本文主要是介绍城市之旅:使用 LLM 和 Elasticsearch 简化地理空间搜索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:来自 Elastic Philipp Kahr, Valentin Crettaz
探索如何从自然语言提问创建地理空间搜索。在下面的示例中,我们将演示一个请求在地铁站或兴趣点周围一定半径内的 Airbnb 房源列表的问题。你可以将这一日常用例扩展到其他地理空间搜索,例如在指定区域内寻找餐馆、景点、学校和其他地方。
我们将使用以下纽约市的数据集:
- Airbnb 房源列表
- 兴趣点 (point of interests - POIs)
- MTA 地铁站
我们提供了一本 Jupyter Notebook,它将引导你完成设置数据集、将它们导入 Elasticsearch 以及设置生成式 AI 和 LLM 部分的过程。我们还会展示如何使用 Elasticsearch 进行地理空间搜索以及如何结合这两者。
我们首先需要做的事情是获取正确的数据集并准备好它们以供导入。Jupyter Notebook 中对此有更详细的描述。我们决定对 Airbnb 数据集运行 ELSER 以进行语义搜索。这意味着我们需要使用一个运行 inference 处理器并将 ELSER 作为目标的导入管道,并确保我们将字段映射为 sparse_vector。下面是一个 Airbnb 房源的 JSON 表示,仅保留了 name、 descriptions 和 amenities 重要字段。
{"name": "Lovely 1 bedroom rental in New York","name_embedding": {"bed": 0.4812702,"studio": 0.3967694,...},"description": "My guests will enjoy easy access to everything from this centrally located place.","description_embedding": {"parking": 0.5157142,"studio": 0.2493607,...},"amenities": ["Mosquito net", "Dishes and silverware", "N/A gas stove", "Refrigerator", "Babysitter recommendations", "Children's books and toys", "N/A oven", "Air conditioning", "Toaster", "Wifi", "TV", "Security cameras on property", "Long term stays allowed", "Kitchen", "Wine glasses", "Hot water", "Rice maker", "Carbon monoxide alarm", "Bathtub", "Laundromat nearby", "Essentials", "Baking sheet", "Extra pillows and blankets", "Clothing storage", "Free parking on premises", "Smoke alarm", "Paid parking garage off premises", "Hangers", "N/A conditioner", "Fire extinguisher", "Private hot tub", "Cleaning products", "Dining table", "Dedicated workspace", "Blender", "Safe", "Cooking basics", "Freezer", "Bed linens", "Hair dryer", "Iron", "Window guards", "Fireplace guards", "Coffee", "Heating", "N/A shampoo", "Microwave", "Free street parking"],"amenities_embedding": {"2000": 0.1171638,"tub": 0.8834068,...},"location": {"lon": -73.93711,"lat": 40.8015}
}
