本文主要是介绍解锁数据的力量:Navicat 17 新特性和亮点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
解锁数据的力量:Navicat 17 新特性和亮点
大家好,我是猫头虎。今天我要为大家介绍 Navicat 17 的新特性和亮点。Navicat 是一款专业的数据库管理工具,支持多种数据库类型,包括 MySQL、Oracle、SQL Server、PostgreSQL、MariaDB、Redis、MongoDB 和 SQLite。Navicat 17 包含的版本如下:Navicat Premium 17、Navicat 17 for MySQL、Navicat 17 for Oracle、Navicat 17 for SQL Server、Navicat 17 for PostgreSQL、Navicat 17 for MariaDB、Navicat 17 for Redis、Navicat 17 for MongoDB、Navicat 17 for SQLite、Navicat Data Modeler 4。它提供了直观的用户界面和丰富的功能,帮助用户轻松管理和操作数据库,提高工作效率。
🚀 解锁数据的力量 🚀
Navicat 17 焕新上市,为用户带来了许多令人兴奋的新功能和改进,下面我将为大家详细介绍这些新特性。
模型

快速建模,简化执行
在一个工作区中创建多个模型,使你可以在单个图表中说明不同的模型对象,简化了复杂系统的浏览和理解。另外,对函数/过程的支持允许你在模型阶段预定义过程和操作。

快速精确的设计
在一个快速响应和交互的环境中,使用各种图表样式设计你的图表。将相关元素分层排列,锁定或组合特定元素,对选定元素应用自动布局,以及重新布置连接。体验更快、更高效的复杂模型设计。
- 刷新图层方法
- 锁定/分组选项
- 自动布局升级
- 添加连接线
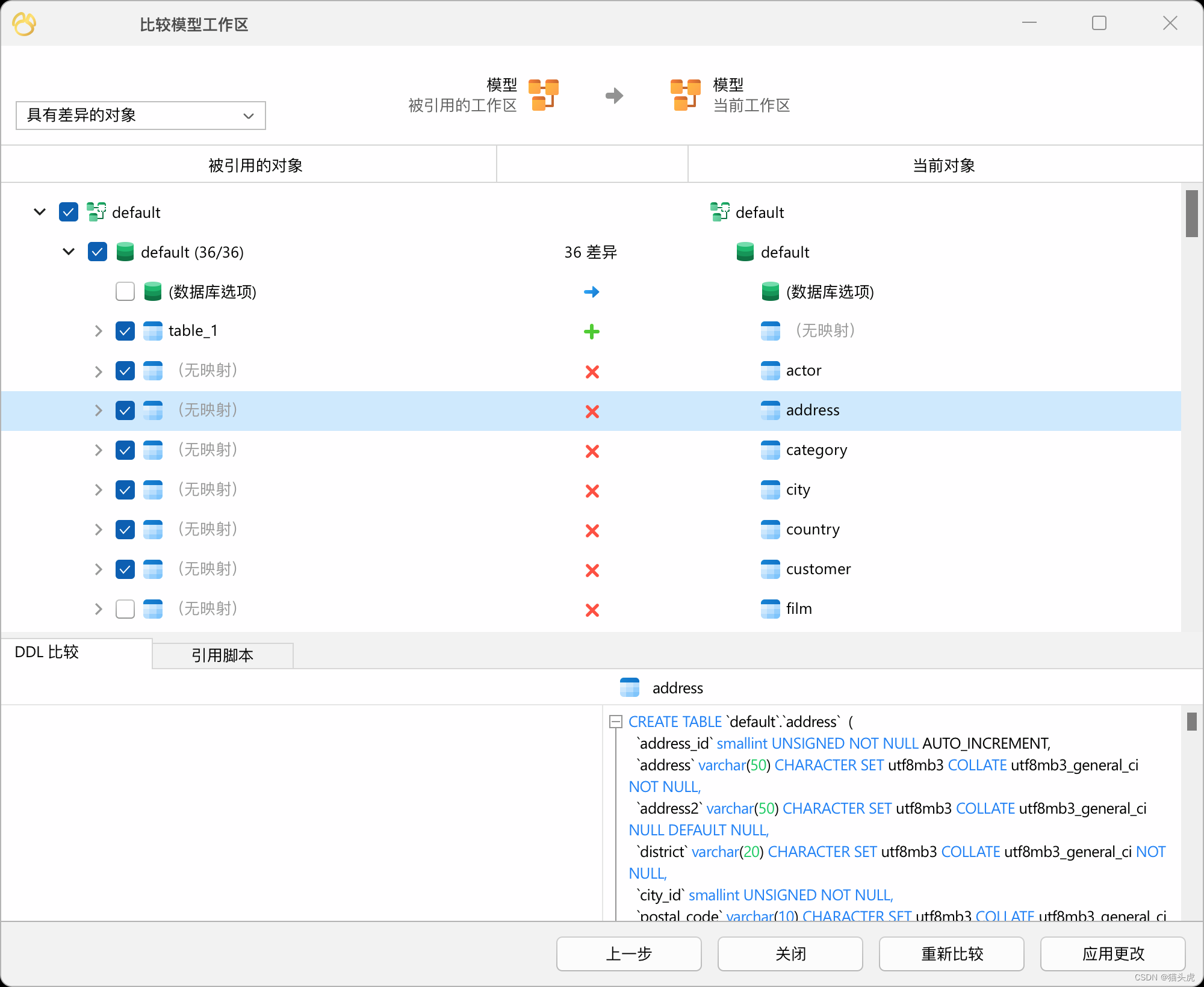
无缝同步
比较模型工作区并将数据库与模型同步,或者反向操作,自动地将其中一方的更改应用到另一方中。Navicat 确保数据库和模型之间的无缝集成,使它们保持最新且一致。
