本文主要是介绍使用KEPServer连接欧姆龙PLC获取对应标签数据(标签值类型改为字符串型),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.创建通道(通道),(选择对应的驱动,跟当前型号PLC型号对应)。
2.创建设备,(填入IP地址以及欧姆龙的默认端口号:44818)

3.创建对应的标签。这里关键讲诉下字符串的创建方法:
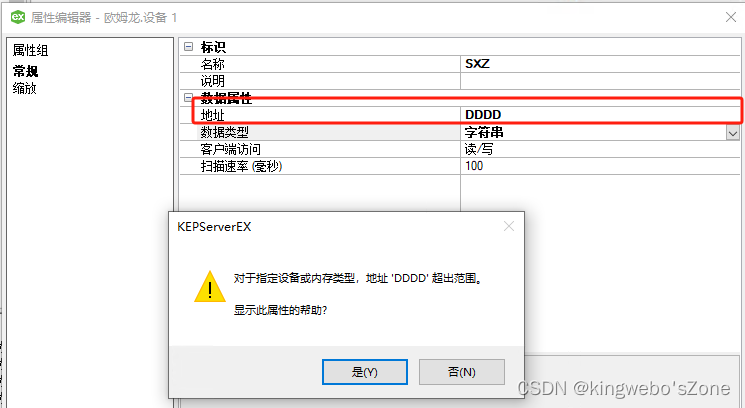
由于字符串的操作会出现超出范围,参考KEPServer 说明文档结果是:
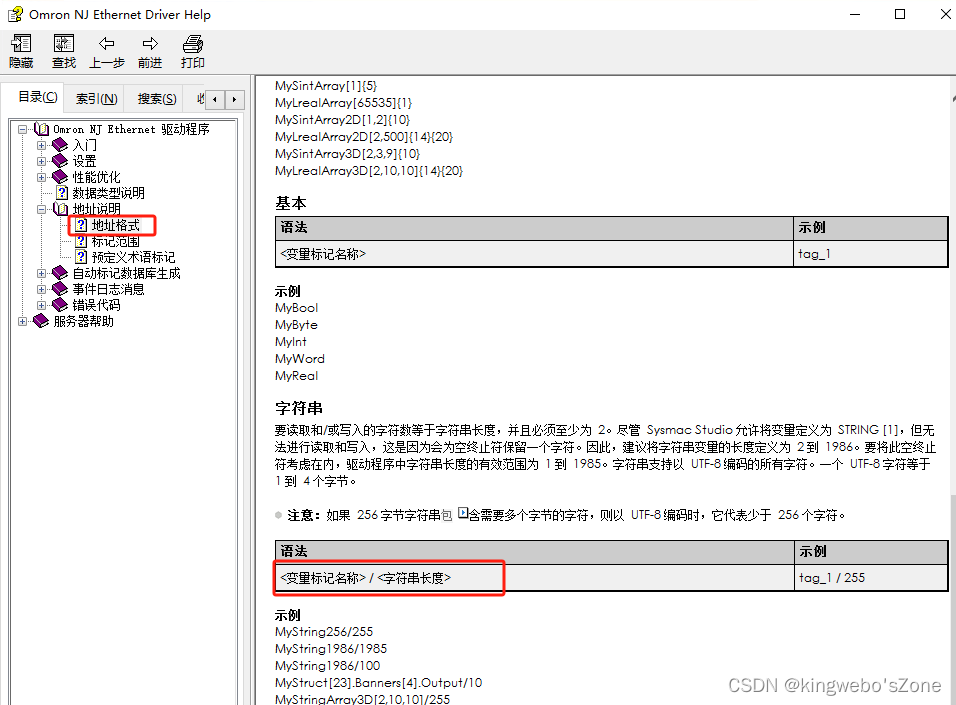
参考字符串的标记方式: 变量名称/字符长度
所以需要将地址修改

提交即可完成。
其中c#读取方式:
首先 连接KEPServer。Dword类型是双字模式,实际就是表现为两个十六进制数。
然后进行读取操作:
string nodeId = "ns=2;s=欧姆龙.设备 1.001";//DataValue myValue = opcClient.GetCurrentNodeValue(nodeId);float ThisFloat = opcClient.GetCurrentNodeValue<float>( nodeId);///读取string string NodeString = "ns=2;s=欧姆龙.设备 1.002"; string ThisString = opcClient.GetCurrentNodeValue<string>(NodeString);
这篇关于使用KEPServer连接欧姆龙PLC获取对应标签数据(标签值类型改为字符串型)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






