本文主要是介绍OrangePi Kunpeng Pro 开发板测评 | AI 边缘计算 大模型部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0 前言
此次很幸运能够参与 OrangePi Kunpeng Pro 开发板的测评,感谢 CSDN 给予这次机会。
香橙派联合华为发布了基于昇腾的 OrangePi Kunpeng Pro 开发板,具备 8TOPS 的 AI 算力,能覆盖生态开发板者的主流应用场景,具备完善的配套软硬件。
1 硬件
怀着期待的心情,终于拿到 OrangePi Kunpeng Pro 开发板了。
1.1 外观
OrangePi Kunpeng Pro 开发板包装很严实,开发板装在密封的静电袋中,盒子里面上面和下面都有海绵保护,防止开发板被压坏,厂商确实很用心了。配件里面还配有最高 65W 的 PD type-c 电源,电源支持 5V3A、9V3A、12V3A、15V3A、20V3.25A。

OrangePi Kunpeng Pro 开发板的硬件细节可以从官网的细节图看得很清晰:
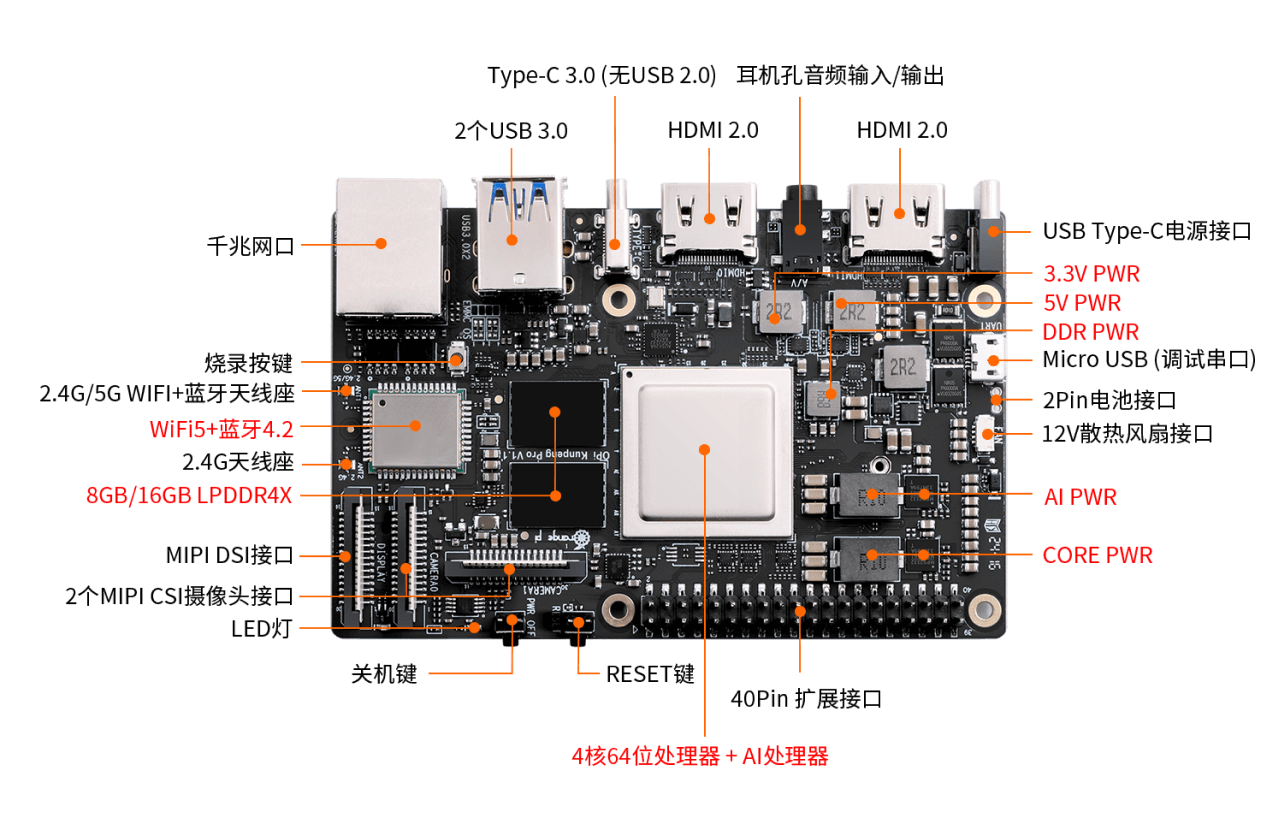
OrangePi Kunpeng Pro 开发板正面左边有一个包含两个头的天线,两个头分别是 2.4G 和 2.4/5G。左下角 MIPI 摄像头接口(Camera0)和 MIPI 显示屏接口(Display),旁边两个按钮分别是 PowerOff 电源按钮和 ESET 复位按钮,按钮上面又是一个 MIPI 摄像头接口(Camera1)。
开发板右下角就是 40PIN 的排针(GPIO)。开发板正面的 IO接口都集中在上边,从左到右分别是千兆网口、2个USB3.0接口、type-c3.0 接口、HDMI2.0、3.5mm耳机口音频输出/输入、HDMI2.0、type-c电源接口。

开发板中间是一个巨大的散热器。这个散热器的散热能力很不错,风扇最高 3W 功率。散热风扇为 12V 的,接口为 4pin,0.8mm 间距规格。可以通过 PWM 来控制风扇的转速。

