本文主要是介绍【论文阅读】Prompt Fuzzing for Fuzz Driver Generation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 摘要
- 一、介绍
- 二、设计
- 2.1、总览
- 2.2、指导程序生成
- 2.3、错误程序净化
- 2.3.1、执行过程净化
- 2.3.2、模糊净化
- 2.3.3、覆盖净化
- 2.4、覆盖引导的突变
- 2.4.1、功率调度
- 2.4.2、变异策略
- 2.5、约束Fuzzer融合
- 2.5.1、论据约束推理
- 2.5.1、模糊驱动融合
- 三、评估
- 3.1、与Hopper和OSS-Fuzz对比
- 3.2、缺陷检测的有效性
- 3.3、PromptFuzz组件的有效性
- 3.3.1、错误程序净化
- 3.3.2、论据约束推理
- 3.3.3、覆盖引导突变
- 四、有效性威胁
- 五、总结
摘要
编写高质量的模糊驱动程序是非常耗时的,并且需要对函数库有深刻的理解。然而,当前最先进的模糊驱动自动生成技术的性能还有许多需要改进的地方。从用户代码中学习的模糊驱动程序可以到达深层状态,但受限于它们的外部输入。另一方面,解释性模糊测试可以探索大多数API,但需要在广阔的搜索空间中进行大量的尝试。
本文提出了覆盖率引导的模糊器PromptFuzz,用于提示模糊,通过迭代生成模糊驱动来探索未发现的库代码。为了探索模糊驱动在提示模糊过程中的API使用,本文提出了几个关键技术:指导性程序生成、错误程序净化、覆盖率引导的提示变异和约束模糊器融合。本文实现了PromptFuzz,并在14个真实存在的库上评估了其有效性,将其与OSS - Fuzz和最先进的模糊驱动生成解决方案(即Hopper)进行了比较。
实验结果表明,PromptFuzz产生的模糊驱动具有更高的分支覆盖率,是OSS - Fuzz的1.61倍,是Hopper的1.67倍。此外,PromptFuzz生成的模糊驱动程序成功检测出44次崩溃中的33次真正的bug,这些bug以前是未知的,其中27次已经得到了各自社区的确认。
一、介绍
目前,模糊测试在保证软件安全性和稳定性方面发挥着至关重要的作用。其中一个例子是OSS - Fuzz,它为开源软件部署了最先进的模糊测试。截至2023年2月,OSS - Fuzz已经在850个项目中识别和解决了超过8900个漏洞和28000个bug。虽然灰盒模糊测试在识别bug方面也取得了成功,但OSS - Fuzz所取得的令人印象深刻的成果在很大程度上可以归功于各个贡献者在整合新项目方面付出的巨大努力。在集成项目进行模糊测试时,开发人员必须选择合适的模糊器并编写高质量的模糊驱动程序,模糊驱动是必不可少的,因为它们用于解析来自模糊测试的输入并调用被测软件中的代码。然而,编写高质量的模糊驱动程序是一项具有挑战性的任务,既耗时又需要对库有深入的理解。因此,手工编写的模糊驱动程序只能覆盖软件使用的一小部分,无法通过模糊测试对代码进行充分的测试。
模糊驱动程序自动生成技术不需要人工编写模糊驱动程序,而是从已有代码或动态反馈中学习库API的使用方法。FUDGE,FuzzGen和Utility静态地从源代码中提取API使用代码,而APICraft和WINNIE动态地从已有进程的执行轨迹中记录API调用序列。然而,该方法的效率受到消费者代码的限制,无法发掘消费者代码未覆盖的潜在有效用途。Hopper将库模糊测试问题转化为解释器模糊测试问题,从API调用的动态反馈中学习有效的API使用情况。虽然它可以覆盖大部分的API函数,但是可以找到有用的API调用序列。虽然它可以覆盖大多数API函数,但是在庞大的搜索空间中,找到到达深度状态的有用API调用序列需要无数次的尝试。
大语言模型在产生与用户意图一致的代码方面表现出优异的性能。尽管现有的工作已经尝试使用各种大语言模型来生成模糊驱动程序,但它们生成模糊驱动程序的指令仅限于特定的场景。生成的模糊驱动程序仍然存在API使用多样性的问题,往往无法覆盖很少使用的代码或深层状态。
为了解决上述挑战,本文引入了覆盖率引导的模糊测试器PromptFuzz,它通过迭代地生成模糊驱动来探索未发现的库代码。PromptFuzz包括一个基于LLM的程序生成器和一个基于运行时的程序错误预言器。PromptFuzz的核心思想很简单:通过覆盖指导指导LLM生成所需的模糊驱动,并利用程序错误预言保证其有效性。