数据字典
定义和记录你的数据库
使用我们的数据字典新工具,为每个数据库元素创建极漂亮的文档。你可以从一系列预设计模板中选择,并根据你的偏好进行个性化设置。设置自动化流程以将文档导出为 PDF,并通过电子邮件与利益相关者共享。数据字典还可在模型工作区中使用。

数据分析
增强数据完整性
在数据查看器中集成数据分析工具,以便为你的数据查看提供一个全面视图。通过提供一系列可视化图表来展示分析结果,使你能够分析数据集中的数据类型、格式、分布以及统计属性。你可以与可视化图表进行交互,以便进一步探索数据,例如深入特定数据段、根据某些标准筛选数据,或突出显示感兴趣的数据点。
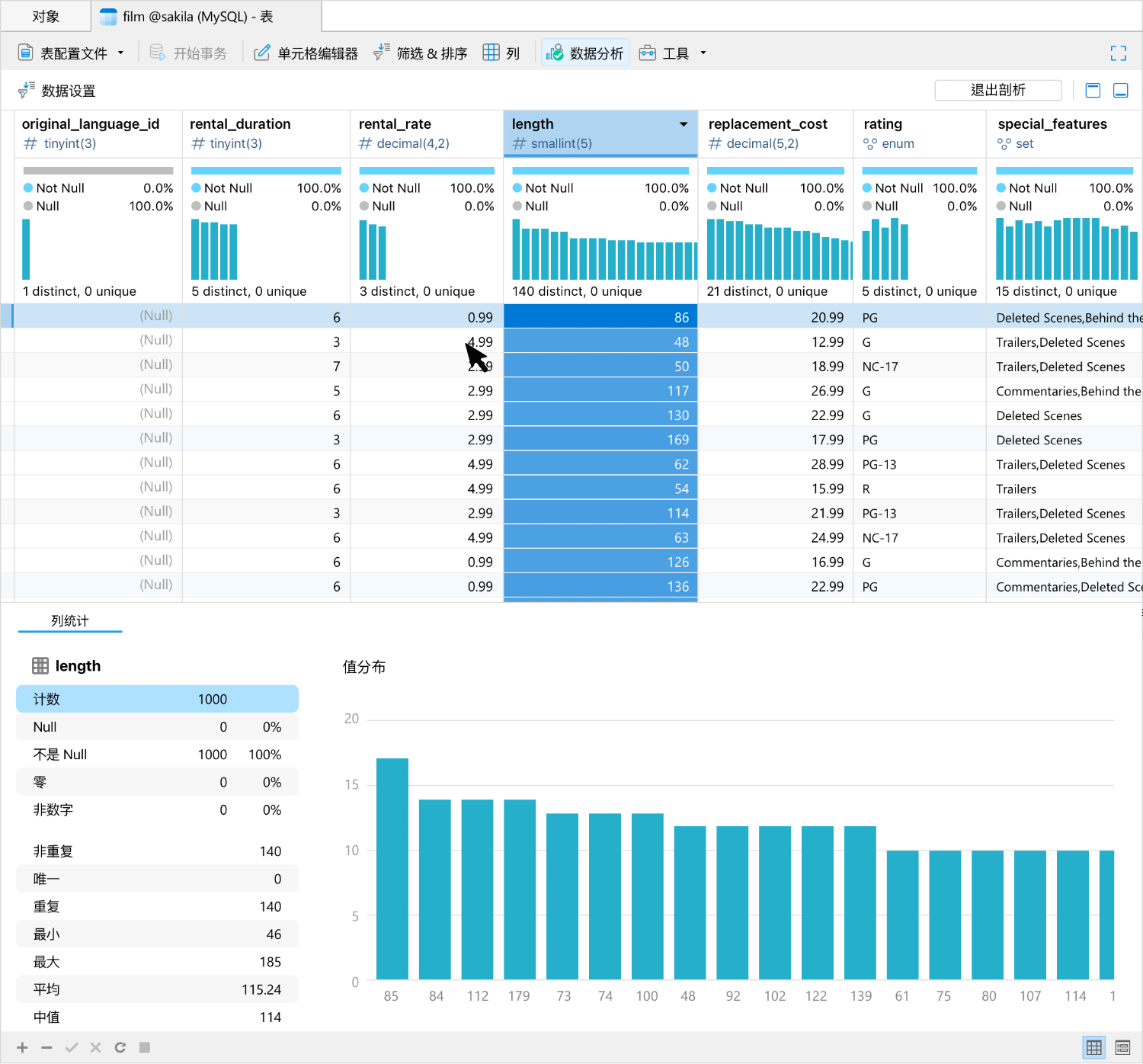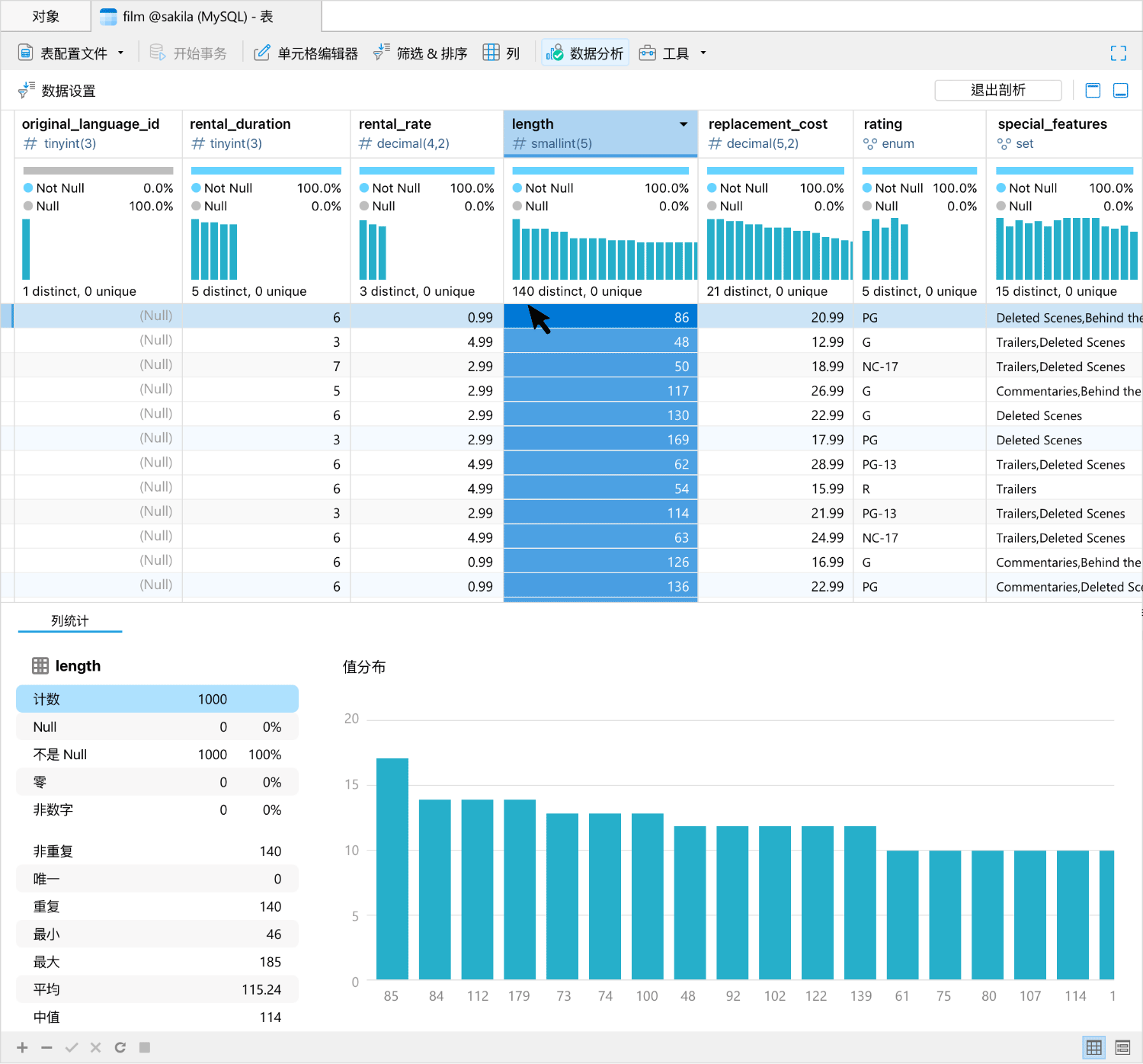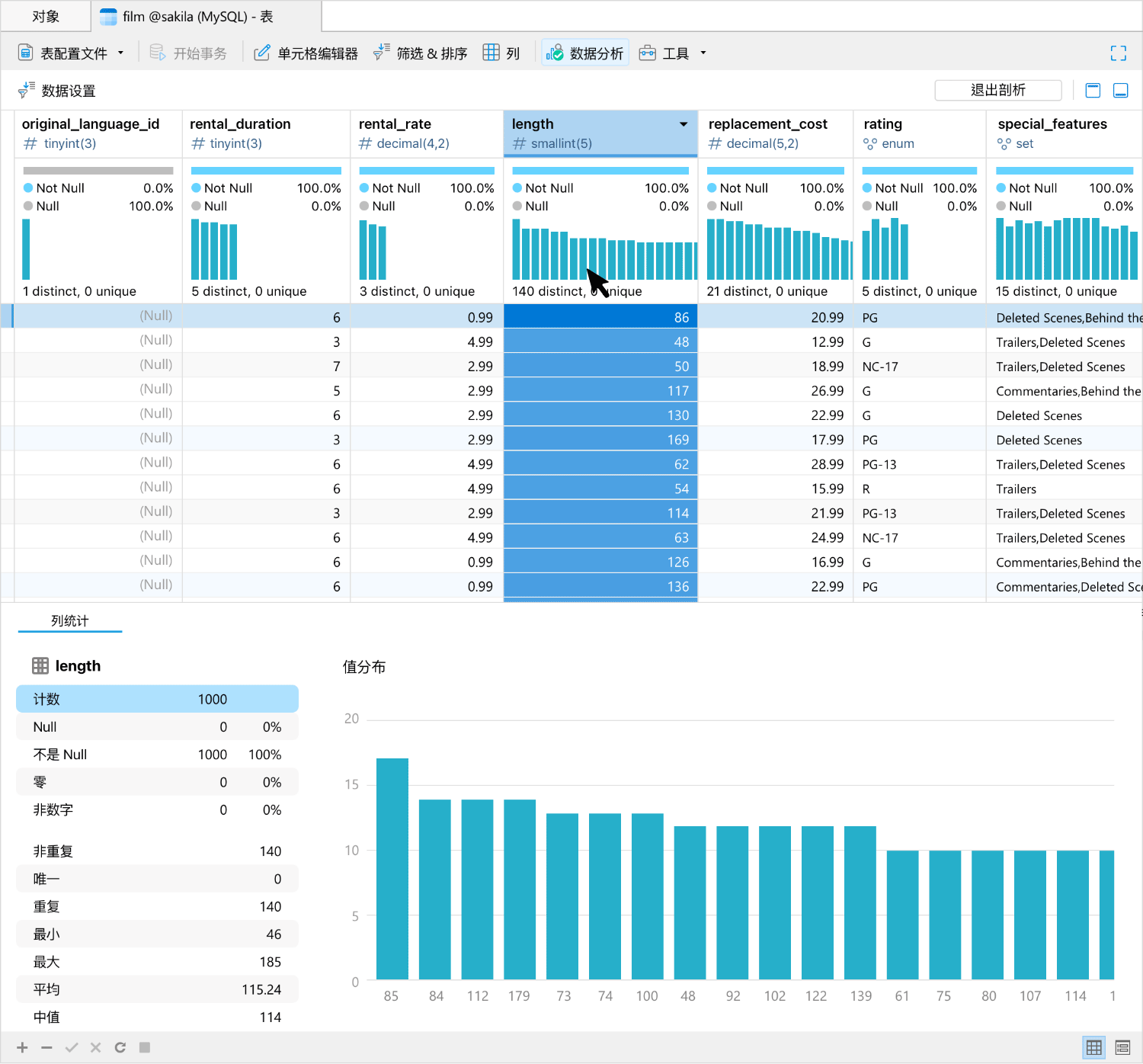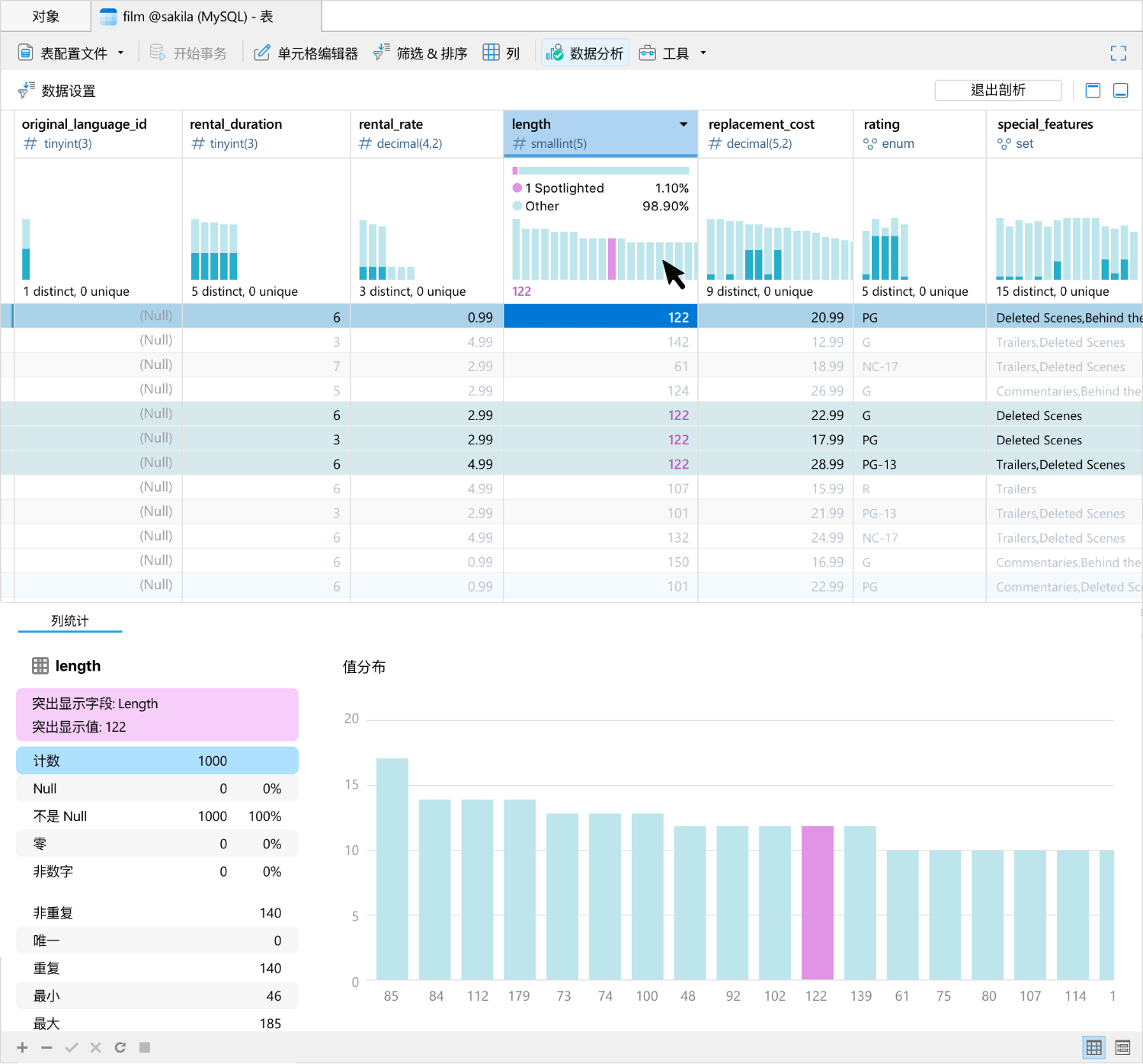
