0-t-3-p-0.html";//获取商品评价总数,然后除以每页评价数10,拼出总页数String content1 = SpiderUtils.download(url);JSONObject jsonObject = new JSONObject(content1);Object Obj = jsonObject.get("productCommentSummary");JSONObject j_Obj = new JSONObject(Obj.toString());Object commentCount = j_Obj.get("commentCount"); //商品评价数int count = Integer.parseInt(commentCount.toString());int pageCount = count / 10 + 1;//通过上面计算的页面总数,遍历每页得到每个评价for (int j = 0; j < pageCount; j++) {//拼接每页用户评价的URLString urlStr = "http://club.jd.com/productpage/p-" + goodsId + "-s-0-t-3-p-" + j + ".html";//获取请求每页用户评价的URL返回的结果String contentStr = SpiderUtils.download(urlStr);//通过对返回的Json数据进行解析,想要的评价数据JSONObject jsonObj = new JSONObject(contentStr);String val = jsonObj.get("comments").toString();JSONArray jsonArray = new JSONArray(val);//遍历每条用户评价对应的数据for (int i = 0; i < jsonArray.length(); i++) {JSONObject j_Object = jsonArray.getJSONObject(i);String goodId = "jd_" + goodsId; //商品IDString guid = j_Object.get("guid").toString(); //guidString content = j_Object.get("content").toString(); //评论内容String creationTime = j_Object.get("creationTime").toString(); //评论创建时间String isTop = j_Object.get("isTop").toString(); //isTopString referenceImage = j_Object.get("referenceImage").toString(); //参考图片URLString referenceName = j_Object.get("referenceName").toString(); //参考名称String referenceTime = j_Object.get("referenceTime").toString(); //参考的创建日期String referenceType = j_Object.get("referenceType").toString(); //评论类型String referenceTypeId = j_Object.get("referenceTypeId").toString(); //评论类型IDString firstCategory = j_Object.get("firstCategory").toString(); //firstCategoryString secondCategory = j_Object.get("secondCategory").toString(); //secondCategoryString thirdCategory = j_Object.get("thirdCategory").toString(); //thirdCategoryDate date = new Date();//MyDateUtils是个人封装的工具类String curr_time = MyDateUtils.formatDate2(date); //数据插入的时间//MyDbUtils是个人封装的工具类MyDbUtils.update(MyDbUtils.INSERT_LOG4, goodId, guid, content, creationTime, isTop, referenceImage, referenceName, referenceTime, referenceType, referenceTypeId, firstCategory, secondCategory, thirdCategory, curr_time);}}
}打印的部分结果对比:
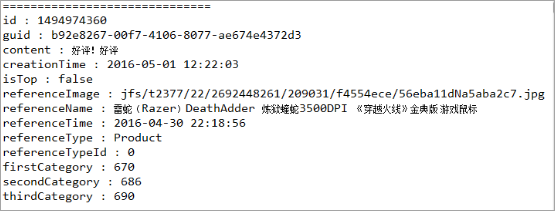
插入数据库后的部分结果:
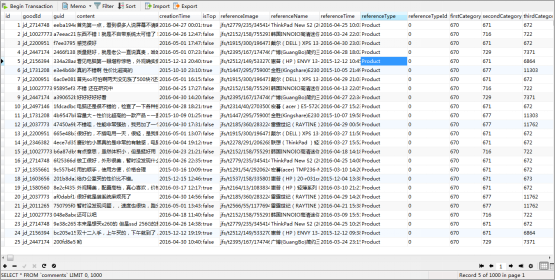
项目代码
工具类
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;public class SpiderUtils {// 下载给定URL的网页实体public static String download(String url) {HttpClientBuilder builder = HttpClients.custom();CloseableHttpClient client = builder.build();HttpGet request = new HttpGet(url);String str = "";try {CloseableHttpResponse response = client.execute(request);HttpEntity entity = response.getEntity();str = EntityUtils.toString(entity);} catch (ClientProtocolException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return str;}}
业务逻辑处理类
import java.util.Date;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
import org.htmlcleaner.XPatherException;
import org.json.JSONArray;