OrangePi Kunpeng Pro 开发板背面看起来很漂亮,板子做工很好。

开发板背面主要是存储接口和两个设置启动方式的拨码开关。
如果使用 TF 卡来启动,需要使用 class10 以上的 TF卡;eMMC 接口可以外接 eMMC 模块;M.2 M-KEY 接口可以安装 2280 规格的 NVMe 协议或者 SATA 协议的 SSD。
两个控制启动方法的拨码开关,可以控制开发板从从TF卡、eMMC和SSD启动。BOOT1和BOOT2两个拨码开关都支持左右两种设置状态,所以总共有4种设置状态,开发板目前只使用了其中的三种。不同的设置状态对应的启动设备如下所示:
| BOOT1 | BOOT2 | 启动设备 |
|---|---|---|
| 左 | 左 | 未使用 |
| 右 | 左 | SSD |
| 左 | 右 | eMMC |
| 右 | 右 | TF 卡 |
1.2 硬件规格
| CPU | 4核64位ARM处理器 + AI处理器(昇腾310B4) |
|---|---|
| GPU | 集成图形处理器 |
| AI算力 | 8TOPS |
| 内存 | LPDDR4X,速率:3200Mbps |
| 存储 | 板载32MB SPI Flash;TF 卡插槽;eMMC 插座,eMMC5.1 HS400;M.2 M-Key接口(2280,PCIe3.0X4) |
| 以太网 | 支持10/100/1000Mbps |
| WiFi+蓝牙 | 支持2.4G和5G双频WIFI;BT4.2/BLE |
| USB | 2个USB3.0 Host接口;1个Type-C接口(只支持USB3.0,不支持USB2.0),Micro USB x1 串口打印功能 |
| 摄像头 | 2个MIPI CSI 2Lane接口,兼容树莓派摄像头 |
| 显示 | 2个HDMI2.0 接口,Type-A TX 4K@60FPS;1个MIPI DSI 2Lane接口,via FPC connector |
| 音频 | 1个3.5mm耳机孔,支持音频输入输出 |
| GPIO | 40 pin扩展口,用于扩展GPIO、UART、I2C、SPI、 I2S、PWM |
| 按键 | 1个复位键,1个关机键,1个烧录按键 |
| 拨码开关 | 2个拨码开关:用于控制SD卡、eMMC和SSD启动选项 |
| 电源 | 支持Type-C供电,20V PD-65W适配器 |
| LED灯 | 1个电源指示灯和1个软件可控指示灯 |
| 风扇接口 | 4pin,0.8mm间距,用于接12V风扇,支持PWM控制 |
| 电池接口 | 2pin,2.54mm间距,用于接3串电池,支持快充 |
| 调试串口 | Micro USB接口的调试串口 |
| 支持的操作系统 | Ubuntu 22.04和openEuler 22.03 |
| 板卡尺寸 | 107*68mm |
2 上电
2.1 ubuntu 系统烧录与配置
OrangePi Kunpeng Pro 开发板的内存卡里面预装了官方的 openEuler 系统,这个系统之前没有接触过,使用起来不是很方便,因此自己重新安装了官方的 ubuntu-22.04 的操作系统。
2.1.1 系统烧录
-
先准备一张32GB或更大容量的TF卡,,TF卡的传输速度必须为class10级或class10级以上。
把TF卡插入读卡器,再把读卡器插入windows电脑。 -
从官方ubuntu镜像下载OrangePi Ai Pro 的 ubuntu 镜像压缩包(因为目前官方只提供了 openEuler 的镜像,不过 OrangePi Ai Pro 的 ubuntu 镜像在 OrangePi Kunpeng Pro 上也可以完美使用)
-
下载用于烧录Linux镜像的软件——balenaEtcher,下载地址为:https://www.balena.io/etcher/
-
烧录系统到 TF 卡
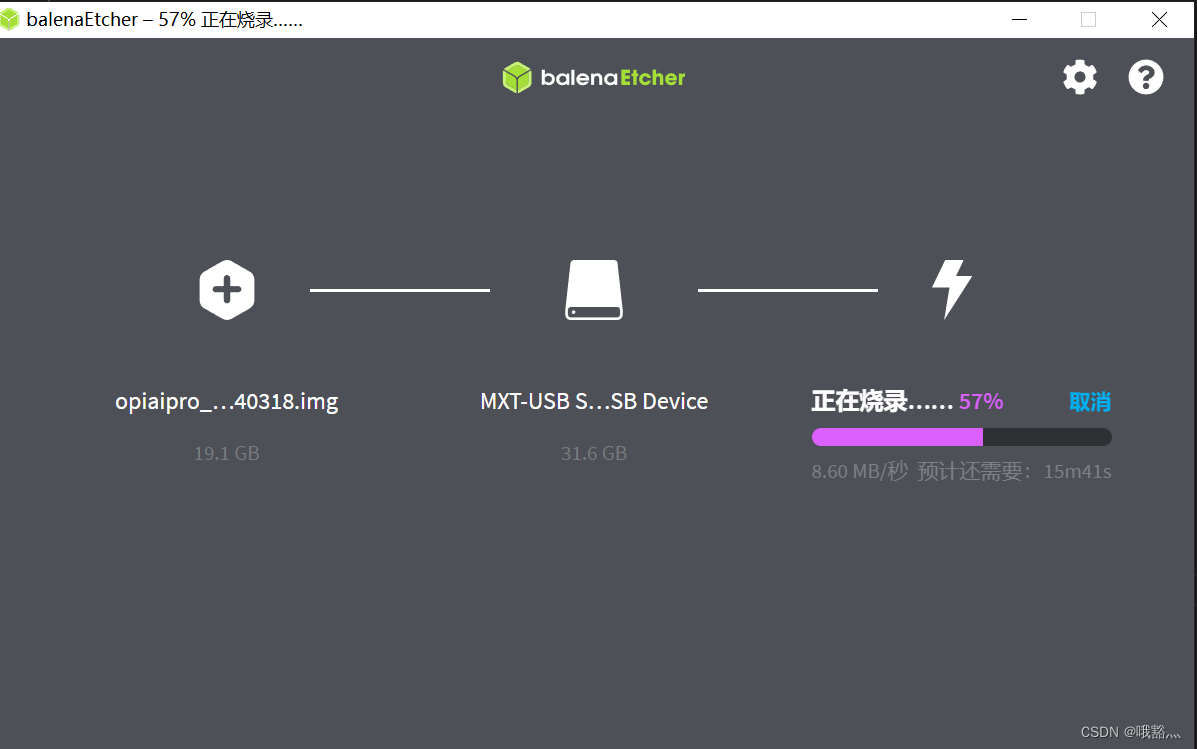
打开后的balenaEtcher界面如下图所示:

使用balenaEtcher烧录 Linux镜像的具体步骤:
- 选择要烧录的Linux镜像文件的路径。
- 后选择TF卡的盘符
- 点击Flash就会开始烧录Linux镜像到TF卡中。
balenaEtcher 烧录 Linux 镜像的过程显示的界面如下图所示,进度条显示紫色表示正在烧录Linux镜像到TF卡中:
镜像烧录完后,balenaEtcher默认还会对烧录到TF卡中的镜像进行校验,确保烧录过程没有出问题。
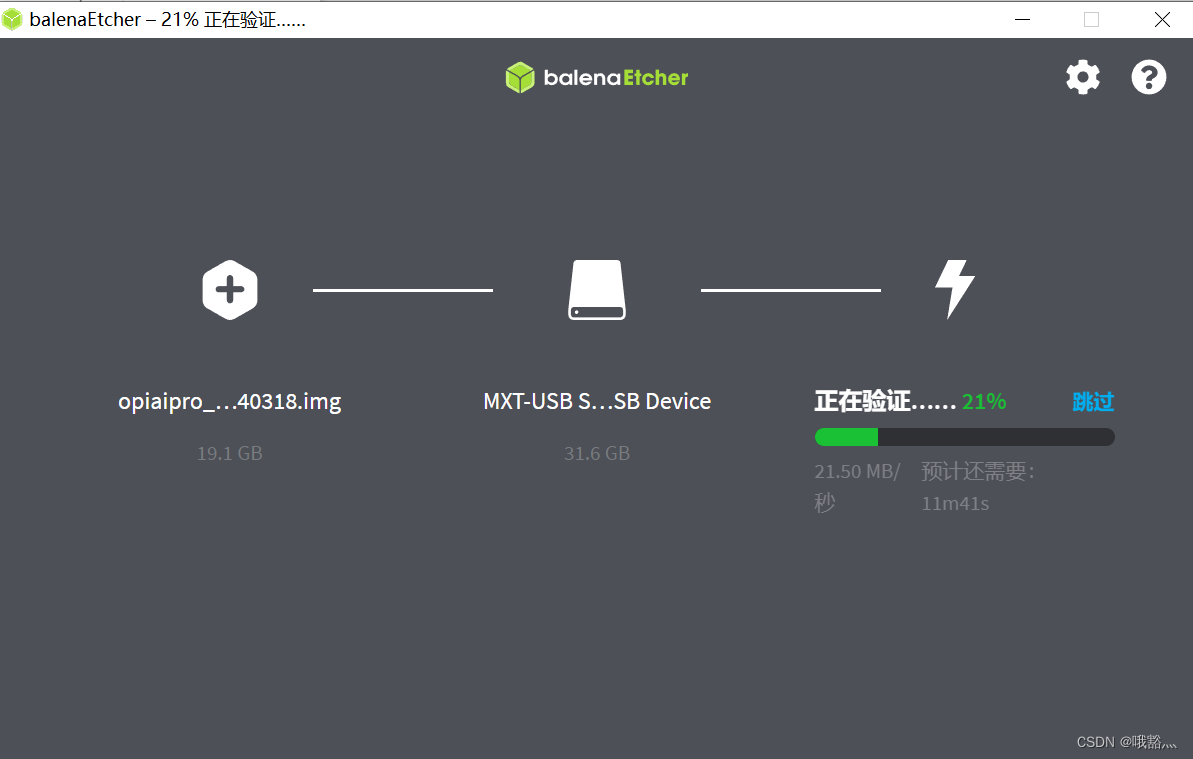
我在烧录过程中,最后校验完成后提示校验失败,但是把卡插上开发板,还是能够进入 ubuntu 系统。这里校验失败可能就是前面使用了 OrangePi Ai Pro 的 ubuntu 镜像导致的,但是系统在 OrangePi Kunpeng Pro 上可以完美运行。
2.1.2 远程连接
- ssh 登录
Linux 系统默认都开启了ssh远程登录,并且允许root用户登录系统。ssh 登录之前先获取到开发板的 IP 地址,可以通过路由器后台查看,也可以连接显示器之后使用ifconfig命令查看。
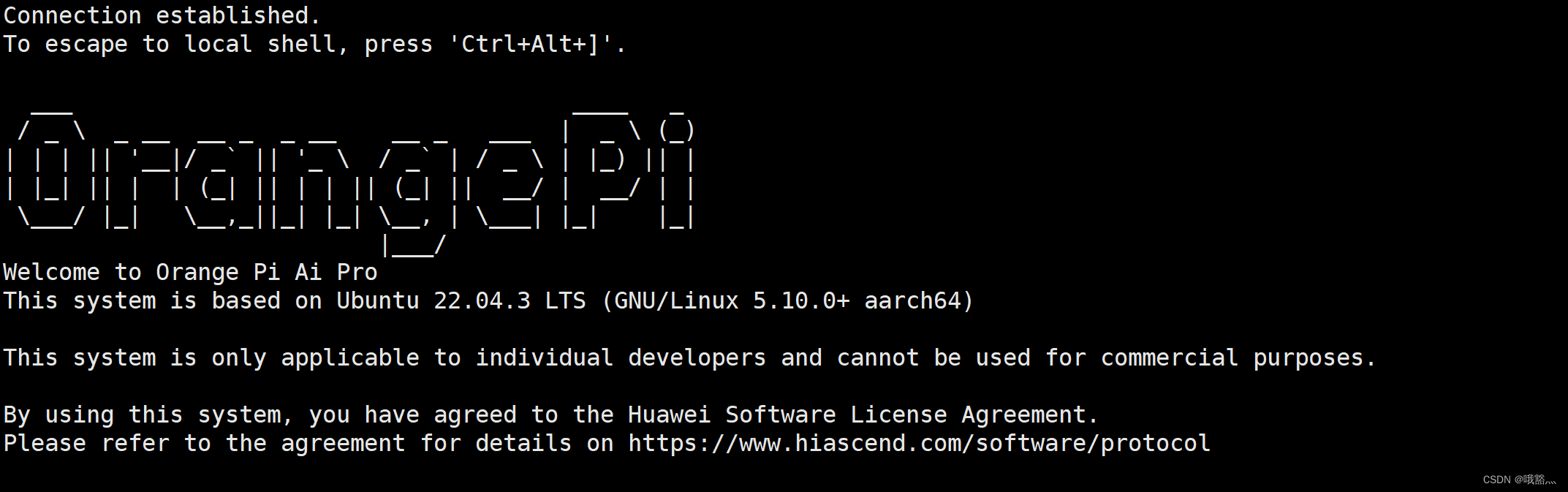
然后就可以通过ssh命令远程登录Linux系统。 windows 下可以使用各种终端工具来登录,例如 MobaXterm、XShell。Linux 下直接在终端连接即可:
ssh HwHiAiUser@192.168.xx.xxx
成功登录系统后的显示如下图所示:
-
安装并配置 VNC 服务
sudo apt update sudo apt install tigervnc-standalone-server tigervnc-common # 安装TigerVNC服务器及其依赖项 sudo systemctl stop ufw #关闭防火墙vncserver # 提示输出密码,密码为后续vnc view登录该账户的密码。会自动创建一个vncserver 进程# 创建启动脚本 vim ~/.vnc/xstartup # 并向其中添加以下内容: #!/bin/sh unset SESSION_MANAGER unset DBUS_SESSION_BUS_ADDRESS exec startxfce4 sudo chmod +x ~/.vnc/xstartup# 启动 vncserver :1 -geometry 1920x1080 -depth 24 -localhost no# 查看是否启动成功 ps -aux |grep -i vnc# 设置开机自启vnc sudo vim ~/.bash_profile # 以下内容写入文件中 vncserver :1 -geometry 1920x1080 -depth 24 -localhost no -
VNC 远程桌面登录
这里输入开发板的 IP 和端口号

