本文主要是介绍WWW24因果论文(2/8) |多模因果结构学习与根因分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

【摘要】有效的根本原因分析 (RCA) 对于快速恢复服务、最大限度地减少损失以及确保复杂系统的平稳运行和管理至关重要。以前的数据驱动的 RCA 方法,尤其是那些采用因果发现技术的方法,主要侧重于构建依赖关系或因果图来回溯根本原因。然而,这些方法往往存在不足,因为它们仅依赖于单一模态的数据,从而导致次优解决方案。在这项工作中,我们提出了 Mulan,一种用于根本原因定位的统一多模态因果结构学习方法。我们利用日志定制的语言模型来促进日志表示学习,将日志序列转换为时间序列数据。为了探索不同模态之间的复杂关系,我们提出了一种基于对比学习的方法来在共享潜在空间中提取模态不变和模态特定的表示。此外,我们引入了一种新颖的关键绩效指标感知注意力机制,用于评估模态可靠性和共同学习最终的因果图。最后,我们采用带重启的随机游走来模拟系统故障传播并识别潜在的根本原因。在三个真实数据集上进行的大量实验验证了我们提出的框架的有效性。
原文:Multi-modal Causal Structure Learning and Root Cause Analysis
地址:https://arxiv.org/abs/2402.02357
代码:未知
出版:www 24
机构: NEC Laboratories America, University of Illinois at Urbana-Champaign写的这么辛苦,麻烦关注微信公众号“码农的科研笔记”!
1 研究问题
本文研究的核心问题是: 如何利用多模态数据进行因果结构学习,以更准确地定位复杂系统故障的根本原因。
以一个在线商店的微服务系统为例。系统收集了各种性能指标(如CPU使用率)和日志数据。某天系统出现异常,导致用户无法登录。运维人员需要快速查明故障根源,以尽早恢复服务。传统方法主要依赖单一模态(如只看性能指标),很可能会遗漏关键线索,延误问题定位。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
系统日志是非结构化文本数据,缺乏标准语法,大量使用特殊token,给表示学习带来困难。现有语言模型很难直接应用。
-
不同模态数据蕴含着互补的因果关系信息。单纯提取共性特征可能损失每个模态的独特见解。需要兼顾不变性和特异性表示。
-
实际场景中经常存在某些模态质量较差的情况,比如有噪音的指标或冗余的日志。把所有模态一视同仁会影响整体效果。
针对这些挑战,本文提出了一种融合对比学习和注意力机制的"MULAN"框架:
框架就像一位多语种侦探,同时审视案发现场的视频、音频、文字等线索,从不同角度推理因果链条。首先,它请出一位"日志语言专家",将非结构化的日志转化为时间序列嫌疑人名单,为因果推理打好基础。接着,它戴上"对比学习眼镜",既能看到不同模态数据的相同之处,又能捕捉每个模态的独特见解,形成全面的信息图谱。最后,它召开"注意力机制听证会",根据每个模态与系统关键性能指标的相关性,动态调整它们的可信度权重,确保因果链推理不会被个别不可靠的线索误导。通过多轮迭代,侦探最终锁定了几个最可疑的元凶,大大提升了故障诊断的效率和准确性。