查询
关于查询,一目了然
Navicat 已经大大提升了查询解释功能。它支持各种格式,包括可视化、JSON、文本和统计计划的解释查询执行。通过图形化和高亮来表示那些高耗能或低效率的操作,Navicat 使你能够深入了解查询如何与数据库进行交互,这有助于识别需要优化或故障排除的区域,从而提高查询性能和整体数据库效率。
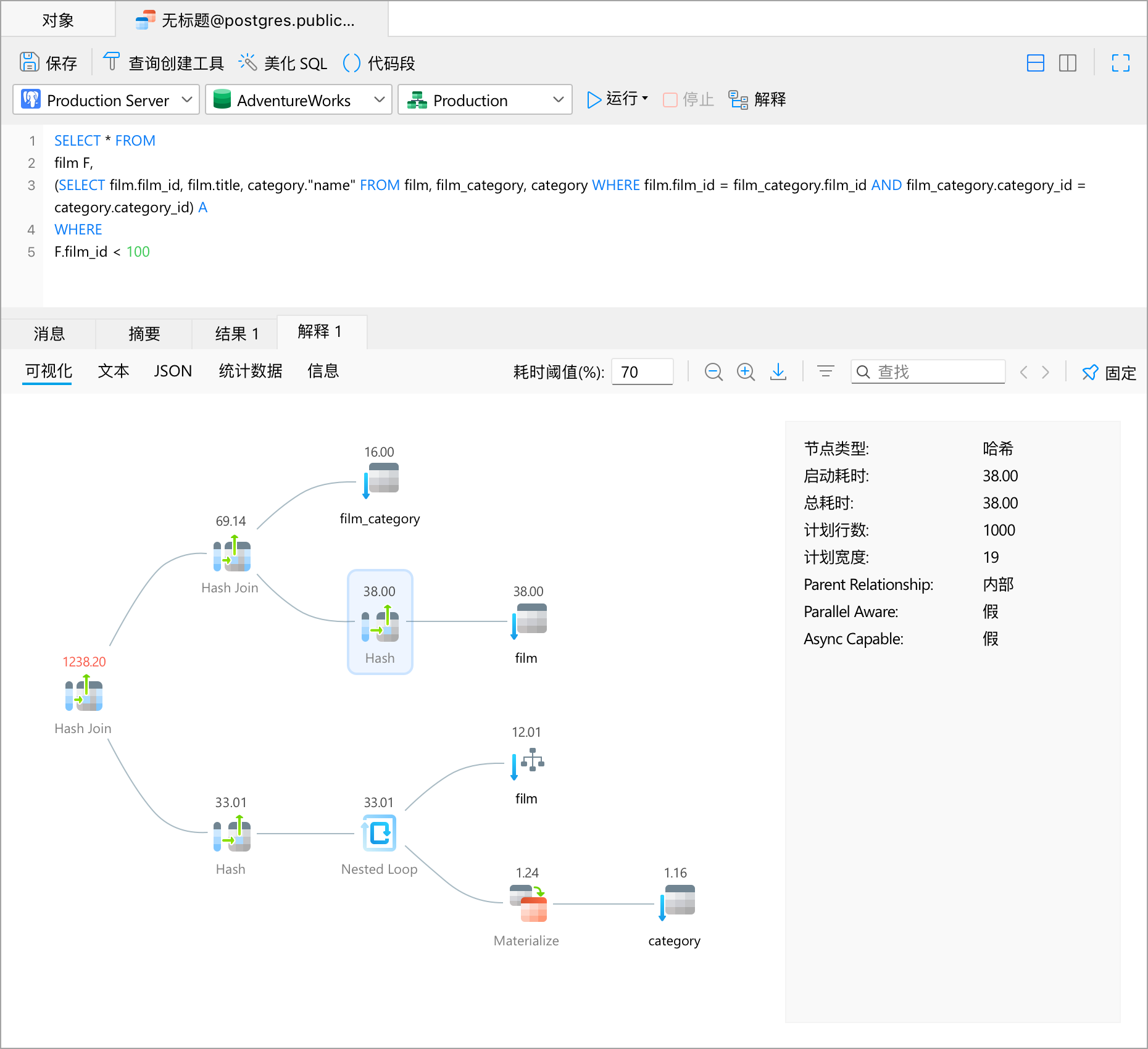
可靠地捕获和比较查询结果
通过固定查询结果,可以保留一组特定的结果以供将来参考。Navicat 在给定的时间点保留了一组特定的数据,以及其相应的 SQL 和运行时间。无论你是需要执行深入分析还是比较,固定查询结果的功能都能确保你拥有可靠且未更改的数据集。
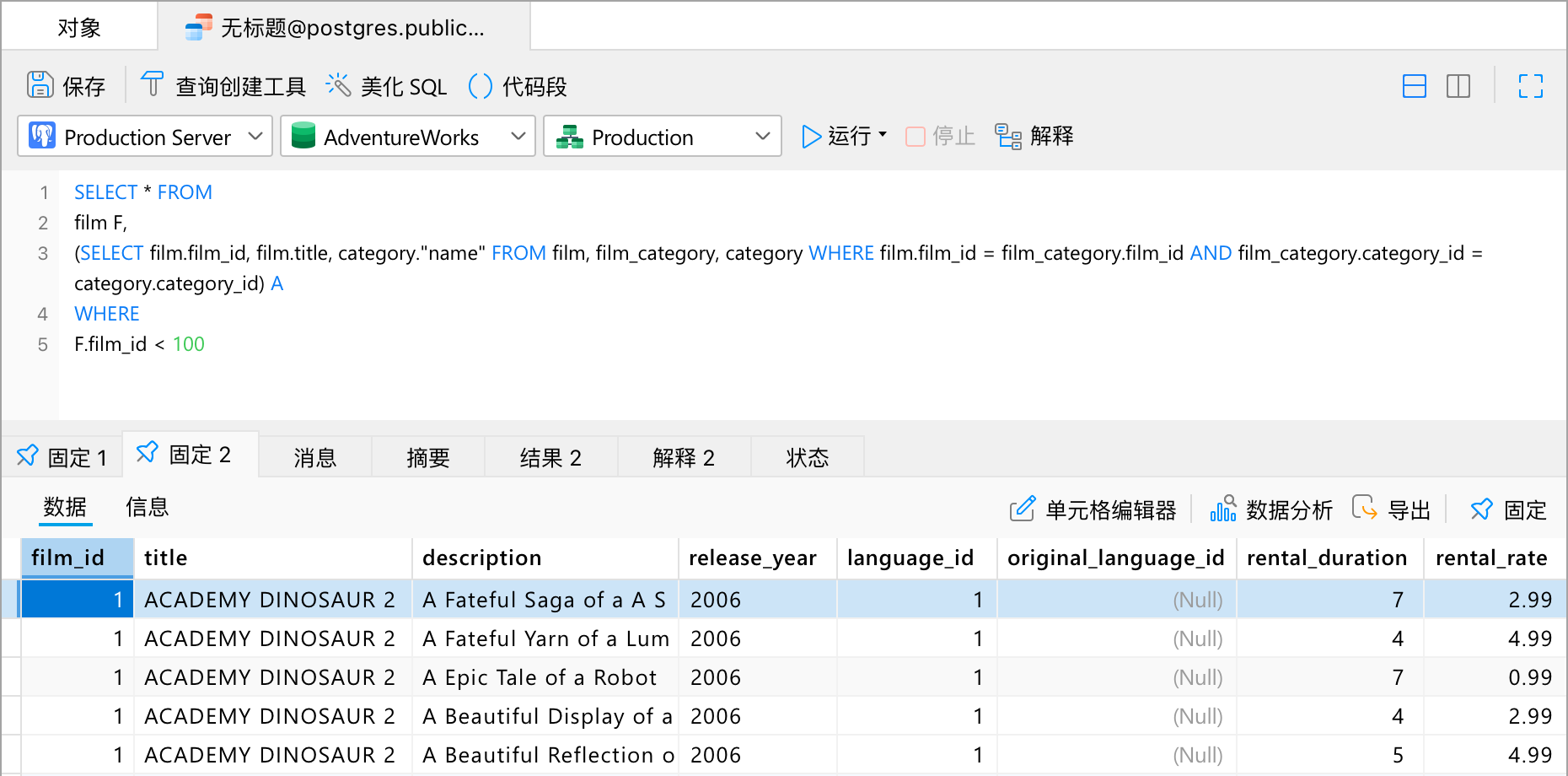
表配置文件
一次配置,轻松切换
配置和保存经常用到的表的筛选、排序顺序和列显示的不同组合。根据不同的用途,你可以保存多个配置并在它们之间轻松切换,而无需每次访问时都重新配置表。