在提示下输入密码即可进入远程桌面。这里应该是由于前面烧录的是 OrangePi Ai Pro 的 ubuntu 镜像,这里
neofetch,命令打印的 Host 是 Orange Pi Ai Pro。

2.1.3 网络连接
OrangePi Kunpeng Pro 支持 wifi 和千兆有线网络。开发板上的无线网络天线信号非常好,比我的笔记本的要好用(不过由于我的路由器在夏天“高烧”,为了减轻路由器的压力,后面的测试都是通过网线连接有线网络进行的。小声称赞,千兆网口真好用,后面具体用到了再大声称赞。)。不过需要注意的是,在开发板上电的时候,不要让天线接触开发板,避免因为天线导电导致短路烧毁开发板。
避免因为动态 IP 在远程连接的时候需要查开发板的 IP,可以使用nmcli命令来设置静态IP地址。
如果要设置网口的静态IP地址,需要先将网线插入开发板,如果需要设置WIFI的静态IP地址,需要先连接好WIFI,然后再开始设置静态IP地址。
-
通过
nmcli con show命令查看网络设备的名字

哦豁灬是所连接的wifi的名称Wired connection 1为以太网接口的名字
-
设置静态 IP 地址
sudo nmcli con mod "Wired connection 1" \ipv4.addresses "192.168.1.110" \ipv4.gateway "192.168.1.1" \ipv4.dns "8.8.8.8" \ipv4.method "manual"- “Wired connection 1” 表示设置以太网口的静态 IP地址,如果需要设置 WIFI 的静态 IP 地址,修改为WIFI网络接口对应的名字(通过
nmcli con show命令可以获取到)。 - ipv4.addresses 后面是要设置的静态 IP地址,可以修改为自己想要设置的值。
- ipv4.gateway 表示网关的地址
- “Wired connection 1” 表示设置以太网口的静态 IP地址,如果需要设置 WIFI 的静态 IP 地址,修改为WIFI网络接口对应的名字(通过
-
重启开发板
sudo reboot -
查看修改是否成功
ip addr show eth0
2.1.4 散热风扇设置
由于 OrangePi Kunpeng Pro 在有负载的时候有一定的发热量,散热风扇默认的自动模式比较保守,转速有些低,可以把散热风扇切换为手动模式,并根据负载和发热情况设置合适的风扇调速比,使用npu-smi命令可以查询和控制PWM风扇。
-
使用
npi-smi info命令可以查看 npu core 的信息,包括温度
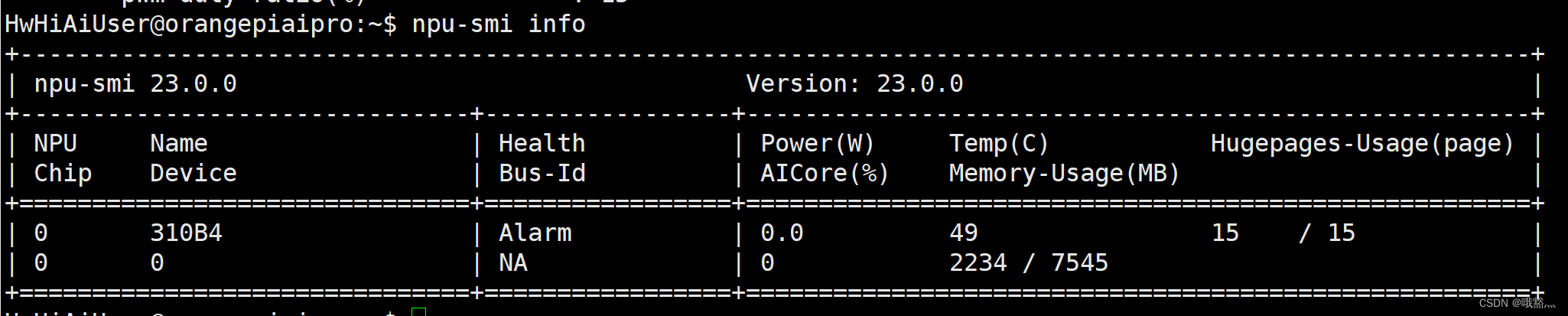
可以看出来。待机状态下 AICore 的温度为 49 摄氏度。
-
查询风扇模式
sudo npu-smi info -t pwm-mode # wm-mode : auto,可以看到默认是自动模式# 有两种模式: manual:手动模式;auto:自动模式 -
查询风扇调速比
sudo npu-smi info -t pwm-duty-ratio # pwm-duty-ratio(%) : 15,可以看到待机状态自动挡的调速比为 15% -
设置风扇模式为手动模式并来设置风扇的调速比
sudo npu-smi set -t pwm-mode -d 0# Status : OK# Message : Set pwm manual mode success# 风扇使能模式。分为手动模式、自动模式。默认为自动模式。 # 0:手动模式 # 1:自动模式set -t pwm-duty-ratio -d 30 # 将风扇调速比设置为 30%# Status : OK# Message : Set pwm duty ratio 30 success
2.1.5 AI CPU 和 control CPU 设置
OrangePi Kunpeng Pro 使用的昇腾SOC总共有4个CPU,这4个CPU既可以设置为 control CPU,也可以设置为 AI CPU。默认情况下,controlCPU 和 AICPU 的分配数量为 3:1。使用npu-smi info -t cpu-num-cfg -i 0 -c 0命令可以查看下 controlCPU 和 AI CPU 的分配数量。

