本文主要是介绍RTAB-Map 闭环检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎访问 https://cgabc.xyz/posts/999fccc5/,持续更新
1. 概述
主要特点:
- 基于外观(Appearance-Based),通过图像相似度查找回环
- 贝叶斯滤波算法,估计回环的概率
- 增量式在线构建视觉词典或词袋,针对一个特定环境不需要预训练过程
- 内存管理模型,保证实时在线运行
代码主要过程:
- RTABMap(闭环检测)主入口函数
Rtabmap::process - 输入图像
image及其id(header.seq)被封装到SensorData类 - 内存更新(
Memory::update)- 创建签名(
Memory::createSignature) - Add Signature To STM(
Memory::addSignatureToStm) - Weight Update, Rehearsal(
Memory::rehearsal) - Transfer the oldest signature from STM to WM(
Memory::moveSignatureToWMFromSTM)
- 创建签名(
- 贝叶斯滤波器更新
- 计算似然(
Memory::computeLikelihood) - 调整似然(
Rtabmap::adjustLikelihood) - 计算后验(
BayesFilter::computePosterior) - 选择最高的闭环假设
- 计算似然(
- RETRIEVAL
- Loop closure neighbors reactivation
- Load signatures from the database, from LTM to WM(
Memory::reactivateSignatures)
- Update loop closure links: make neighbors of the loop closure in RAM
- TRANSFER: move the oldest signature from STM to LTM
算法主要流程:

内存管理模型:
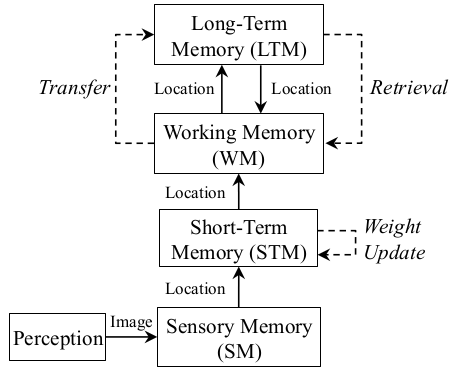
回环检测(若不考虑内存管理)过程:
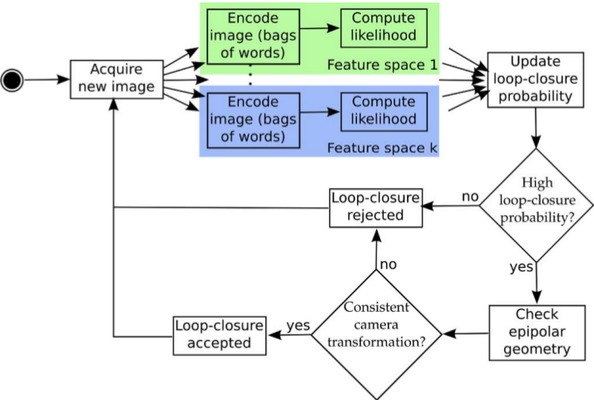
2. 内存更新
2.1 创建签名
代码在 Memory::createSignature 中,其主要过程为
- 词典更新(
VWDictionary::update) 线程- 构建FLANN索引
- 根据描述子构建KDTree索引词典 (
_flannIndex->buildKDTreeIndex,kNNFlannKdTree) - KDTree的创建基于分层k-mean聚类
- 根据描述子构建KDTree索引词典 (
- 更新
_dataTree
- 构建FLANN索引
- 角点(GFTT)检测(
Feature2D::generateKeypoints)- 均匀分布(
gridRows_, gridCols_) - 限制点数(
maxFeatures_) - 亚像素提取(
cv::cornerSubPix)
- 均匀分布(
- 描述子(BRIEF)计算(
Feature2D::generateDescriptors) - quantize descriptors to vocabulary(
VWDictionary::addNewWords)-
描述子匹配(descriptors – dataTree),并计算距离
-
添加单词 或 参考+1
- badDist=true(匹配数量特别少,或 NNDR(neareast neighbor distance ratio) 大于 T NNDR T_{\text{NNDR}} TNNDR 阈值
_nndrRatio),然后创建VisualWord并添加到_visualWords
NNDR = dist of the neareast neighbor dist of the second-neareast neighbor \text{NNDR} = \frac{\text{dist of the neareast neighbor}}{\text{dist of the second-neareast neighbor}} NNDR=dist of the second-neareast neighbordist of the neareast neighbor
- badDist=false,
VWDictionary::addWordRef,_references+1
- badDist=true(匹配数量特别少,或 NNDR(neareast neighbor distance ratio) 大于 T NNDR T_{\text{NNDR}} TNNDR 阈值
-
- 创建签名(
new Signature)
2.2 添加签名到STM
代码主要在 Memory::addSignatureToStm 中。
- 更新neighbors,添加链接(
signature->addLink) - 添加签名ID到
_stMem
2.3 更新权重
代码主要在 Memory::rehearsal 中。
signature与STM中最新的签名比较,计算相似度RehearsalSimilarity(float sim = signature->compareTo(*sB))
