本文主要是介绍11 Goroutine-并发与并行、阻塞与非阻塞,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
并发
顺序执行:按照事先计划好的顺序,执行完一个操作后,再执行下一个操作。
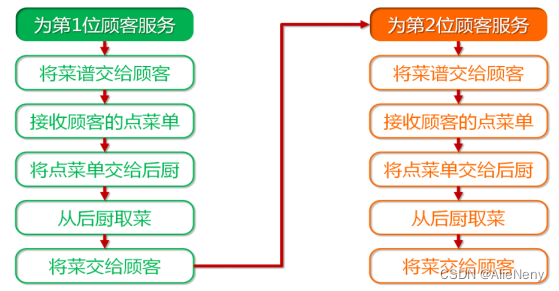
顺序执行效率不高的原因:
- 每个操作由多个步骤组成,每个步骤所需要的时间长短不一,有些步骤可能相当耗时。
- 顾客点菜需要时间,后厨做菜也需要时间,可否利用这些时间为更多顾客提供服务呢。
优化目标:减少不必要的闲置和等待,最大化处理机时间,提高工作效率
- 当一个操作执行到某个相当耗时的步骤时,转而执行其它操作中相对不太耗时的步骤。
- 待这些非耗时步骤完成后,之前那个耗时的步骤也完成了,再继续回到前一个操作中。
并发执行:没有固定的执行顺序,不等一个操作执行完,即开始下一个操作 。

并发与并行
并发:一个行为主体同时执行多个操作。
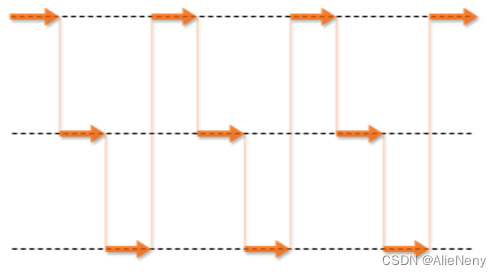
并行:多个行为主体同时执行多个操作。
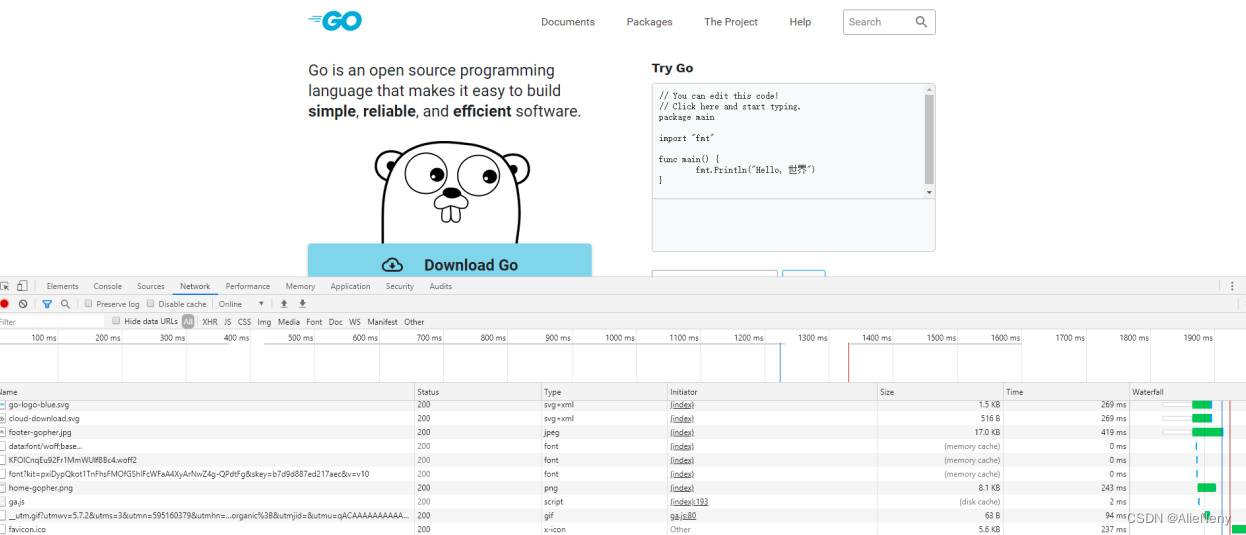
浏览器中的并发
启用浏览器开发人员工具,打开任意可访问页面,可以看到浏览器并不是依次发出每一个请求,而是同时发出很多请求,以尽快渲染页面的每个组成部分。这样做的好处是页面的整体加载速度在用户看来非常之快。
阻塞与非阻塞
在实际编程中,有些函数的执行速度很快,对于调用者而言几乎瞬间就返回了,这样的函数称为非阻塞函数。
但另一些函数的执行速度则可能非常缓慢,在调用者看来从调用到返回需要经历非常漫长的等待,甚至可能是永久的等待,这样的函数称为阻塞函数。
- 在顺序模式中,阻塞的操作会导致其后的操作长期或永远得不到执行,降低程序的性能。
- 在并发模式中,阻塞的操作会和其它操作分属于不同的执行过程,快不必等慢,高性能。
// 顺序执行
// 在顺序模式中,阻塞的操作过程会导致其后的操作永远或长期得不到执行,降低程序的性能
package main
import ("fmt""time"
)
func proc(ch rune, ms time.Duration) {for { // 死循环,模拟阻塞fmt.Printf("%c", ch)time.Sleep(ms * time.Millisecond)}
}
func main() {proc('-', 100)proc('+', 500)
}
// 打印输出:
// -------------------------通过goroutine并发处理
Go语言通过Goroutine处理并发,为了使某个函数在独立的"线程"中执行,只需在调用该函数的时候使用关键字go。
- go proc('-', 100)
将任何阻塞函数放在关键字go的后面执行:
- 立即启动一个独立的"子线程",并在该"子线程"中执行阻塞函数中的代码。