二、设计
2.1、总览
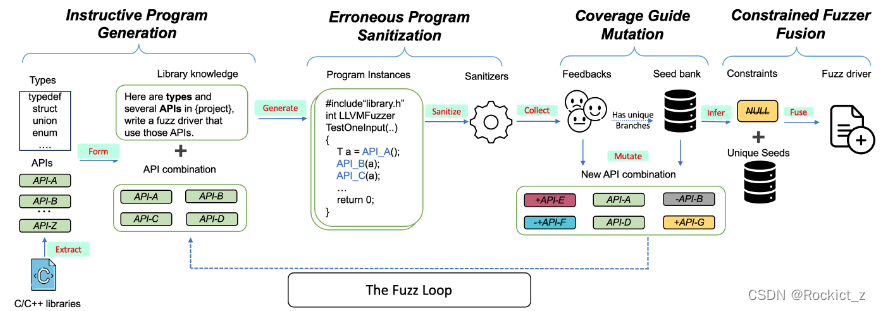
PromptFuzz侧重于对LLM的提示进行变异,以产生覆盖更广泛的库API使用范围的程序。PromptFuzz的工作流程如图所示。
最初,PromptFuzz从库头中提取函数签名和类型定义。然后,这些提取的细节被用于构造LLM提示,指导LLM生成使用指定API组合的程序。然后执行生成的程序,并根据其运行时行为进行净化。
在这个净化过程中,代码覆盖率也被收集。通过净化的程序存储在种子库中,而触发独特分支的程序被标记为独特种子。种子库中程序的代码覆盖率起到反馈、指导的作用。这种反馈有助于PromptFuzz将提示与更有可能探索新代码路径的API组合在一起。这个迭代过程一直持续到没有新分支被发现或者查询预算耗尽为止。
在最后阶段,PromptFuzz推断种子程序中对库API施加的约束。为了增强这些种子程序的模糊能力,PromptFuzz将唯一种子中具有固定值的参数转换为可以接受模糊测试中随机字节的参数。
2.2、指导程序生成
PromptFuzz选择了ChatGPT和GPT-4等模型,其构造了LLM提示,从而专注于生成库API的特定组合。为编写多样化的程序生成提示,PromptFuzz包含两个关键组件:任务和库上下文。
- 任务组件:指定了LLM应该执行的预定程序的详细信息,它涉及到从库中应该使用哪些API函数,这些API函数应该包含在一个LLVMFuzzerTestOneInput函数中。且采用零样本的思维链来增强LLMs的焦点。这包括API签名、自定义类型定义和库中包含的头信息。考虑到当前LLMs的上下文长度限制和语料库成本,PromptFuzz限制了库上下文中使用的API和自定义类型的数量。当库中API函数数量超过设定的限制(例如, 100)时,PromptFuzz采用随机选择策略,每次选择一个可管理的API函数数量,保证我们保持在限制范围内。对于自定义类型,PromptFuzz只选择所选API组合中API使用的类型,兼顾了相关性和效率。
- 通过整合对库所的上下文理解,LLMs产生的"幻觉"代码的发生可以显著减少。库规范在指导LLM生成符合库所要求的特定模式的代码方面起着至关重要的作用。一些库API可以从文件、文件流或文件描述符中读取输入,这可能会偏离模糊驱动程序的标准例程。通过将相关的库规范融入到LLMs的提示中,我们可以更容易地生成遵守这些规范的代码模式。
通过填充这些组件中的输入来生成这样的提示,PromptFuzz就会使用该提示查询LLM以生成程序。
2.3、错误程序净化
由于LLMs的训练数据偏差和不完善的代码合成能力,LLMs生成的代码容易出现错误和不安全,LLMs准确、正确地生成代码仍然是一个悬而未决的挑战。因此,LLMs生成的程序不适合作为模糊测试的直接目标。这些程序中错误的存在会使它们难以模糊化或者以错误的警告压倒模糊测试。根据模糊测试多年的实践,一个被认为是模糊测试的好目标的程序至少应该没有任何代码本身的错误。然而,确保LLMs一致地生成无错误的程序是具有挑战性的。为了解决这个问题,PromptFuzz使用了一种名为错误程序净化的技术。该过程对包含可识别代码错误的问题程序进行清理。

PromptFuzz对LLM生成的程序执行四步净化过程,如图所示。
- 首先,对C / C + +编译器识别出的包含语法错误的程序进行净化。
- 接下来,将剩余程序编译成具有多个运行时净化器的可执行文件。这些净化器捕获程序运行时的行为,并检测偏离正常程序行为的情况。
- 随后,PromptFuzz使用提供的语料库执行这些程序,并排除消毒器检测到偏差的任何程序。此外,PromptFuzz使用一个模糊测试过程来生成程序的输入,并保留触发独特行为的输入作为语料库的一部分。
- PromptFuzz按照模糊化过程,计算程序达到的整体代码覆盖率。只有满足代码覆盖准则的程序,表明库API函数的充分运用,才被认为通过了净化过程。
2.3.1、执行过程净化
潜在的Bug代码模式分散在整个生成的代码中,使其难以识别和处理。此外,检测这些程序中的代码逻辑错误仍然是一个公开的问题,进一步增加了净化过程的复杂性。