因此在默认情况下,在 CPU 跑满的时候,使用htop命令会看到有一个CPU的占用率始终接近0,这是正常的。因为这个CPU默认用于 AI CPU。

可以使用npu-smi info -t usages -i 0 -c 0命令查看 AI CPU 的使用率,

如果不需要使用 AI CPU,使用sudo npu-smi set -t cpu-num-cfg -i 0 -c 0 -v 0:4:0命令将4个CPU都设置为 control CPU。设置完后需要重启系统让配置生效。
2.1.6 设置 swap 内存
手上拿到的 OrangePi Kunpeng Pro 的内存是 8GB 的,考虑到后面可能会跑一些有一定内存需求的项目,可以通过Swap内存来扩展系统能使用的最大内存容量。
-
创建一个swap文件
sudo fallocate -l 4G /swapfile # 手上只有 32GB 的内存卡,装完 ubuntu 22.04 之后,只剩 11GB 了,考虑到后面配置环境开需要使用一部分,这里先暂时拓展 4GB 的 swap 内存 -
修改文件权限,确保只有root用户可以读写
sudo chmod 600 /swapfile -
把这个文件设置成swap空间
sudo mkswap /swapfile -
启用swap
sudo swapon /swapfile# 修改/etc/fstab文件,使系统启动时自动加载此交换分区 sudo vim /etc/fstab # 在文件末尾添加如下行: /swapfile swap swap defaults 0 0 -
检查swap内存是否已经添加成功
free -h
2.1.7 开发环境配置
-
conda & pip 配置
echo "export PATH=/usr/local/miniconda3:$PATH" >> ~/.bashrc && source ~/.bashrc # 官方的ubuntu镜像自带 conda,但是不在环境变量中,需要把 conda 加入到环境变量# 进入 conda bash 环境 conda activate base# 安装 pip sudo apt-get install python3-pip# 替换 pip 源 mkdir ~/.pip sudo vim ~/.pip/pip.conf # 把文件内容修改为如下内容(清华源) [global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple/ [install] trusted-host = pypi.tuna.tsinghua.edu.cn -
安装必要的 python 包
pip install torch transformers onnx protobuf onnxruntime cloudpickle decorator psutil scipy synr==0.5.0 tornado absl-py getopt inspect multiprocessing
- C/C++ 环境
官方的 ubuntu 镜像包含了gcc/g++/cmake等必要的工具了
3 性能测试
OrangePi Kunpeng Pro 的这个昇腾310B4处理器以前没有接触过,不知道实际性能怎么样,那就跑个分看看吧。
3.1 室温下CPU温度
在室温 22 摄氏度的条件下,待机状态下,使用npu-smi info命令查看CPU温度:43摄氏度

3.2 lscpu命令
可以看到,OrangePi Kunpeng Pro 的 BogoMIPS 是 96,MIPS 是 millions of instructions per second(百万条指令每秒)的缩写,其代表CPU的运算速度,是cpu性能的重要指标。但只能用来粗略计算处理器的性能,并不十分精确。

3.3 软件 CPU 跑分
这里使用 Sysbench 这个软件来测试CPU的性能。
Sysbench是一个开源的、模块化的、跨平台的多线程性能测试工具,可以用来进行CPU、内存、磁盘I/O、线程、数据库的性能测试。
安装使用命令 sudo apt-get install sysbench
测试CPU命令 sysbench cpu run
其中CPU speed: events per second是衡量CPU速度的指标。
在单线程下,OrangePi Kunpeng Pro 的是:2060.64