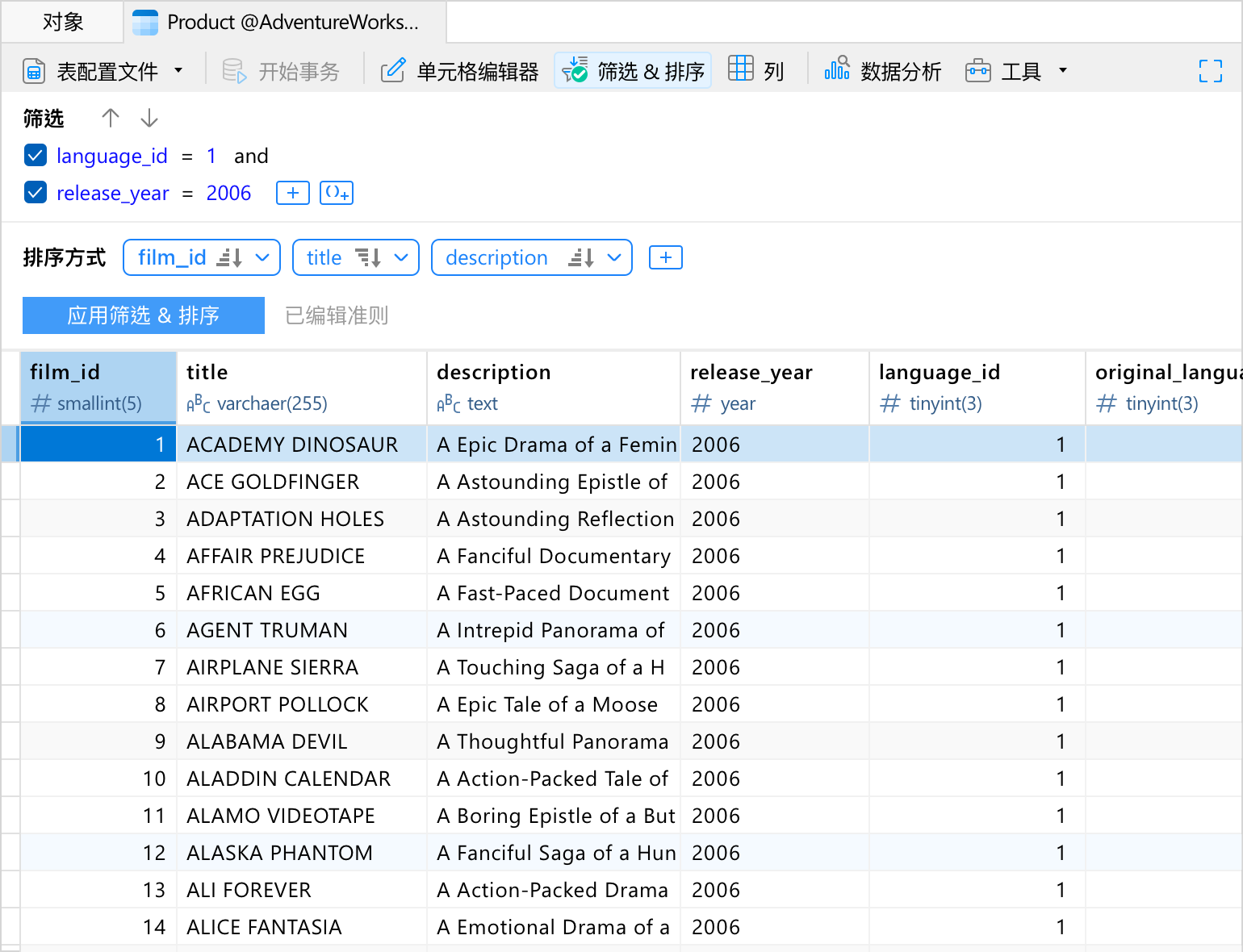
URI
直接访问,实现无缝协作
共享服务器对象 URI 可促进团队成员之间的协作。无论团队成员位于何处,Navicat 提供了一个快捷方式,可以轻松访问对象。单击 URI 可在 Navicat 中快速打开对象。这消除了手动导航来定位对象的需要,让每个人都可以专注于他们的任务,而不会出现不必要的复杂性。
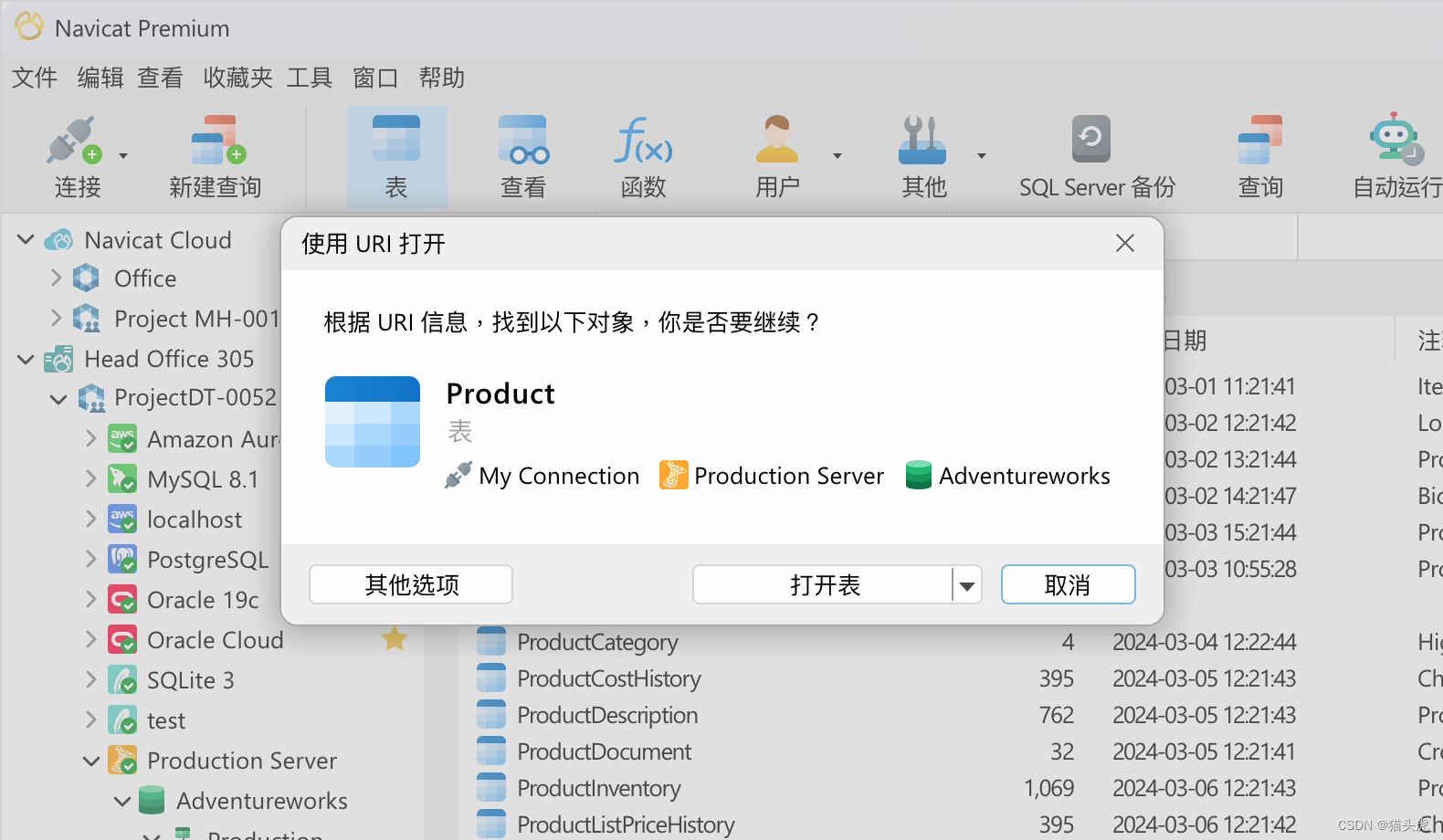
连接
直观的设置,高级的搜索功能
通过以用户为中心的界面建立连接,它为启动连接提供了一个简单的过程,即使对于那些技术专长有限的人来说也是如此。借助高级筛选和搜索功能,你可以快速准确地查找特定的服务器类型。合并管理多个连接配置文件,并创建基于 URI 的连接,进一步优化了效率和用户友好性。
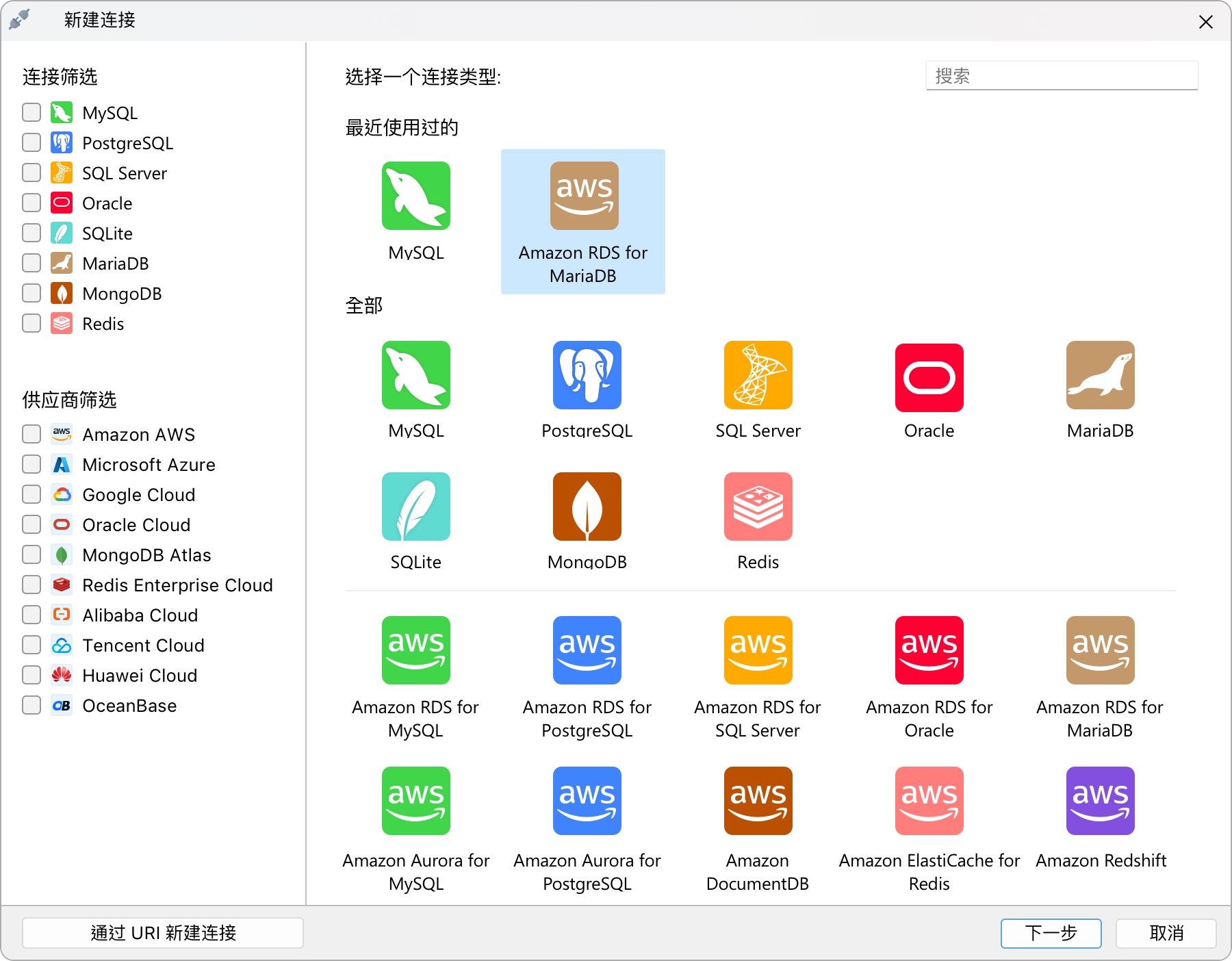
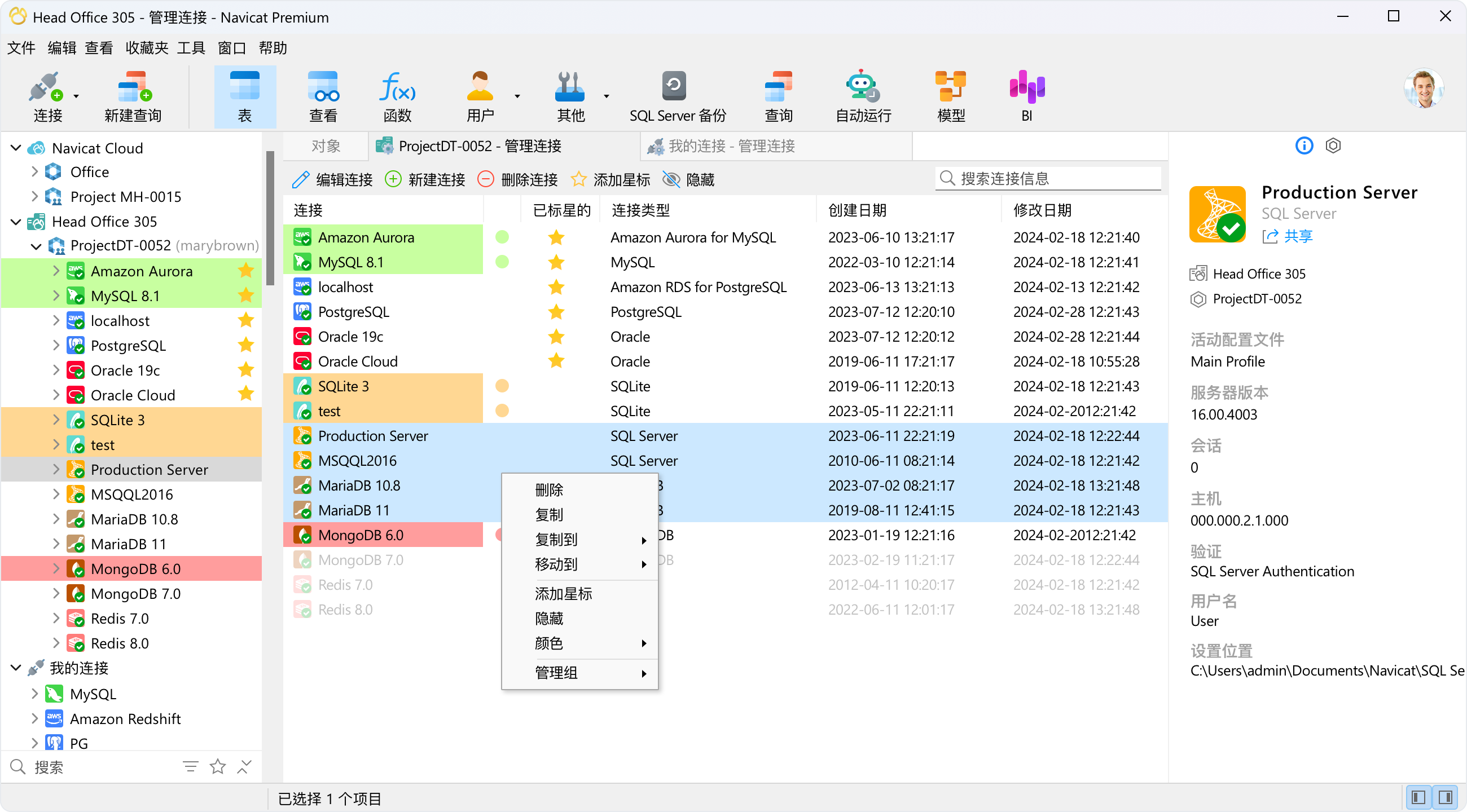
