本文主要是介绍Qimera处理多波束all数据记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前写过使用Qimera处理db格式的多波束数据,QPS Qimera处理Qinsy采集的db格式多波束数据,具体的步骤就不用说了。
前两天有个人问Qimera处理all数据的问题,Qimera加载不了潮位,我们一般使用CARIS处理all数据,很少用QPS Qimera处理。
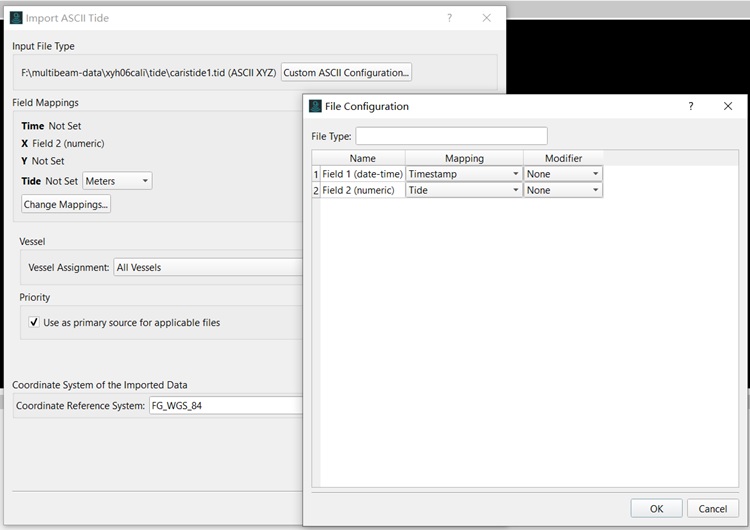
刚好船上做了3条all数据的校准线,就用Qimera 1.6.3尝试了一下。潮位加载没有问题,使用的是ASCII格式的CARIS格式的潮位文件,文件格式如下:
--------
2021/09/24 00:00:00.00,0.000
2021/09/25 00:00:00.00,0.000
加载潮位的截图如下:

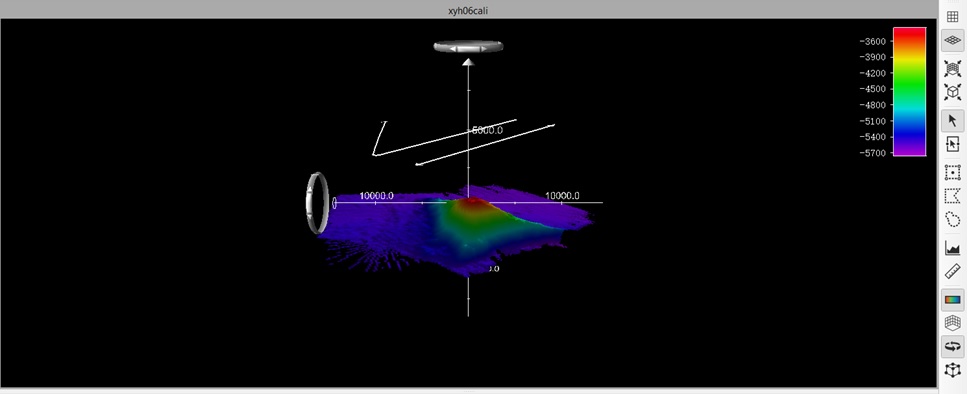
这次Qimera使用过程中,想将地形压扁,怎么也找不到在哪儿设置。后来发现地形拉伸和压缩功能在三维视图中,鼠标按住Z轴坐标上端的圆锥体,鼠标向上移动是拉伸地形,鼠标向下移动是压扁。由于反应有点延迟,鼠标移动的过程最好慢一点。
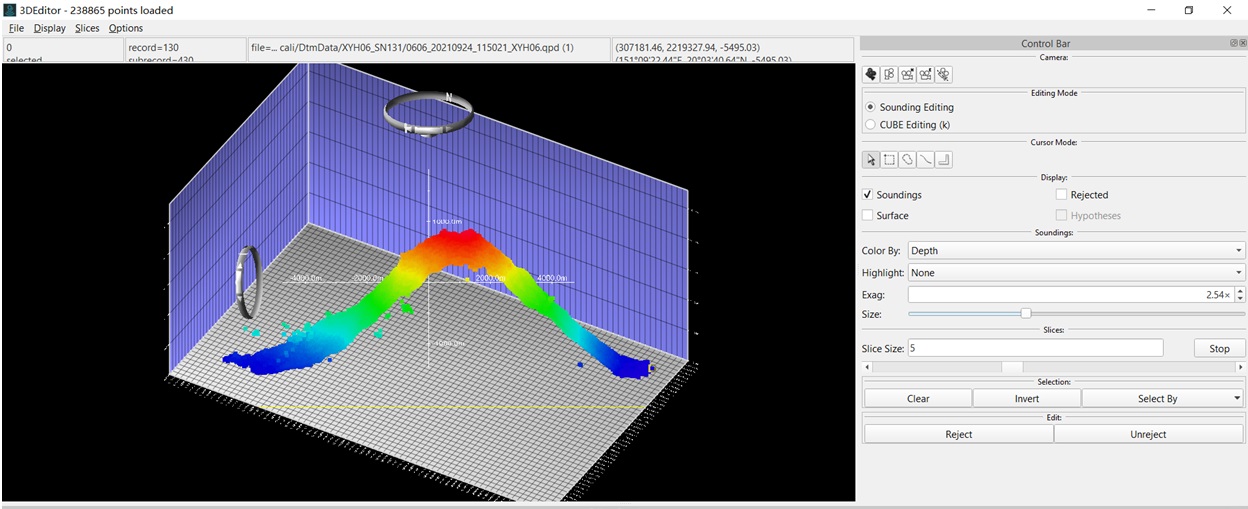
下面介绍一下Qimera相比CARIS惊艳的功能,三维切分功能,特别适合于起伏地形的数据清理(data cleaning)。在CAIRS中清理海山时,当噪声 数据位于海山下,清理较为费劲,博主喜欢在三维视图中将其倒扣过来多视角清理,比较耗时,且死角难以清理。
首先选中海山区,三维视图打开,点击右面控制栏Slices中的Start按钮

然后使用滑动条,逐切分块进行噪声数据清理,非常方便

这篇关于Qimera处理多波束all数据记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