- 与此同时"父线程"从go中立即返回,并不等待阻塞函数返回,即"子线程"结束。
- "父线程"在"子线程"执行阻塞函数的同时,执行该语句下面的操作。
- go下面的操作和go后面的函数分别运行在父子两个独立"线程"中。
- 阻塞函数执行完毕返回,"子线程"结束。
// 并发执行
// 在并发模式中,阻塞的操作过程运行于独立的"线程"之中,不会影响其它操作的执行,提高了程序的性能
package main
import ("fmt""time"
)
func proc(ch rune, ms time.Duration) {for {fmt.Printf("%c", ch)time.Sleep(ms * time.Millisecond)}
}
func main() {go proc('-', 100) // 每100ms,打印-proc('+', 500) // 每500ms,打印+
}
// 打印输出:
// +-----+-----+-----+-----+ Goroutine与线程
Goroutine常被称作轻量级线程或逻辑线程,它和真正的线程还是有区别的。
| 线程 | Goroutine | |
| 调度 开销 | 线程由操作系统内核调度,每隔几毫秒,会有一个硬件时钟中断发送到CPU,CPU会调用一个调度器内核函数。该函数暂停当前正在运行的线程,把它的寄存器信息保存到内存中,查看线程列表并决定接下来运行哪一个线程,再从内存中恢复此线程的寄存器信息并执行之。这种线程调度需要一个完整的上下文切换,即保存一个线程的状态到内存,再从内存恢复另一个线程的状态,同时还要不断更新调度器的数据结构。某种意义上讲,这种操作还是相当耗时的。 | Go语言程序运行时自带一个调度器,这个调度器使用一个称为一个M:N的调度技术,即将M个Goroutine调度到N个线程中,Go的调度器不由硬件时钟定期触发,而由特定的Go语言结构触发,也不需要在用户态和内核态之间来回切换,所以调度一个Goroutine比调度一个线程的开销要小得多。 |
| 栈空间 | 每个线程都有一个固定大小的栈内存,通常是2M字节,栈内存用于保存函数的参数、局部变量和返回地址。 | Goroutine的栈内存是动态的,开始只有2K字节,而后随着程序的运行,再根据实际需要增大或缩小,最大可以到1G字节。 |
| 线程 标识 | 在大部分支持线程的操作系统中,每个线程都有一个唯一标识,通常是一个整数或者结构体,通过该标识可以为每个线程创建独立的全局存储空间,谓之线程局部存储。 | Goroutine没有提供可被程序员访问的唯一标识,它是一种纯函数的理念。Go语言认为线程局部存储的滥用会导致一种不健康的超距作用,即函数的行为不仅取决于它的参数,还与执行它的线程有关。 |
这篇关于11 Goroutine-并发与并行、阻塞与非阻塞的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