一个接口中的多连接属性
“管理连接”提供了一种从集中位置同时管理多个连接属性的全新方法,允许你执行高效的批处理操作。你可以根据优先级将连接设置星标、根据其重要性分配颜色或对它们进行分组来个性化你的连接管理。使用“管理连接”,一切都会整齐有序且易于访问,从而节省了查找特定连接的时间和精力。
BI
探索相互关联的见解
现在,仪表板上具有相同数据源的所有图表可以相互连接。当你在其中一个图表上选择数据点时,链接到同一数据源的同一仪表板页面上的所有其他图表将立即更新,以反映你的选择。这种实时协调,使你能够观察数据不同可视化表示形式的模式、相关性和趋势。

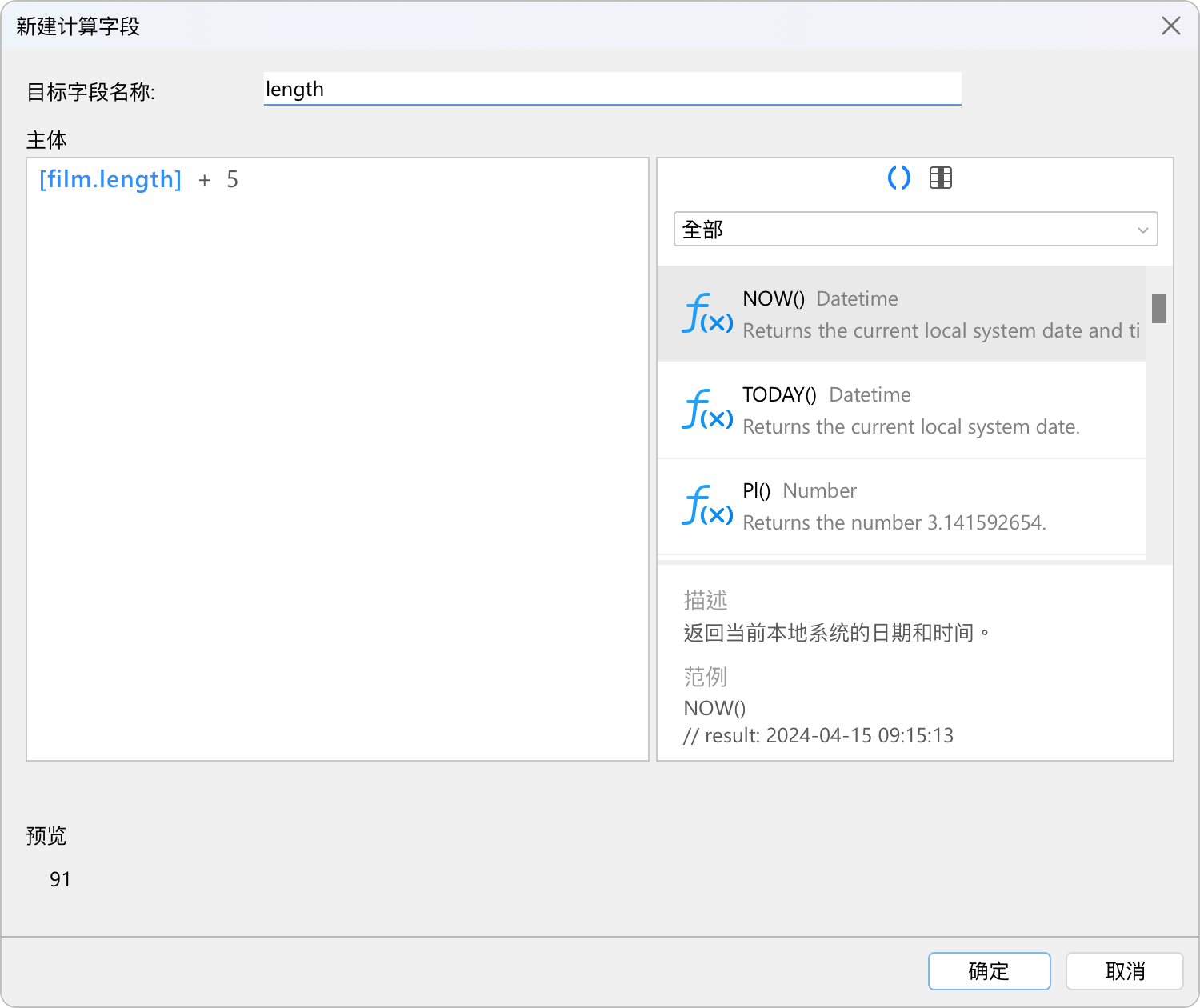
使用直观的自定义表达式轻松扩展和自定义数据
无需编写复杂的查询或记住复杂的公式。Navicat 提供了一种直观的方法,可以使用特定的公式或表达式来派生新数据点或转换现有数据。你可以轻松创建自定义表达式并执行高级计算,而无需手动处理数据。
连接到 MongoDB 和 Snowflake 以增强数据分析能力
