本文主要是介绍高效的大型语言模型适应方法:提升基础性的解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

谷歌的AI搜索工具建议用户“吃石头”对健康有益,这一搞笑的回答引发了众人哗然。为了提高LLMs(大型语言模型)的可靠性,我们推出了AGREE,一种基于学习的框架,旨在使LLMs能够在回答中提供准确的引用,从而提高用户的信任度。
近年来,LLMs在多跳推理、生成计划和使用工具和API等各种能力上展示了显著进步,显示出在许多下游应用中的巨大潜力。然而,在现实世界中部署时,LLMs的可靠性有时会因“幻觉”问题而受损,即模型生成了看似合理但实际上并不准确的信息。当LLMs被要求回答涉及广泛世界知识的开放性问题时,“幻觉”问题更为常见,这在需要高度准确性的领域,如新闻报道和教育内容中尤其具有风险。
为了应对LLMs的“幻觉”问题,基础性研究致力于追溯其声明到可靠的来源。这样的系统不仅能提供连贯且有用的回答,还能通过引用外部知识来支持其声明。
在我们即将在NAACL 2024上展示的论文“提升基础性的大型语言模型适应方法”中,我们介绍了一个新的LLM基础性框架,称为AGREE(Adaptation for GRounding EnhancEment),它使LLMs能够自我基础化其回答中的声明,并提供精确的引用,增强用户信任并扩展其潜在应用。在五个数据集上的全面实验表明,AGREE比以前的基于提示或事后引用的方法在基础性方面有显著提升,通常能实现超过30%的相对改进。
改进基础性的整体方法
以前改善基础性的研究主要遵循两种显著的范式。一种是使用额外的自然语言推理(NLI)模型事后添加引用,这种方法严重依赖于LLM嵌入中的知识,无法很好地扩展到超出该范围的事实。另一种常见的基础性方法是利用LLMs的指令跟随和上下文学习能力。这种方法要求LLMs仅通过少量演示提示来学习基础性,实际效果并不理想。
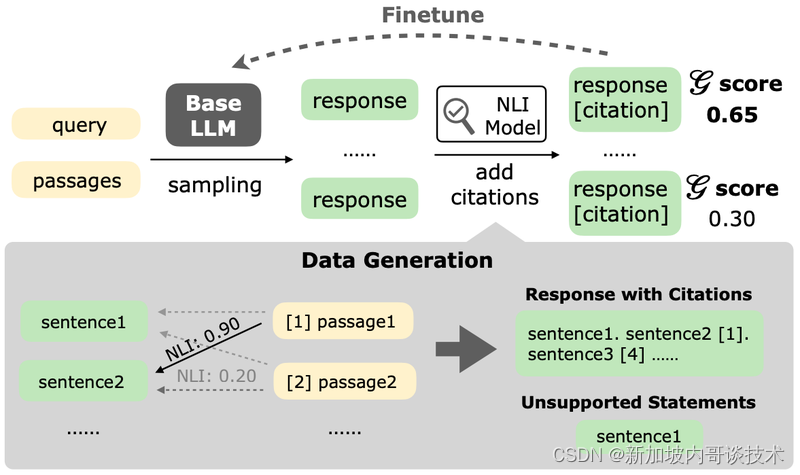
我们的新框架AGREE采用整体方法,结合基于学习的适应和测试时适应(TTA),以改善LLMs的基础性和引用生成。不同于以前的基于提示的方法,AGREE对LLMs进行微调,使其能够自我基础化其回答中的声明并提供准确的引用。这种在预训练LLMs之上进行的微调需要良好的基础性回答(带有引用),为此我们引入了一种方法,可以从未标记的查询中自动构建这样的数据。经过微调的LLMs的自我基础化能力进一步赋予了它们TTA能力,能够迭代地改进其回答。
微调LLMs以实现自我基础化
在训练期间,AGREE从未标记的查询中收集合成数据,然后使用这些数据微调基础LLM,使其能够自我基础化其声明。针对一个未标记的查询,我们首先使用检索模型从可靠来源(如维基百科)检索相关段落。然后,我们向基础LLM呈现检索到的段落并采样一组初始回答(不带引用)。接下来,我们使用一个NLI模型(在我们的例子中,是Google TrueNLI模型的变体),来判断一个声明是否由段落支持,帮助为初始回答添加引用。对于初始回答中的每个句子,我们使用NLI模型找到可以支持该句子的段落,并相应地添加引用。对于没有支持段落的句子,我们不会添加引用。
测试时适应
在测试时,AGREE引入了一种迭代推理策略,使LLM能够根据其自我生成的引用主动寻找更多信息。针对一个查询,我们首先使用检索模型获取初始段落集。然后,我们迭代执行以下步骤:1)在每次迭代中,适应后的LLM生成包含对段落集引用的回答,并找到没有引用的任何不支持声明。2)接着,我们根据引用信息主动向LLM提供更多信息——如果存在不支持声明,我们会使用这些声明检索更多可靠来源的信息,否则,我们会包括使用查询检索到的更多未见段落,以获取更完整的信息。

实验
我们进行了全面的实验,展示AGREE在有无TTA情况下的有效性。我们在五个数据集上对其进行了评估,包括两个域内数据集(NQ和StrategyQA)和三个域外数据集(ASQA、QAMPARI和一个内部QA数据集“Enterprise”)以测试我们框架的泛化能力。我们将AGREE应用于适应两个LLMs,并将其与一个竞争性的基于提示的基线(ICLCite)和一个事后引用的基线(PostCite)进行比较。

主要实验结果
实验结果表明AGREE在文本语料库中生成的回答具有更好的基础性(通过引用召回率衡量),并为其回答提供了准确的引用(通过引用精确度衡量)。它在各个数据集上都显著优于所选择的基线。
- 微调对于优越的基础性非常有效。
- 改进可以泛化。
- TTA提高了基础性和回答正确性。
AGREE不仅在域内数据集上表现出色,在域外数据集上的零样本设定下也能有效泛化,这表明我们的框架具有显著的泛化优势。
这篇关于高效的大型语言模型适应方法:提升基础性的解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