2 研究方法
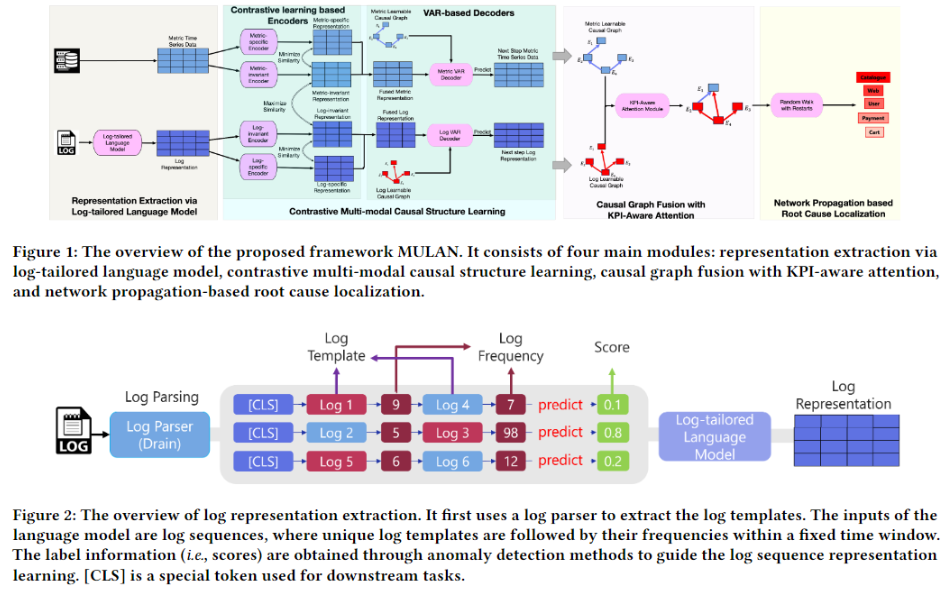
论文提出了一个名为MULAN的统一多模态因果结构学习框架,用于微服务系统中的根因定位。如图1所示,该框架主要由四个模块组成:通过定制化日志语言模型提取日志表示、基于对比学习的多模态因果结构学习、基于KPI感知注意力的因果图融合以及基于网络传播的根因定位。
2.1 日志表示提取
为了便于从系统日志生成因果图,MULAN首先需要将非结构化的日志数据转换为时间序列格式。然而,系统日志缺乏标准语法,大量使用特殊符号,给传统语言模型的应用带来挑战。为此,论文提出了一个定制化的三阶段日志语言模型,如图2所示。
在第一阶段,使用现有的日志解析工具(如Drain)将原始日志结构化为日志模板。第二阶段,将日志划分为固定大小的时间窗口,并为每个实体在每个窗口内组装由唯一日志模板构成的日志序列 。其中日志模板按照首次出现的时间戳升序排列,并在每个模板后附加其在该窗口内的频率信息 。这种方式可以显著降低词汇量,缩短序列长度,同时还能捕捉日志模板的语义信息和频率异常。最后,论文利用基于回归的语言模型来预测日志异常分数 ,其目标函数为:
其中 是由双向Transformer和多层感知机组成的语言模型。通过优化式(3),可以得到每个时间窗口内日志序列 的语义表示 。最终,个系统实体的日志表示可表示为 。
以图2中的示例说明,原始日志被解析为三个日志模板:Event A、Event B和Event C。在某个时间窗口内,实体的日志序列被构建为"Event A [5], Event C [3], Event B [1]",表示Event A 在该窗口内出现5次,Event C出现3次,Event B出现1次。最后,语言模型基于该序列生成实体在该窗口内的日志表示向量。
2.2 多模态因果结构学习
获得系统日志表示后,MULAN利用编码器-解码器结构,通过对比学习的方式提取模态不变和模态特定表示。
给定系统度量数据 和日志表示 ,模态不变编码器 和模态特定编码器 分别提取模态不变表示 和模态特定表示 :
其中 表示不同模态, 是待学习的邻接矩阵, 是有效时间戳长度, 是隐藏特征维度。模态不变表示通过加权融合得到:。 此外, 可视为实体表示,其中 为输出特征维度。
为了确保不同模态提取的不变表示的一致性,论文通过节点级对比正则化最大化它们之间的互信息:
其中, 为余弦相似度。同时为避免模态不变和特定表示之间的信息重叠,论文施加正交约束:
此外,论文还通过边级正则化来保证模态不变表示的质量,具体通过表示边信息来预测因果图的邻接矩阵:
其中, 表示节点 和的表示拼接,而 是一个多层感知机。通过优化式(7),可以更好地捕捉根因与KPI之间的因果关系。
在解码器部分,论文利用VAR模型来预测未来时间步的表示:
其中, 为 模态的未来数据,而 为基于 GraphSage 的解码器。
2.3 因果图融合
为了更好地整合不同模态学习到的因果图 和 ,同时缓解低质量模态的影响,论文设计了一种基于 KPI 感知注意力的融合策略。
首先,论文通过计算每个模态下系统实体原始特征与KPI之间的互相关,来衡量它们之间的因果相关性。互相关分数 的定义为:
其中 表示时间延迟, 为最大时延。直观地, 度量了在考虑最大 时延的情况下,系统实体与KPI之间的最大相似性。越大,表明实体与KPI之间的因果关系越强。
基于互相关分数,论文进一步定义了每个模态的重要性权重:
其中 为 Softmax 函数, 表示模态 下互相关分数最高的 个实体的索引。最后,论文利用注意力权重对不同模态的因果图进行加权融合,得到最终的因果邻接矩阵:
2.4 根因定位
得到最终的因果图 后,为了模拟故障在系统中的传播并找出最可能的根因,论文采用随机游走重启(Random Walk with Restart)算法进行根因定位。
首先,基于因果图 计算转移概率矩阵 :
其中, 表示从一个节点转移到另一个节点的概率。接着,随机游走重启的概率转移方程定义为:
其中, 表示在第 步的跳转概率, 为初始概率分布, 为重启概率。当跳转概率 收敛后,节点的概率值被用于对系统实体进行排序,概率值最高的 个实体被认为是最可能的故障根因。
直观地理解,随机游走重启算法模拟了一个从KPI节点出发的随机游走者,它以 的概率沿着因果图中的边进行转移,以 的概率停留在当前节点。同时,游走者在每一步都有 的概率重启,即回到KPI节点重新开始游走。经过多轮迭代后,游走者访问各节点的频率就反映了它们与KPI之间的因果关联强度。访问频率最高的实体对KPI的影响最大,因此最有可能是故障的根源。
综上,MULAN通过定制化的语言模型、基于对比学习的因果结构提取、KPI感知的注意力融合以及随机游走的根因定位,实现了从多模态数据(系统日志和度量指标)出发的端到端根因定位。该方法能够有效地挖掘不同模态间的互补信息,构建全局因果图,并准确定位微服务系统中故障的根源,为复杂系统的智能运维提供了新的思路。
4 实验
4.1 实验场景介绍
该论文提出了一个多模态因果结构学习方法MULAN用于微服务系统的根本原因定位。论文实验旨在验证MULAN在多个真实数据集上的性能,以及各关键模块的有效性。
4.2 实验设置
-
Datasets:使用三个真实世界的根本原因分析数据集:(1)Product Review (2)Online Boutique (3)Train Ticket。三个数据集都包含系统指标和系统日志两种模态数据。
-
Baseline:PC, Dynotears, C-LSTM, GOLEM, REASON, Nezha
-
Implementation details:实验在一台配备Intel Xeon Silver 4110 CPU和4块11GB GTX2080 GPU的Ubuntu 18.04.5服务器上进行。
-
metric:Precision@K, Mean Average Precision@K, Mean Reciprocal Rank
4.3 实验结果
4.3.1 实验一、MULAN与基线模型在三个数据集上的性能对比

目的: 评估MULAN在多个数据集上的根本原因定位性能,并与多个基线模型进行对比
涉及图表: 表2,表3,表4
实验细节概述:分别在单模态场景和多模态场景下评估所有方法。对于单模态方法,先将系统日志转换为时序数据,再作为附加指标评估。
结果:
-
相比单模态,大多数基线方法在使用多模态数据后性能有所提升
-
MULAN在三个数据集上的各项指标均优于所有基线模型
-
MULAN探索不同模态间关联以及鲁棒的KPI感知注意力是其取得优异性能的关键