import org.json.JSONObject;public class parsePage implements Runnable {private String url;public parsePage(String url) {this.url = url;}// 将每个页面的业务逻辑放在Runnable接口的run()方法中,这样可以调用多线程爬取每个页面。public void run() {// 通过构造函数插入的url,然后获取该URL的响应结果String contents = SpiderUtils.download(url);HtmlCleaner htmlCleaner = new HtmlCleaner();// 获取所有节点TagNode tn = htmlCleaner.clean(contents);String goodsId = goodsId(tn);// 插入商品好评度到数据库insertCommentSummary(goodsId);// 插入用户印象到数据库insertHotComment(goodsId);// 插入用户评价到数据库insertComments(goodsId);}// 插入用户评价到数据库private void insertComments(String goodsId) {// 拼接评价信息URL的首页,好评度信息每页都会加载,所以我们只需要爬第一页就行了String url = "http://club.jd.com/productpage/p-" + goodsId+ "-s-0-t-3-p-0.html";// 获取商品评价总数,然后除以每页评价数10,拼出总页数String content1 = SpiderUtils.download(url);JSONObject jsonObject = new JSONObject(content1);Object Obj = jsonObject.get("productCommentSummary");JSONObject j_Obj = new JSONObject(Obj.toString());Object commentCount = j_Obj.get("commentCount"); // 商品评价数int count = Integer.parseInt(commentCount.toString());int pageCount = count / 10 + 1;// 通过上面计算的页面总数,遍历每页得到每个评价for (int j = 0; j < pageCount; j++) {// 拼接每页用户评价的URLString urlStr = "http://club.jd.com/productpage/p-" + goodsId + "-s-0-t-3-p-" + j + ".html";// 获取请求每页用户评价的URL返回的结果String contentStr = SpiderUtils.download(urlStr);// 通过对返回的Json数据进行解析,想要的评价数据JSONObject jsonObj = new JSONObject(contentStr);String val = jsonObj.get("comments").toString();JSONArray jsonArray = new JSONArray(val);// 遍历每条用户评价对应的数据for (int i = 0; i < jsonArray.length(); i++) {JSONObject j_Object = jsonArray.getJSONObject(i);String goodId = "jd_" + goodsId; // 商品IDString guid = j_Object.get("guid").toString(); // guidString content = j_Object.get("content").toString(); // 评论内容String creationTime = j_Object.get("creationTime").toString(); // 评论创建时间String isTop = j_Object.get("isTop").toString(); // isTopString referenceImage = j_Object.get("referenceImage").toString(); // 参考图片URLString referenceName = j_Object.get("referenceName").toString(); // 参考名称String referenceTime = j_Object.get("referenceTime").toString(); // 参考的创建日期String referenceType = j_Object.get("referenceType").toString(); // 评论类型String referenceTypeId = j_Object.get("referenceTypeId").toString(); // 评论类型IDString firstCategory = j_Object.get("firstCategory").toString(); // firstCategoryString secondCategory = j_Object.get("secondCategory").toString(); // secondCategoryString thirdCategory = j_Object.get("thirdCategory").toString(); // thirdCategoryDate date = new Date();// MyDateUtils是个人封装的工具类String curr_time = MyDateUtils.formatDate2(date); // 数据插入的时间// MyDbUtils是个人封装的工具类MyDbUtils.update(MyDbUtils.INSERT_LOG4, goodId, guid, content,creationTime, isTop, referenceImage,referenceName, referenceTime, referenceType,referenceTypeId, firstCategory, secondCategory,thirdCategory, curr_time);}}}// 插入用户印象到数据库private void insertHotComment(String goodsId) {// 拼接评价信息URL的首页,用户印象信息每页都会加载,所以我们只需要爬第一页就行了String url = "http://club.jd.com/productpage/p-" + goodsId+ "-s-0-t-3-p-0.html";String content = SpiderUtils.download(url);// 我们抓取到的数据为Json字符串格式,所以我们需要对Json数据进行解析JSONObject jsonObject = new JSONObject(content);Object object = jsonObject.get("hotCommentTagStatistics");JSONArray jsonArray = new JSONArray(object.toString());goodsId = "jd_" + goodsId;for (int i = 0; i < jsonArray.length(); i++) {JSONObject j_Obj = jsonArray.getJSONObject(i);String productId = j_Obj.get("productId").toString(); // 