利用 ELSER,我们为便利 amenities、names 和 descriptions 生成了向量嵌入。嵌入帮助我们找到明确且相关的匹配项,从而帮助我们构建更好的搜索体验。用户可能会搜索靠近花园,即任何公园、花园或休闲区。因此,此查询的答案可以包含 Central Park、Botanical Garden、Convent Garden 和更多绿地。下面是用户正在搜索 Next to Central Park and Empire State Building。
{"text_expansion": {"description_embedding": {"model_id": ".elser_model_2_linux-x86_64","model_text": "Next to Central Park and Empire State Building",}}
}现在,它将搜索 description 字段的嵌入。对于标有 “Close to Empire State Building” 或提及 “Central Park” 的 Airbnb 房源,这当然会更准确。但它也会找到靠近这些位置但未在描述中提及的房源,具体取决于语义搜索功能。ELSER 可能知道 Bow Bridge 是位于中央公园内的一座风景优美的桥梁,因此结果中也可能出现 “Only a short walk to the iconic Bow Bridge” 的描述。
从 Python 代码示例来看,所需的整个代码如下所示:
response = client.search(index="airbnb-*",size=10,query={"text_expansion": {"description_embedding": {"model_id": ".elser_model_2_linux-x86_64","model_text": "Next to Central Park and Empire State Building",}}},
)
这将返回靠近中央公园和帝国大厦的前 10 个 Airbnb 房源。结果将按相关性排序,而不是按任何地理测量排序。
地理空间搜索快速入门
下一步是强调进行正确的地理空间搜索。我们在 Jupyter Notebook 中提供了所有详细信息。在深入讨论细节之前,我们需要讨论几种搜索类型。在所有可用的地理搜索中,我们可以找到 geo_bounding_box 和 geo_distance,这是我们今天要关注的。
geo_distance 查询非常简单。给定一个特定的地理点(也可以使用地理形状,但这是另一篇博文的内容),你可以搜索该点周围一定半径内的所有文档。
GET /airbnb-listings/_search
{"query": {"geo_distance": {// The maximum radius around the location"distance": "1km",// The location of the `Empire State Building` from where you want to calculate the 1km radius."location": {"lat": 40.74,"lon": -73.98} }}
}
geo_bounding_box 查询稍微复杂一些。你需要提供至少两个代表矩形边界框的点,这有助于我们回答诸如 “Find me all Airbnb between Empire State Building and Central Park Bow Bridge” 之类的问题。这将确保 Bow Bridge 上方的任何 Airbnb 都被排除在搜索结果之外。当可视化时,此类搜索看起来就是这样的。
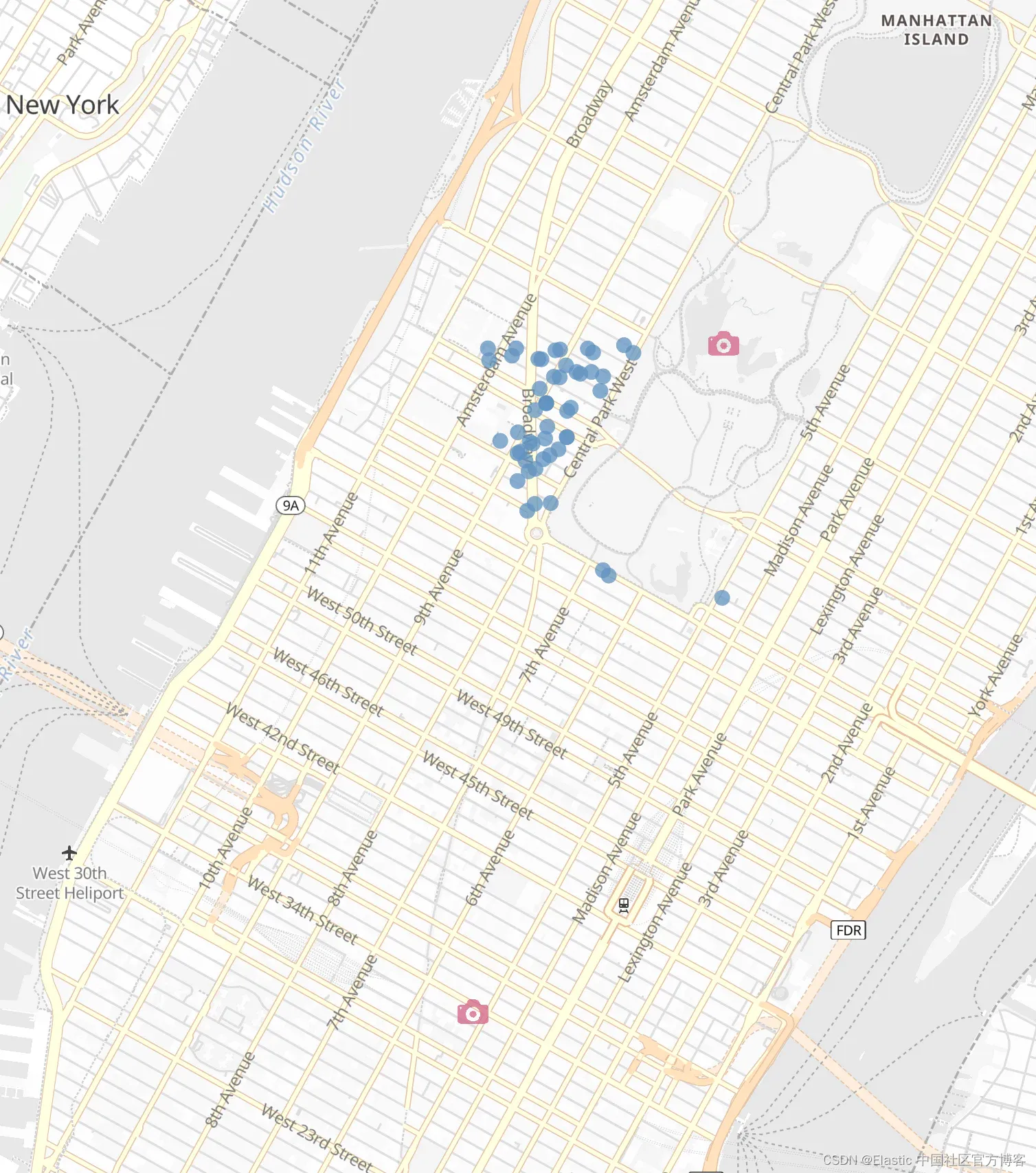
GET /airbnb-listings/_search
{"query": {"geo_bounding_box": {"location": {"top_left": {"lat": 40.77, // lat of Bow bridge"lon": -73.98 // lon of Empire State},"bottom_right": {"lat": 40.74, // lat of Empire State"lon": -73.97 // lon of Bow Bridge}}}}
}
这是一个非常简单的示例,说明如何使用 Elasticsearch 进行地理空间搜索。你还可以做更多的事情,例如添加 sort 参数以按距离排序,或添加过滤器以过滤掉某些不符合你要求的 Airbnb 房产,例如太贵的房产或缺少便利设施的房产。
