本文主要是介绍数据结构与算法之美-二分查找-极客时间笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
二分查找是一种针对有序数据的查找方式,通过每次选择数据中间点进行比较,来将目标范围降低一半的方法。
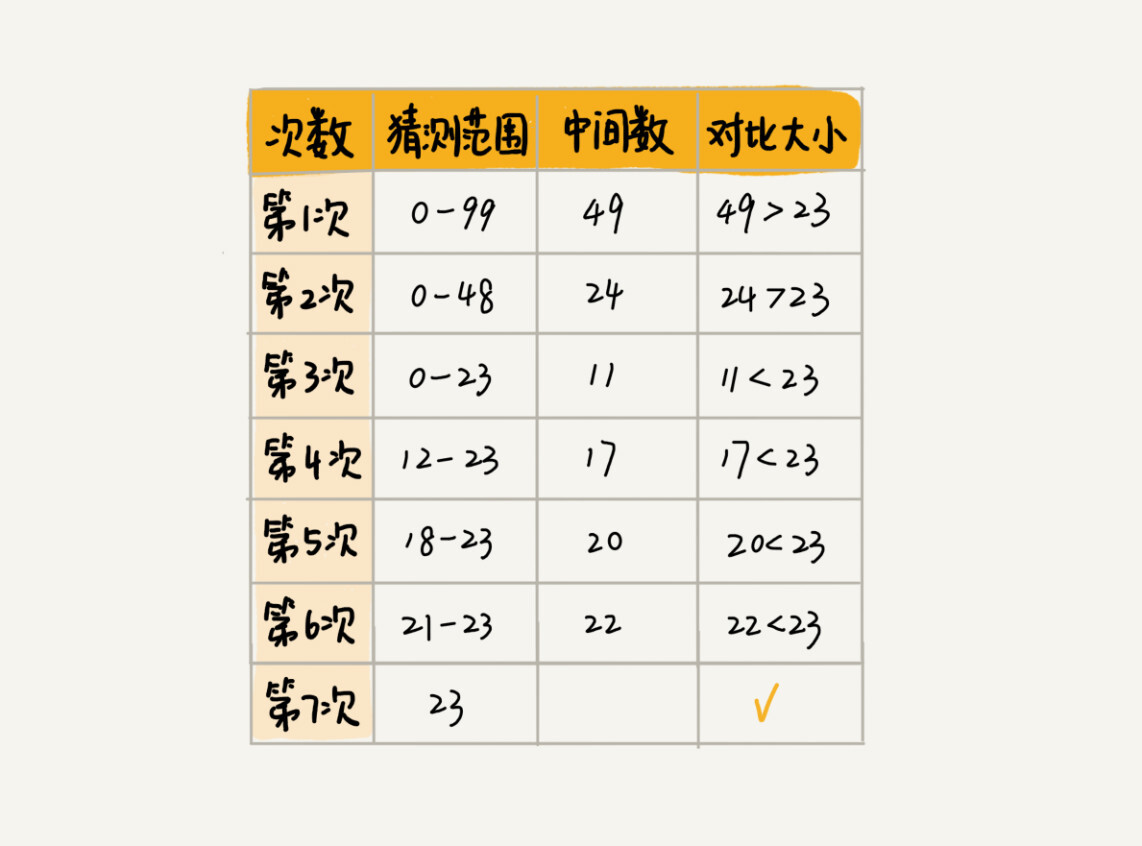
在日常生活中,我们应该都不自觉的使用过,比如经典的猜数字游戏,一个人默写下1个数字,其他人来猜这个数字,为了不让游戏无聊的延续下去,都是每次一半的进行猜测。
类似这种每次按照固定比例降低数据范围的查找方法统一叫作对数级的查找效率O(logn),对数查找效率是很高效的,在大数据量面前,甚至比常数级O(1)还要高效。比如1024个数据,对数级最多就10次,而常量级最多是1024次。
二分查找虽然很好用,但也是有其应用局限的:
1、底层数据结构要求数组,因为利用到了数组的基于索引查找数据O(1)。不然查找读取数据会加大开销。
2、数据要有序,二分查找的基础上数据有序,所以如果频繁插入删除的数据,每次查找前都要重新排序才能使用,所以也不适合。最好是一次排序多次查找的场景。
3、数据量太小或者太大都不合适。太小的话,可以用更简单的遍历查找。太大的话,因为底层是数组结构,也很难一次性开辟特别大的连续内存空间来使用。
上面说到的都是简单的二分查找,针对的是没有重复数据的情况。二分查找可以有多种变形,要没有bug还是要多细心。比如第一个符合给定值/最后一个符合给定值/第一个大于等于给定值。
二分查找的代码主要注意三点:终止条件,上下边界的更新,返回值选择。写一段易懂好维护、无bug的代码可能比简洁的代码更加重要,有些不要过分追求简练。除非你能够熟能生巧,把最优写法完全默写下来。
这篇关于数据结构与算法之美-二分查找-极客时间笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