商品IDString tagId = j_Obj.get("id").toString(); // 用户某类印象IDString count = j_Obj.get("count").toString(); // 用户印象种类数String status = j_Obj.get("status").toString(); // 用户某类印象状态String rid = j_Obj.get("rid").toString(); // ridString name = j_Obj.get("name").toString(); // 用户某类印象(例如:大小合适,灵敏度高,反应灵敏等)String modified = j_Obj.get("modified").toString(); // 一类用户印象最后更新的时间Date date = new Date();// MyDateUtils是个人封装的工具类String curr_time = MyDateUtils.formatDate2(date); // 数据插入的时间// MyDbUtils是个人封装的工具类MyDbUtils.update(MyDbUtils.INSERT_LOG3, goodsId, productId, tagId,count, status, rid, name, modified, curr_time);}}// 插入商品好评度到数据库private void insertCommentSummary(String goodsId) {// 拼接评价信息URL的首页,好评度信息每页都会加载,所以我们只需要爬第一页就行了String url = "http://club.jd.com/productpage/p-" + goodsId + "-s-0-t-3-p-0.html";//请求JS异步传输的商品信息,然后获取其中的商品好评度信息String content = SpiderUtils.download(url);JSONObject jsonObject = new JSONObject(content);Object Obj = jsonObject.get("productCommentSummary");JSONObject j_Obj = new JSONObject(Obj.toString());// 获取好评度中的信息goodsId = "jd_" + goodsId; // 商品ID,添加了"jd_"前缀,用于和其他电商数据区分String productId = j_Obj.get("productId").toString(); // 商品IDString commentUrl = url; // 商品好评度URLString commentCount = j_Obj.get("commentCount").toString(); // 商品评价数String goodRateShow = j_Obj.get("goodRateShow").toString(); // 好评度String generalRateShow = j_Obj.get("generalRateShow").toString(); // 中评度String poorRateShow = j_Obj.get("poorRateShow").toString(); // 差评度String goodCount = j_Obj.get("goodCount").toString(); // 好评数String generalCount = j_Obj.get("generalCount").toString(); // 中评数String poorCount = j_Obj.get("poorCount").toString(); // 差评数Date date = new Date();// MyDateUtils是个人封装的工具类String curr_time = MyDateUtils.formatDate2(date);// MyDbUtils是个人封装的工具类MyDbUtils.update(MyDbUtils.INSERT_LOG2, goodsId, productId, commentUrl,commentCount, goodRateShow, generalRateShow, poorRateShow,goodCount, generalCount, poorCount, curr_time);}// 获取商品IDprivate String goodsId(TagNode tn) {String xpath = "//*[@id=\"short-share\"]/div/span[2]";Object[] objects = null;try {objects = tn.evaluateXPath(xpath);} catch (XPatherException e) {e.printStackTrace();}TagNode node = (TagNode) objects[0];String id = node.getText().toString();return id;}}
项目入口类
import org.htmlcleaner.XPatherException;
import java.util.HashSet;
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Spider {public static void main(String[] args) throws XPatherException {Spider spider = new Spider();spider.start();}public void start() throws XPatherException {System.out.println("开始启动爬虫");//爬取本周热卖网页String content = SpiderUtils.download("http://sale.jd.com/act/6hd0T3HtkcEmqjpM.html");// 匹配这个网页所有商品网址Pattern compile = Pattern.compile("//item.jd.com/([0-9]+).html");// 使用正则进行匹配Matcher matcher = compile.matcher(content);// 使用正则进行查找,查找过程中可能会出现重复的URL,所以我们需要存入HashSet从而保证URL唯一HashSet<String> hashSet = new HashSet<String>();String goodId = "";// 使用正则进行查找while (matcher.find()) {String goodURL = matcher.group(0);hashSet.add(goodURL);}for (String goodUrl : hashSet) {Thread th = new Thread(new parsePage("http:" + goodUrl));th.start();}}}
这篇关于爬取京东本周热卖商品所有用户评价存入MySQL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