由于我们在 Elasticsearch 中将兴趣点索引为文档,因此我们不需要像上面那样手动指定纬度和经度。相反,我们可以使用 terms 查询来搜索兴趣点的名称。下面是如何通过 geo_bounding_box 查询搜索 Empire State Building 和 Central Park Bow Bridge 的示例。
# We first grab the location of the Empire State Building and Central Park Bow Bridge
response = client.search(index="points-of-interest",size=2,query={"terms": {"name": ["central park bow bridge", "empire state building"]}},
)# for easier access we store the locations in two variables
central = {}
empire = {}
for hit in response["hits"]["hits"]:hit = hit["_source"]if "central park bow bridge" in hit["name"]:central = hit["location"]elif "empire state building" in hit["name"]:empire = hit["location"]# Now we can run the geo_bounding_box query and sort it by the
# distance first to Central Park Bow Bridge
# and then to the Empire State Building.
response = client.search(index="airbnb-*",size=50,query={"geo_bounding_box": {"location": {"top_left": {"lat": central["lat"],"lon": empire["lon"]},"bottom_right": {"lat": empire["lat"],"lon": central["lon"]}}}},sort=[{"_geo_distance": {"location": {"lat": central["lat"],"lon": central["lon"]},"unit": "km","distance_type": "plane","order": "asc"}},{"_geo_distance": {"location": {"lat": empire["lat"],"lon": empire["lon"]},"unit": "km","distance_type": "plane","order": "asc"}}]
)要求 LLM 提取实体
现在我们了解了地理空间搜索的工作原理,我们可以将 GenAI 和 LLM 部分添加到我们的情形中。这个想法是有一个搜索框、聊天机器人或你喜欢的任何其他东西,你可以在其中用自然语言询问在某个位置或位置附近找到你的 Airbnb 房产。在 Jupyter Notebook中,我们依靠 ChatGPT3.5 Turbo 从自然语言中提取信息并将其转换为 JSON,然后进行解析和处理。
问题:
Get me the closest Airbnb within 1 mile of the Empire State Buildingquestion="""
As an expert in named entity recognition machine learning models, I will give you a sentence from which I would like you to extract what needs to be found (location, apartment, airbnb, sight, etc) near which location and the distance between them. The distance needs to be a number expressed in kilometers. I would like the result to be expressed in JSON with the following fields: "what", "near", "distance_in_km". Only return the JSON.