现有的方法,要么依赖于广泛的专家知识,要么存在精度问题。所以本文只排除包含可识别错误的程序,本文使用了ASan、UBSan和File-Sanitizer。使用这种净化方式的正确性基于两个假设。
- 首先,如果库API被正确使用,并在程序中提供适当的输入,它们不应违反净化器预定义的规则。
- 其次,如果存在对库API的误用,净化器应该能够捕获由误用导致的异常运行时行为。
基于这些假设,我们使用模糊处理过程中生成的语料来执行程序,以识别错误程序。净化器报告的任何违规行为都表明偏离了正确的库API使用,因此相关程序被净化。
2.3.2、模糊净化
最初,用于净化的程序输入可以是开发人员提供的种子输入,也可以是空的。这些种子输入通常由一组具有代表性的输入组成,并专门为某些模糊驱动程序设计,是模糊测试的良好起点。然而,由于生成的程序使用不同的库API来完成不同的任务,每个程序都可能需要自定义输入。因此,初始种子可能不适合这些程序的输入,从而限制了可以检查的运行时行为的覆盖范围。未被检查的程序代码的存在会造成执行净化过程中的假阴性威胁。
为了克服执行净化的覆盖范围限制,PromptFuzz进行了模糊处理,以发现更多独特的输入。这些独特的输入被称为模糊测试种子集。具体来说,对于通过了先前净化过程的程序,PromptFuzz使用灰盒模糊器对输入进行变异,同时监视程序的代码覆盖率。如果在每个时间间隔(例如, 60秒)内代码覆盖率增加,PromptFuzz继续进行模糊处理,直到达到时间预算(例如, 600秒)。随后,PromptFuzz将触发新代码覆盖率的输入添加到模糊测试语料中。这里的模糊测试过程的主要目的是生成每个程序所需的特定输入,而不是识别库代码中的bug。虽然短期的模糊测试可能不会瞬间产生所需的程序输入,但PromptFuzz的设计目的是在后续的模糊测试轮次中迭代地细化和演化模糊测试语料。这种持续的进化增强了随着时间产生合适的程序输入的可能性。
2.3.3、覆盖净化
经过前面的净化步骤后,PromptFuzz收集剩余程序的代码覆盖率,并找到程序的关键路径。关键路径是程序的控制流图中包含库API调用次数最多的路径。这些路径是特别感兴趣的,因为它们代表了我们要测试的API用法,而不是错误处理代码。在此分析之后,PromptFuzz对那些在关键路径上没有被执行的库API调用的程序进行净化。这保证了重要API的使用得到了充分的测试和验证。
基于覆盖的净化的好处是双重的。
-
首先,以往基于运行时的净化方法无法准确判断程序中不可达代码的正确性。尽管使用了一个模糊过程来演化模糊语料库,但这并不能保证所有程序都生成了合适的输入。通过使用基于覆盖的净化技术,我们可以有效地净化包含不可达代码的不可判定程序。虽然这种方法可能错误地排除了没有误用的程序,但它显著地减少了错误检测中的误报。
-
其次,某些库API的使用不会触发运行时净化器能够捕获的异常行为。覆盖净化可以排除包含那些静默库API误用的程序。
2.4、覆盖引导的突变
利用LLMs的代码综合能力,可以通过PromptFuzz编写的提示生成各种程序。然而,在提示中盲目地组装API组合将是低效的。由于代码覆盖率作为反馈,PromptFuzz采用了提示级别的功率调度和变异策略来生成有效的提示。
2.4.1、功率调度
PromptFuzz为待测库维护一组被访问的分支和调用图。在PromptFuzz的模糊过程的每一次迭代中,它将新发现的唯一分支合并到集合中,然后计算每个API的分支覆盖率。在计算API分支覆盖率时,不仅考虑了函数体内部的分支,还考虑了任意递归调用方体内部的分支。对于任一API i,其新energy( i )计算如下所示:

式中:Seed ( i )为种子程序i的计数,prompt( i )为PromptFuzz提示中已选中的i的计数,E为调节i出现频率重要性的指数。对于运动较少的人,分配给APIs的能量较高。一个API的能量越高,表明该API在LLMs提示的API组合中被选中的可能性越高。
2.4.2、变异策略
PromptFuzz重点在于对提示中的API组合进行变异,以指导程序的生成。PromptFuzz对传统Fuzzing中常用的API组合执行以下变异操作:
- Insertion(C, A): 将API A 插入到组合 C 中.