4.3.2 实验二、案例分析:低质量模态场景下的模型鲁棒性

目的: 验证MULAN在面对低质量模态时的鲁棒性,以及KPI感知注意力机制的有效性
涉及图表: 图3
实验细节概述:保持系统日志表示不变,选择不同单一系统指标评估所有模型,比较高质量指标和低质量指标下的性能差异
结果:
-
多数基线方法性能会因低质量指标而大幅下降,MULAN则始终保持稳健
-
通过KPI感知注意力,MULAN能动态调整各模态权重,避免过度依赖某一指标
-
实验验证了KPI感知注意力机制的有效性和MULAN的鲁棒性
4.3.3 实验三、MULAN超参数敏感性分析
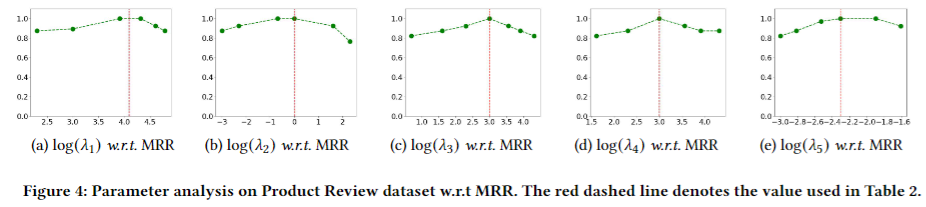
目的: 分析MULAN框架中不同超参数对模型性能的影响
涉及图表: 图4
实验细节概述:针对目标函数中的5个参数,固定其他4个参数,分别调整每个参数的取值,评估模型MRR性能的变化
结果:
-
VAR模型相关的参数λ1取较大值时模型性能更优,说明其在捕捉实体间时序依赖中的重要作用
-
适当的λ2取值有助于平衡其对模型整体性能的贡献
-
节点对比和边预测损失相关的λ3和λ4在一定范围内取值,对取得最优性能至关重要
-
目标函数中加入稀疏正则化项λ5有助于提升性能
4.3.4 实验四、MULAN消融研究
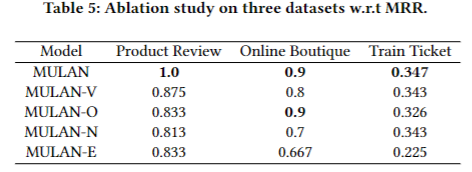
目的: 评估MULAN目标函数中各关键组件对模型性能的影响
涉及图表: 表5
实验细节概述:设计4个MULAN变体,分别移除目标函数中的VAR模型、正交约束、节点对比损失和边预测损失,比较性能变化
结果:
-
与完整MULAN相比,任一组件的移除都会导致性能下降
-
如移除边损失会在两个数据集上分别带来16.7%和23.3%的性能下降
-
实验凸显了各关键组件在保证模型整体有效性中的重要作用
4 总结后记
本论文针对微服务系统中的根因定位问题,提出了一种多模态因果结构学习方法MULAN。该方法利用面向日志的语言模型将非结构化日志转化为时序数据,通过对比学习提取模态不变和模态特定的表示,并设计了KPI感知的注意力机制来评估模态可靠性。最后通过随机游走模拟故障传播,识别出最可能的根因。实验结果表明,MULAN在三个真实数据集上均优于现有方法,为微服务根因定位提供了新的思路。
疑惑和想法:
-
除了度量数据和日志数据,是否可以引入其他形式的观测数据(如tracing数据)来进一步提升性能?
-
在提取模态表示时,除了对比学习,是否可以借鉴多视图表示学习等其他范式?它们在该任务上的优劣如何?
-
在评估模态可靠性时,除了利用KPI信息,是否可以利用更多先验知识(如系统拓扑结构)来指导注意力机制?
可借鉴的方法点:
-
将非结构化日志转化为时序数据的思路可以推广到其他涉及日志数据的任务,如异常检测、系统理解等。
-
通过对比学习来提取不同模态的共享和独有表示的方法可以应用于其他多模态学习场景。
-
根据下游任务动态调整不同模态权重的思想值得借鉴,可用于其他多模态融合问题,提高模型的鲁棒性。
这篇关于WWW24因果论文(2/8) |多模因果结构学习与根因分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