Here is the sentence: "Get me the closest Airbnb between 1 miles distance from the Empire State Building"
"""answer = oai_client.completions.create(prompt=question, model=model, max_tokens=100)
print(answer.choices[0].text)
# Output below{"what": "Airbnb","near": "Empire State Building","distance_in_km": 1610
}
解析兴趣点
我们首先针对兴趣点索引进行搜索,并提取 Empire State Building 的地理位置。接下来,我们针对 airbnb-listings 索引进行搜索,并使用 geo_distance 查询查找距离帝国大厦 1 英里以内的所有 Airbnb 房源。然后,我们按距离对结果进行排序,并返回最接近的结果,如下所示:
Distance to Empire State Building: 0.004002111094864837 km
Title: Comfort and Convenience! 2 Units Near Bryant Park!Distance to Empire State Building: 0.011231615140053008 km
Title: Relax and Recharge! 3 Relaxing Units, Pets Allowed寻找无障碍地铁站
我们现在有一个由 GenAI 和 Elasticsearch 提供支持的地理空间搜索功能,但我们可以更进一步!一开始,我们还提取了地铁站列表,其中包含一个名为 ADA 的字段,这是《Americans with Disabilities Act - 美国残疾人法案》的缩写,其值可以是:
- 0:无法访问
- 1:完全可访问
- 2:部分可访问
结合不同的数据集,我们可以搜索完全可访问、提供电梯通道、残疾人专用卫生间和更多便利设施的 Airbnb 房源,并确保 Airbnb 尽可能靠近完全可访问的地铁站。
用户的问题可能是,Find me all Airbnb properties within 250m in Manhatten near the Empire State Building that are fully accessible and close to a subway station that is fully accessible。GenAI 将提取信息,我们可以针对 airbnb-listings 和 mta-stations 索引进行搜索,为用户找到最佳的 Airbnb。
{"what": "Airbnb","near": "Empire State Building","accessibility": "fully accessible","distance_in_km": 0.250
}
我们可以构建以下查询,搜索帝国大厦附近完全无障碍的地铁站。如果我们没有找到任何地铁站,我们可以通知用户,告诉他们帝国大厦附近没有完全无障碍的地铁站,我们应该选择另一个景点。
GET mta-stations/_search
{"query": {"bool": {"filter": [// Subway stations have `fully accessible` as `ADA` 1 value.{"term": {"ADA": 1}}],"must": [{"geo_distance": {// The distance, 250m as in the prompt."distance": "250m",// The location of the `Empire State Building` from where you want to calculate the 250m radius."location": {"lon": -73.985322454067,"lat": 40.74842927376084}}}]}},"sort": [{"_geo_distance": {"location": {"lon": -73.985322454067,"lat": 40.74842927376084},"unit": "km","distance_type": "plane","order": "asc"}}]
}
这将返回所有可完全到达且距离帝国大厦 250 米以内的地铁站。结果按距离排序,因此最近的地铁站是结果中的第一个。这是我们使用地理空间搜索时可能遇到的问题的一个很好的例子。我们可能在 250 米范围内找不到任何东西,但可能有一个车站距离只有一米,我们仍然可以考虑它。这就是为什么我们可以运行后续查询将距离延长到 300 米。使用调整后的距离第二次运行查询将返回名为 “34 St-Herald Sq” 的站点,距离帝国大厦 254 米。
综合起来
现在我们在帝国大厦附近有一个完全无障碍的地铁站,我们可以针对 airbnb-listings 索引运行以下查询,以查找距离帝国大厦 250 米范围内所有完全无障碍的 Airbnb 房源。然后我们按距离对结果进行排序,首先按与帝国大厦的距离排序,然后按与地铁站的距离排序。
GET airbnb-listings/_search
{"query": {"bool": {"filter": [// Airbnb listings that are `fully accessible`{"text_expansion": {"amenities_embedding": {"model_id": ".elser_model_2_linux-x86_64","model_text": "fully accessible"}}}],"must": [{"geo_distance": {// The distance, 250m as in the prompt."distance": "250m",// The location of the `Empire State Building` from where you want to calculate the 250m radius."location": {"lon": -73.985322454067,"lat": 40.74842927376084}}}]}},"sort": [{"_geo_distance": {"location": {"lon": -73.985322454067,"lat": 40.74842927376084},"unit": "km","distance_type": "plane","order": "asc"}},{"_geo_distance": {"location": {"lon": -73.985322454067,"lat": 40.74842927376084},"unit": "km","distance_type": "plane","order": "asc"}}]
}
此查询现在列出了符合我们基于 ELSER 的 fully accessible 设施搜索的所有 Airbnb 房源。在答案中,sort 对象包含两个值:0.004 和 0.254,以公里为单位。因此,Airbnb 距离帝国大厦 4 米,距离地铁站 254 米。这是一个很棒的结果,我们现在可以将其返回给用户并让他们做出决定。
结论
我们在这篇博文中向你介绍了许多不同的任务和想法。我们从地理空间搜索的基础知识开始,然后添加了 GenAI 和 LLM 部分,最后将两者结合起来,创造了强大的搜索体验。我们希望你喜欢这篇博文,并学到了一些新东西。
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证吗?了解下一期 Elasticsearch 工程师培训何时举行!
原文:Geospatial search made simple with LLMs and Elasticsearch — Elastic Search Labs
这篇关于城市之旅:使用 LLM 和 Elasticsearch 简化地理空间搜索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