- Replacement(C, A, B): 将组合C中的API A替换为API B。
- Crossover(C, S):将组合C和S进行组合,创建新的组合。
在API能量的指导下,PromptFuzz可以有效地调度变异来组装API的组合,以达到先前未被探索的代码。然而,仅仅根据API的探索程度而不考虑其潜在的相互关系来组合API,阻碍了LLMs生成探索复杂API关系的程序的能力。为了便于更有效的变异,PromptFuzz还收集了反映提示中使用的API组合有效性的统计量。具体来说,PromptFuzz从种子库中的每个程序的代码中收集以下统计数据:
- 密度(Density):表现出相互之间明确的数据依赖关系的库API调用的最大数量。
- 独特的分支(Unique branches):程序执行过程中触发的唯一分支数量。
PromptFuzz通过公式来量化程序的质量,关联API调用越多、分支发现越多的程序被赋予更高的质量。

在PromptFuzz模糊测试过程的每一次迭代中,PromptFuzz依次探索种子库并更新唯一种子的质量。PromptFuzz利用库API的能量和种子质量的反馈,应用算法1中的算法来选择新的API组合。如果当前迭代中没有足够的唯一种子,PromptFuzz进入预热阶段。该阶段通过选择具有高能量的API来随机组装API组合,以广泛地探索先前未被发现的库使用。在变异状态中,PromptFuzz选择在唯一种子的关键路径内依次调用的库API作为变异的枢轴组合。没有与其他API交互的API被删除。围绕这一支点的突变使得PromptFuzz可以深入考察错综复杂的库使用情况。在获得新的API组合后,它被用来构造下一次迭代程序生成的提示。
2.5、约束Fuzzer融合
在模糊循环停止后,PromptFuzz扩展了唯一种子的模糊能力,并将其融合为模糊驱动。
- 首先,PromptFuzz从种子库中存储的程序中推理出对库API施加的参数约束。
- 然后,PromptFuzz变换唯一种子的代码,以固定值替换参数,在不违反施加约束的情况下从模糊测试接收随机字节。
- 最后,将这些程序融合成一个单一的模糊驱动程序,其中每个唯一种子的代码使用随机字节进行调度。
2.5.1、论据约束推理
对于具有不可变数组类型或标量类型的参数,PromptFuzz将其识别为模糊测试中随机字节的潜在接收者。然而,这些参数通常会受到一些约束,这些约束会显著影响模糊驱动的有效性:
- ArrayLength(A, n): The argument 𝑛 represents the length limit of array 𝐴.
- ArrayIndex(A, i): The argument 𝑖 denotes an index within the array 𝐴.
- FileName(S): The argument 𝑆 represents a string containing a file path.
- FormatString(S): The argument 𝑆 represents a format string.
- AllocSize(n): The argument 𝑛 indicates the size of buffer allocations.
- FileDesc(fd): The argument 𝑓 𝑑 represents a file descriptor in the operating system.