4 AI 应用样例体验
在官方的 ubuntu 镜像中预装了 JupyterLab 软件。Jupyter Lab 软件是一个基于web的交互式开发环境,集成了代码编辑器、终端、文件管理器等功能。
4.1 登录 juypterlab
# 切换到保存AI应用样例的目录下
cd samples/notebooks/# 安装 jupyter
sudo apt-get install jupyter# 执行start_notebook.sh脚本启动 Jupyter Lab
./start_notebook.sh# 根据终端中打印出来的登录Jupyter Lab的网址链接在浏览器中登录JupyterLab软件
也可以利用官方的 sample 样例,自己写推理脚本来执行不同的 AI 应用。后面将自己编写推理脚本来执行AI 样例应用。
准备好训练好的 onnx 模型,可以直接使用 onnxruntime 来执行推理任务。为了进一步优化模型推理性能,更好的发挥 OrangePi Kunpeng Pro 硬件的 AI 性能,可以借助官方提供的工具将 onnx 模型转换为 om 模型进行使用,转换指令:
atc --model=yolov5s.onnx --framework=5 --output=yolo --input_format=NCHW --input_shape="input_image:1,3,640,640" --log=error --soc_version=Ascend310B1
其中转换参数的含义:
- –model,输入 onnx 模型的路径
- –framework,原始网络模型框架类型,5 表示 onnx
- –output,输出模型路径
- –input_format,输入 tensor 的内存配列方式
- –input_shape,指定模型输入数据的类型
- –log,日志级别
- –soc_version,昇腾 AI 处理器型号
- –input_fp16_nodes,指定输入数据类型为 fp16 的输入节点的名称
- –output_type,指定网络输出数据类型或者指定某个输出节点的输出类型
后面执行 AI 程序也都会把 onnx 转换成 om 模型来跑。
4.2 文字识别
OCR一般指 SceneText Recognition(场景文字识别),主要面向自然场景。
进入 ocr 样例目录:cd ~/samples/notebooks/02-ocr,可以看到目录下有两个模型,ctpn.om 是基于 faster rcnn 模型修改而来,作为检测模型负责找出图像或视频中的文字位置;svtr.om 是基于近几年十分流行的 vision transformer 模型,作为识别模型负责将图像信息转换为文本信息。

