本文主要是介绍【学习心得】回归任务的评估指标决定系数R^2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、决定系数是什么?
scikit-learn库在进行回归任务的时候,进行模型评估时的score()方法,默认采取的是计算的是决定系数(Coefficient of Determination),通常表示为得分。这个值衡量了模型预测值与实际观测值之间的拟合优度。
它表示模型的因变量y的变异值占变异量的比例,换句话说就是模型预测的结果能够解释因变量变化的百分比。
- ( SSE ) 是误差平方和(Sum of Squares due to Error),即模型预测值
与实际值
之间的差异的平方和。
- ( SST ) 是总平方和(Total Sum of Squares),是因变量总体变异性的平方和,即实际值
之差的平方和。
二、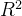 指标的怎么评估模型好坏?
指标的怎么评估模型好坏?
表示模型解释的方差比例,即因变量的总方差中由模型解释的那一部分。
例如,如果
,这意味着80%的因变量变异可以由模型中的自变量解释,剩余的20%则归因于未被模型捕获的其他因素或随机噪声。
因此当:
三、决定系数的局限性
不适合评估模型的预测误差分布,比如它不关心误差的正态性或同方差性。对于非线性模型,
可能不是最佳的评估指标,因为即使模型不完美,也可能得到较高的
值。
这篇关于【学习心得】回归任务的评估指标决定系数R^2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