通过整合 MongoDB 和 Snowflake,我们的 BI 功能已将数据可视化和分析提升到新的水平。无论你是使用 MongoDB 的 NoSQL 数据库还是 Snowflake 的云数据平台,我们的工具都能让你创建极漂亮且内容丰富的图表。

MongoDB 的聚合管道设计
通过清晰且响应迅速的 UI 逐步构建聚合管道。你可以使用拖放功能来添加和重新排列阶段,以实现所需的数据流。通过此可视化界面,你可以跟踪每个阶段的数据流。它提供管道不同阶段的即时反馈和结果预览。Navicat 使你能够验证数据转换的准确性和正确性,并对管道微调以获得最佳性能。

专注模式
专注模式是 Navicat 中的一个
新功能。它提供了一个无干扰的环境,让你专注于与数据库相关的任务。无论你是查询数据、设计数据库结构、查看数据库数据,还是分析数据库性能,你都可以最大限度地利用工作空间并专注于特定任务,而不会被无关信息所干扰。
Redis 哨兵
Navicat 为管理和监控独立 Redis、Redis 集群和 Redis 哨兵部署提供全面支持。你可以通过 Navicat 的各种功能与 Redis 进行交互,这些功能为连接 Redis、执行命令和处理存储在 Redis 中的数据提供了便捷界面。

Linux ARM 版本
Navicat 为 Linux 平台提供 ARM 支持。你可以受益于 Linux 提供的稳定性、可扩展性和安全性功能,从而让你在 ARM Linux 系统上无缝开发和部署数据库。

结语
希望通过这篇文章,大家能更好地了解 Navicat 17 的新特性和亮点。如果你有任何问题或想了解更多细节,欢迎在评论区留言。如果你是学生,为了完成毕业论文,请扫描文末名片,博主免费辅助你学会软件入门。
希望这篇文章能为你提供清晰、详细的 Navicat 17 下载与安装指导。如果你喜欢这篇文章,请点赞和分享,也欢迎你关注我的其他技术分享和教程。
这篇关于解锁数据的力量:Navicat 17 新特性和亮点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