PromptFuzz通过对种子库中程序的静态代码分析,推导出这些约束。
2.5.1、模糊驱动融合
与Fuzzed DataProvider类似,PromptFuzz将模糊测试的随机字节输入转换为指定类型的变量,供库API调用。对于每一个转换后的参数,PromptFuzz试图为它们提供几个随机生成的值。如果PromptFuzz的净化器检测到错误,则论元的转换将被取消。此外,转换后的论元的常量值被收集作为初始种子语料。对于具有推断约束的参数,它们的值被设置为满足所识别的约束。一旦转换完成,PromptFuzz将合成一个新的模糊驱动程序,并有条件地调用每个种子程序。在这一过程中,各种子程序根据模糊测试消耗的几个特定字节进行调度。
三、评估
在本节中,我们进行了综合评价,以证明Prompt Fuzzy的有效性。首先,我们通过OSS - Fuzz对14个经过多年广泛模糊测试的开源库进行了PromptFuzz评测。我们比较了PromptFuzz的模糊驱动程序与其他模糊驱动程序生成方法的代码覆盖率。其次,我们评估了PromptFuzz生成的模糊驱动程序的缺陷发现的有效性。最后,我们对PromptFuzz的关键组件进行评估,以说明每个组件对其整体有效性的贡献。
所有实验均在一台具有48核CPU的服务器上进行,主频为2.50 GHz,RAM为128GB,运行64位版本的Ubuntu 20.04 LTS。LibFuzzer是用于所有评估的灰盒模糊引擎。
3.1、与Hopper和OSS-Fuzz对比
为了评估PromptFuzz生成的模糊驱动程序在代码覆盖率上的有效性,我们将库的分支覆盖率与OSS - Fuzz中手工构造的模糊测试和最先进的自动库模糊解决方案Hopper进行了比较。在评估过程中,我们在每个库上运行OSS - Fuzz的Hopper和fuzz驱动,运行时间为24小时。在OSS - Fuzz中,如果一个函数库有多个模糊驱动程序,我们确保每个驱动程序在不同的CPU核上独立运行相同的24小时时间。

评价结果见表。在与OSS - Fuzz和Hopper的模糊驱动在14个库上的比较中,PromptFuzz在14个库中的8个库中显示出最高的分支覆盖率。在其余6个PromptFuzz没有排名靠前的库中,cJSON和zlib的覆盖率不足。对于libjpeg-turbo、libpcap、re2和c - ares,覆盖率差距在1000个代码分支的范围内,在本研究范围内被认为是可以接受的。
与OSS - Fuzz相比,PromptFuzz在所有库中的分支覆盖率( 40.07 % )均高于OSS - Fuzz ( 24.88 % )。由于在OSS - Fuzz中提供了多个为curl、zlib和lcms构建的fuzz驱动,并且这些fuzz驱动库被fuzzed了24小时以上,因此结果更加显著。PromptFuzz实现的这种较高的分支覆盖率主要归功于其能够生成覆盖广泛的库使用场景的程序。
与Hopper通过解释性模糊化自动合成模糊驱动相比,PromptFuzz同样获得了更高的分支总覆盖率( 40.07 % vs.24.05 % )。PromptFuzz的性能优于Hopper的主要原因有两个。
- 首先,PromptFuzz利用LLMs的内部知识,有效地提取了libTIFF、嵌入式数据库sqlite3、lcms等多种库API中关于API相互依赖的复杂信息,而Hopper则盲目地对其进行推断。
- 其次,Hopper无法为libaom、libvpx、re2等需要迭代调用库API的库生成必要的代码模式,因为它缺乏对条件文法的支持。相比之下,PromptFuzz能够支持所有类型的控制流转换。
总体而言,PromptFuzz比OSS - Fuzz和Hopper生成的模糊驱动程序具有更高的代码覆盖率。
3.2、缺陷检测的有效性
在报告的44个独特的崩溃中,有33个被确定为有效的bug,并已报告给各自的社区。截至撰写本文时,已确认的bug有27个,其余6个bug正在等待响应。
3.3、PromptFuzz组件的有效性
在本节中,我们通过实验来考察所提出的技术对Prompt Fuzzy有效性的影响。下表给出了对净化后的错误程序的详细分析结果和PromptFuzz在先前实验中推断的参数约束。

3.3.1、错误程序净化