-
文字识别(OCR)的模型推理主要有以下几个步骤:
-
前处理
前处理的主要目的是将输入处理成模型需要的输入格式,最常见的比如NLP任务中使用的 tokenlizer,CV 任务中使用的标准化/色域转换/缩放等操作 -
CTPN
CTPN 模型的前处理由简单的 resize 和 Normalization 组成,代码如下所示def preprocess(self, img):# resize image and convert dtype to fp32dst_img = cv2.resize(img, (int(self.model_width), int(self.model_height))).astype(np.float32)# normalizationdst_img -= self.meandst_img /= self.std# hwc to chwdst_img = dst_img.transpose((2, 0, 1))# chw to nchwdst_img = np.expand_dims(dst_img, axis=0)dst_img = np.ascontiguousarray(dst_img).astype(np.float32)return dst_img -
SVTR
SVTR 模型的前处理和 CTPN 稍有不一样,除了 resize 和 Normalization 之外,为了保证图片缩放后的宽高比以及符合模型输入的 shape,我们还需要对其做 Padding 操作,代码如下所示def preprocess(self, img):h, w, _ = img.shaperatio = w / hif math.ceil(ratio * self.model_height) > self.model_width:resize_w = self.model_widthelse:resize_w = math.ceil(ratio * self.model_height)img = cv2.resize(img, (resize_w, self.model_height))_, w, _ = img.shapepadding_w = self.model_width - wimg = cv2.copyMakeBorder(img, 0, 0, 0, padding_w, cv2.BORDER_CONSTANT, value=0.).astype(np.float32)img *= self.scaleimg -= self.meanimg /= self.std# hwc to chwdst_img = img.transpose((2, 0, 1))# chw to nchwdst_img = np.expand_dims(dst_img, axis=0)dst_img = np.ascontiguousarray(dst_img).astype(np.float32)return dst_img -
推理接口
两个模型的推理接口部分是相似的,在复制输入数据至模型输入的地址之后我们调用 execute api 就可以推理了def infer(self, tensor):np_ptr = acl.util.bytes_to_ptr(tensor.tobytes())# copy input data from host to deviceret = acl.rt.memcpy(self.input_data[0]["buffer"], self.input_data[0]["size"], np_ptr,self.input_data[0]["size"], ACL_MEMCPY_HOST_TO_DEVICE)# infer execret = acl.mdl.execute(self.model_id, self.load_input_dataset, self.load_output_dataset)inference_result = []for i, item in enumerate(self.output_data):buffer_host, ret = acl.rt.malloc_host(self.output_data[i]["size"])# copy output data from device to hostret = acl.rt.memcpy(buffer_host, self.output_data[i]["size"], self.output_data[i]["buffer"],self.output_data[i]["size"], ACL_MEMCPY_DEVICE_TO_HOST)data = acl.util.ptr_to_bytes(buffer_host, self.output_data[i]['size'])data = np.frombuffer(data, dtype=self.output_dtypes[i]).reshape(self.output_shapes[i])inference_result.append(data)return inference_result -
后处理
CTPN 与传统的检测模型的后处理相似,CTPN 的后处理也有着 NMS 等操作。与之不同的是 CTPN 使用了文本线构造方法使多个 bbox 组成了一个文本框:def postprocess(self, output):proposal = output[0]proposal_mask = output[1]all_box_tmp = proposalall_mask_tmp = np.expand_dims(proposal_mask, axis=1)using_boxes_mask = all_box_tmp * all_mask_tmptextsegs = using_boxes_mask[:, 0:4].astype(np.float32)scores = using_boxes_mask[:, 4].astype(np.float32)bboxes = detect(textsegs, scores[:, np.newaxis], (self.model_height, self.model_width))return bboxessvrt 与大部分文本识别模型相似,SVTR 的后处理就是一个简单的 Argmax 操作之后查表的过程:
def postprocess(self, output):output = np.argmax(output[0], axis=2).reshape(-1)ans = []last_char = ''for i, char in enumerate(output):if char and self.labels[char] != last_char:ans.append(self.labels[char])last_char = self.labels[char]return ''.join(ans)
-
-
编写推理脚本
infer.py:
import cv2
import numpy as np
import ipywidgets as widgets
from IPython.display import display
import torch
from skvideo.io import vreader, FFmpegWriter
import IPython.display
# from ais_bench.infer.interface import InferSession
import onnxruntimefrom det_utils import letterbox, scale_coords, nmsdef preprocess_image(image, cfg, bgr2rgb=True):"""图片预处理"""img, scale_ratio, pad_size = letterbox(image, new_shape=cfg['input_shape'])if bgr2rgb:img = img[:, :, ::-1]img = img.transpose(2, 0, 1) # HWC2CHWimg = np.ascontiguousarray(img, dtype=np.float32)return img, scale_ratio, pad_sizedef draw_bbox(bbox, img0, color, wt, names):"""在图片上画预测框"""det_result_str = ''for idx, class_id in enumerate(bbox[:, 5]):if float(bbox[idx][4] < float(0.05)):continueimg0 = cv2.rectangle(img0, (int(bbox[idx][0]), int(bbox[idx][1])), (int(bbox[idx][2]), int(bbox[idx][3])),color, wt)img0 = cv2.putText(img0, str(idx) + ' ' + names[int(class_id)], (int(bbox[idx][0]), int(bbox[idx][1] + 16)),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)img0 = cv2.putText(img0, '{:.4f}'.format(bbox[idx][4]), (int(bbox[idx][0]), int(bbox[idx][1] + 32)),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)det_result_str += '{} {} {} {} {} {}\n'.format(names[bbox[idx][5]], str(bbox[idx][4]), bbox[idx][0], bbox[idx][1], bbox[idx][2], bbox[idx][3])return img0def get_labels_from_txt(path):"""从txt文件获取图片标签"""labels_dict = dict()with open(path) as f:for cat_id, label in enumerate(f.readlines()):labels_dict[cat_id] = label.strip()return labels_dictdef draw_prediction(pred, image, labels):"""在图片上画出预测框并进行可视化展示"""imgbox = widgets.Image(format='jpg', height=720, width=1280)img_dw = draw_bbox(pred, image, (0, 255, 0), 2, labels)imgbox.value = cv2.imencode('.jpg', img_dw)[1].tobytes()display(imgbox)def infer_image(img_path, model, class_names, cfg):"""图片推理"""image = cv2.imread(img_path)img, scale_ratio, pad_size = preprocess_image(image, cfg)output = model.infer([img])[0]output = torch.tensor(output)boxout = nms(output, conf_thres=cfg["conf_thres"], iou_thres=cfg["iou_thres"])pred_all = boxout[0].numpy()scale_coords(cfg['input_shape'], pred_all[:, :4], image.shape, ratio_pad=(scale_ratio, pad_size))draw_prediction(pred_all, image, class_names)def infer_frame_with_vis(image, model, labels_dict, cfg, bgr2rgb=True):# 数据预处理img, scale_ratio, pad_size = preprocess_image(image, cfg, bgr2rgb)# output = model.infer([img])[0]output = model.run([img])[0]output = torch.tensor(output)boxout = nms(output, conf_thres=cfg["conf_thres"], iou_thres=cfg["iou_thres"])pred_all = boxout[0].numpy()scale_coords(cfg['input_shape'], pred_all[:, :4], image.shape, ratio_pad=(scale_ratio, pad_size))img_vis = draw_bbox(pred_all, image, (0, 255, 0), 2, labels_dict)return img_visdef img2bytes(image):"""将图片转为字节码"""return bytes(cv2.imencode('.jpg', image)[1])def infer_video(video_path, model, labels_dict, cfg):"""视频推理"""image_widget = widgets.Image(format='jpeg', width=800, height=600)display(image_widget)cap = cv2.VideoCapture(video_path)while True:ret, img_frame = cap.read()if not ret:breakimage_pred = infer_frame_with_vis(img_frame, model, labels_dict, cfg, bgr2rgb=True)image_widget.value = img2bytes(image_pred)def infer_camera(model, labels_dict, cfg):"""外设摄像头实时推理"""def find_camera_index():max_index_to_check = 10 # Maximum index to check for camerafor index in range(max_index_to_check):cap = cv2.VideoCapture(index)if cap.read()[0]:cap.release()return index# If no camera is foundraise ValueError("No camera found.")camera_index = find_camera_index()cap = cv2.VideoCapture(camera_index)image_widget = widgets.Image(format='jpeg', width=1280, height=720)display(image_widget)while True:_, img_frame = cap.read()image_pred = infer_frame_with_vis(img_frame, model, labels_dict, cfg)image_widget.value = img2bytes(image_pred)cfg = {'conf_thres': 0.4, 'iou_thres': 0.5, 'input_shape': [640, 640],
}model_path = 'yolo.om'
label_path = './coco_names.txt'
onnx_model_path = './yolov5s.onnx'
# model = InferSession(0, model_path)
model = onnxruntime.InferenceSession(onnx_model_path)
labels_dict = get_labels_from_txt(label_path)infer_mode = 'video'if infer_mode == 'image':img_path = 'world_cup.jpg'infer_image(img_path, model, labels_dict, cfg)
elif infer_mode == 'camera':infer_camera(model, labels_dict, cfg)
elif infer_mode == 'video':video_path = 'racing.mp4'infer_video(video_path, model, labels_dict, cfg)
- 开始推理
python3 infer.py
推理脚本执行过程中会在 terminal 中输出识别到的文字信息:

待识别的图片是当前路径下的 sample.png:

除此之外,还会在当前目录下存储推理的结果到 infer_result 文件夹中:

打开 infer_result/sample_res.png,可以看到在到识别图片中使用红色的框框出了图片中的文字:

框选出的内容与 terminal 中输出的文字结果一致。
这里只跑了图片的 OCR,上面的推理代码也支持视频和摄像头的视频源的实时识别。
OrangePi Kunpeng Pro 具有强大的 AI 算力,执行 CV 模型毫无压力,出结果速度也非常快。前面 ocr 模型也使用到了 vision transformer 模型,那么,基于 transformer 的大语言模型是否也可以部署并轻松跑起来呢?
5 推理大模型
OrangePi Kunpeng Pro 在前面的 CV 模型的表现非常出色,那么对于当下火热的大语言模型,开发板表现如何呢?考虑到开发板的内存大小这里使用 Google 开源的 gemma-2b-it 模型进行实验。后面对模型进行量化的时候,再使用规模更大的 Meta 最新开源的 llama3-8b。
在这里,由于大语言模型的权重比较大,我使用的 tf 卡所剩空间不多,因此就把大模型的权重存放在另外一台机器上,这台机器和 OrangePi Kunpeng Pro 都通过网线连接到同一台千兆交换机上,再把这台机器的硬盘挂载到 OrangePi Kunpeng Pro 上。得益于 OrangePi Kunpeng Pro 的千兆网口,这里在跑大模型的时候,OrangePi Kunpeng Pro 从另一台机器上搬运模型权重的时候,网络带宽基本没有形成瓶颈。
5.1 pytorch 推理
这里为了方便写推理脚本,在 OrangePi Kunpeng Pro 的 workspace 下把挂载在 OrangePi Kunpeng Pro 上的硬盘内的 gemma-2b-it 软链接了过来。