similarity = pairs totalWords \text{similarity} = \frac{\text{pairs}}{\text{totalWords}} similarity=totalWordspairs
-
相似度 > 阈值
_similarityThreshold,假设合并(Memory::rehearsalMerge),更新权重- 更新权重(
signature->setWeight)
w A = w A + w B + 1 w_A = w_A + w_B + 1 wA=wA+wB+1
- 新旧签名合并(
Memory::rehearsalMerge)- 新签名添加Link
- 删除旧签名(
moveToTrash)
- 更新权重(
2.4 签名转移 (STM->WM)
Transfer the oldest signature of the short-term memory to the working memory
_maxStMemSize= 10Memory::moveSignatureToWMFromSTM:_workingMem.insert和_stMem.erase
3. 贝叶斯滤波器更新
-
计算似然(
Memory::computeLikelihood),得到rawLikelihood- 算法一:tf-idf (term frequency–inverse document frequency)
tf-idf = n w i + log N n w n i \text{tf-idf} = \frac{n_{wi} + \log \frac{N}{n_w}}{n_i} tf-idf=ninwi+lognwN
- 算法二:相似度 RehearsalSimilarity
-
调整似然(
Rtabmap::adjustLikelihood) s j s_j sj,得到likelihood- 依据 似然均值 μ \mu μ 和 似然标准差 σ \sigma σ
likelihood = { s j − σ μ , if s j ≥ μ + σ 1 , otherwise . \text{likelihood} = \begin{cases} \frac{s_j - \sigma}{\mu}, \quad \text{if} \ s_j \geq \mu + \sigma \\ 1, \quad\quad\quad \text{otherwise}. \end{cases} likelihood={μsj−σ,if sj≥μ+σ1,otherwise.
-
计算后验(
BayesFilter::computePosterior),得到posterior- 预测(Prediction : Prior*lastPosterior)得到
_prediction - 更新后验(
BayesFilter::updatePosterior) - 计算先验(
prior = _prediction * posterior) - 计算后验
- 后验归一化
- 预测(Prediction : Prior*lastPosterior)得到
posterior = likelihood × prior \text{posterior} = \text{likelihood} \times \text{prior} posterior=likelihood×prior
4. 回环假设选择
Select the highest hypothesis
- 根据后验
posterior选择最高的假设_highestHypothesis - 接受回环,条件如下:
_highestHypothesis>_loopThr- 对极几何 检查(
_epipolarGeometry->check)- 单词匹配对数量(
EpipolarGeometry::findPairsUnique) >_matchCountMinAccepted - 对极约束内点数(
EpipolarGeometry::findFFromWords) >_matchCountMinAccepted(RANSAC方法计算基础矩阵)
- 单词匹配对数量(
5. 取回 Retrieval (LTM->WM)
对于形成回环概率最高的定位点,将他那些没有在WM中的邻接定位点,从LTM中取回放入到WM中。
- Loop closure neighbors reactivation
- time
- space
- Update planned path and get next nodes to retrieve
- Load signatures from the database (LTM->WM)
6. 转移 Transfer (STM->LTM)
If time allowed for the detection exceeds the limit of real-time, move the oldest signature with less frequency entry (from X oldest) from the short term memory to the long term memory.
具有最低权重的定位点中,存储时间最长的将被转移到LTM(数据库SQLite)中。
参考文献
[1] Appearance-Based Loop Closure Detection for Online Large-Scale and Long-Term Operation
[2] Fast and Incremental Method for Loop-Closure Detection Using Bags of Visual Words
这篇关于RTAB-Map 闭环检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