Hugging Face 的 Transformers 已经支持了 Gemma 模型,使用 pytroch 直接推理 gemma-2b-it 很简单,推理脚本只需要几行就够了:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
set_seed(1234) # For reproducibility
prompt = "The best recipe for pasta is"
checkpoint = "./gemma-2b-it"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, torch_dtype=torch.float16, device_map="cpu")
inputs = tokenizer(prompt, return_tensors="pt").to('cpu')
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=150)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
直接执行脚本开始推理python3 run_gemma-2b-it.py。
在推理过程中,load 模型耗时比较久,这个过程需要把模型的权重从硬盘搬到内存中。对于 gemma-2b-it,load 模型花费了 224 秒:

由于这里使用 pytorch 进行推理,只能使用 CPU 来计算,因此也只能使用 float32 数据类型。在推理过程中,四个 control core 都满载了,内存占用为 5.85GB。

模型权重 load 进来之后,就是真正的推理过程了。推理过程耗时 282 秒:

由于是没有量化的模型,使用 pytorch 推理,基本没有精度损失,因此虽然 gemma-2b-it 的模型规模不大,但是模型的输出效果还是比较好的。
由于推理脚本中设置了max_new_tokens=150,可以看到最后模型的输出被截断了,因此这里一共输出了 150 个 tokens,那么很容易得到,使用 OrangePi Kunpeng Pro 纯 CPU 推理的情况下,gemma-2b-it 能达到 0.53 tokens/s。这个结果还是挺超出预期的,毕竟是使用 CPU 推理,并且跑的是 float32的,能跑出来已经很惊喜了。
5.2 使用 llama.cpp 量化部署
让 OrangePi Kunpeng Pro 的 CPU 使用 float32 进行大模型推理确实是有些难为它了。对于大模型推理这种对数据精度要求不高,并且还是在这种边缘计算定位的设备上,还是先将模型量化到低精度再跑更合适一些。考虑到 OrangePi Kunpeng Pro 的 npu 的特殊性,这里还是选择使用 CPU 来跑推理,因此使用 llama.cpp 来对模型进行量化和部署。
-
克隆和编译llama.cpp,拉取 llama.cpp 仓库最新代码
git clone https://github.com/ggerganov/llama.cpp.git -
对llama.cpp项目进行编译,生成./main(用于推理)和./quantize(用于量化)二进制文件
make -j4
开发板的CPU算力和内存有限,可以在PC上使用 llama.cpp 对大模型进行量化编译处理,详细操作可以参考 使用llama.cpp量化部署LLM。
使用在PC上量化编译好的 .gguf 格式的模型,在开发板上运行大语言模型。
推理量化至 2bit 的 gemma-2b-it 模型
在 llama.cpp 根目录下,执行命令 ./main -m /rpi_hdd2/gemma-2b-it/ggml-model-q2_k.gguf --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3 来推理量化至 2bit 的 gemma-2b-it 模型:

使用和 pytorch 推理的时候相同的提示词,这次的推理速度快了很多,最后的结果统计里可以看到,真正的推理阶段的速度有 4.36 tokens/s。但是由于 gemma-2b-it 模型本身模型规模很小,并且被量化到了 2bit,精度损失非常大,因此回答的结果不尽人意,甚至都乱码了。

推理量化至 2bit 的 llama3-8b 模型
那么使用更大规模的模型呢?我们紧接着跑量化至 2bit 的 llama3-8b 模型,命令./main -m /rpi_hdd2/llama_cpp_model/ggml-model-q2_k.gguf --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3:

使用更大规模的模型,量化至 2bit 的 llama3-8b 模型的输出就好很多了,同时推理速度也下降到了 1.56 tokens/s,但是模型的回答效果好了很多:

推理量化至 4bit 的 llama3-8b 模型
我们把 llama3-8b 量化到 4bit,继续使用 CPU 推理./main -m /rpi_hdd2/llama_cpp_model/ggml-model-q4_0.gguf --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3:

随着量化精度的提高,模型的回答效果肉眼可见的变好了,并且还能够保持 1.47 tokens/s的推理速度,与 2bit 的模型推理速度差距很小。

5.3 优化方向
前面的方式都是使用 CPU 来跑的大模型退,没有真正发挥出 OrangePi Kunpeng Pro 的AI性能,本次测评时间有限,后面还会尝试将大语言模型转换成 OrangePi Kunpeng Pro 支持的 om 模型,更多地调用 OrangePi Kunpeng Pro 的 AI core,进一步发掘开发板的 AI 性能,相信 OrangePi Kunpeng Pro 在大语言模型上会有更加亮眼的表现。
6 总结
开发板的整体体验远超出预期,作为低功耗 AI 边缘计算开发板,支持Ubuntu、openEuler操作系统,能够满足大多数AI算法原型验证、推理应用开发的需求,结合昇腾 AI 生态支持,在 CV 网络上的表现令人满意。更让人意外的是,甚至对于大语言模型也有一战之力。
开发板是一块很值得尝试的开发板,IO 接口丰富,拓展性强,可玩性很高,可广泛适用于AI边缘计算、深度视觉学习及视频流AI分析、视频图像分析、自然语言处理、智能小车、机械臂、人工智能、无人机、云计算、AR/VR、智能安防、智能家居等领域。
这篇关于OrangePi Kunpeng Pro 开发板测评 | AI 边缘计算 大模型部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