PromptFuzz的净化过程中每个过程净化的程序数量如表所示。可以观察到,大多数错误程序( 23821,63.89 %)都是由于语法错误而被净化的。此外,PromptFuzz的执行和模糊净化过程识别出10,260个程序(27.51 %)表现出异常的运行时行为。此外,由于代码覆盖率不足,有3202个程序通过了覆盖率净化。在经过PromptFuzz执行和模糊净化的10260个程序中,我们分析了它们的崩溃报告,以研究导致异常运行时行为的因素。检测到的最普遍的问题是分割违规( 3394 , 33.07 %)和内存泄漏(3 003 , 29.26%)的识别。
为了调查程序是否被正确净化,我们进行了一项研究,在每个库中随机选择10个程序进行了执行净化和模糊净化,10个程序进行了覆盖净化。我们审查了这些程序的代码,并进行了仔细的调试,以确定它们是否得到了适当的净化。结果显示,几乎所有的140个方案通过运行时净化进行净化的确包含了对库API的误用。唯一的异常是FSan在捕包函数库libpcap2中检测到的一个潜在的资源泄漏,它是一个真正的漏洞,源自于文件描述符的泄漏,这是由于函数pcap_Create和pcap_closed之间的资源分配和释放不匹配造成的。如果没有FSan,隐藏在捕包函数库libpcap中最常用的代码模式中的错误将永远不会被发现。在覆盖率净化的140个程序中,有108个程序被确认存在错误的库使用,并且由于存在不可访问的库API调用而被正确净化。其中,25个是由于库初始化不正确造成的,40个是由于API上下文错误造成的,43个是由于库API配置无效造成的。剩余的32个程序由于模糊器未能在PromptFuzz的模糊净化过程分配的时间预算范围内生成能够达到某些理论上可达的库API调用的输入而被错误净化。
值得注意的是,虽然在PromptFuzz中实现的净化过程可能会无意地排除正确运行的程序和真正的buggy程序,但它们在减少bug检测期间错误崩溃的发生方面具有重大影响。
3.3.2、论据约束推理
UTOPIA和Fuzzed DataProvider
3.3.3、覆盖引导突变
PromptFuzz开发了一个覆盖引导变异来指导LLM生成有价值的程序。为了评估其有效性,我们实验将其与随机盲变异方法进行比较。在本实验中,盲变异方法被配置为随机选择具有相同默认组合长度的库API。为了保证公平性,覆盖引导的变异设置和盲变异设置被分配相同的查询预算(即5美元),并执行直到预算耗尽。此外,为了降低LLMs的随机性,将LLMs的温度设置为0.1,每组实验重复5次。

上图显示了当配置两种不同的变异方法时,PromptFuzz模糊循环中生成的种子程序所获得的累积覆盖分支。当给定相同的查询预算时,在14个库中的11个库中,覆盖引导变异优于随机盲变异。例外情况为libaom、zlib、libpng。尽管在预热阶段分支覆盖率的增长率较低,但由于覆盖和种子计划获得的反馈,覆盖引导变异在11个库中超过了随机盲变异。这使得PromptFuzz能够对包含有意义的API组合的提示进行变异,从而创建达到更深层次库状态的程序。
对于libaom、zlib、libpng,导致性能不足的因素包括API之间存在松散耦合以及这3个库中存在大量的API。在libaom中,API之间表现出高度的一致性,API之间的相互依赖关系从它们的声明中明显地表现出来。这种清晰度有利于LLM生成程序,即使在随机选择API的情况下也是如此。对于libpng,大量的API倾向于在局部状态中捕获覆盖率引导的变异设置,而随机变异允许探索更广泛的API。这种性能不足有望通过为LLM分配更大的查询预算来解决。虽然覆盖率引导的变异并不能保证在所有库中都有较好的表现,但是实验结果证明了这一点。
四、有效性威胁
为确保PromptFuzz实现的正确性,我们付出了艰苦的努力。然而,在实现过程中仍然可能存在一些遗留的缺陷。此外,我们还发现了一些威胁实验有效性的因素,除了实施带来的威胁。
-
从大模型的角度
在我们的实验中,我们使用GPT3.5 [ 54 ]作为LLM模型,使用PromptFuzz构造的提示来生成程序。不同模型和工具的性能和行为可能会有显著差异,从而导致不同的输出和结果。因此,在PromptFuzz上应用不同的LLM模型时需要谨慎。尽管我们使用了一个特定的LLM模型进行了实验,但我们的研究结果可能为其他LLM模型提供了见解,这表明如果使用更强大的LLM模型,我们的工具的性能可能会得到改善。 -
从开源库的角度
我们选择的评估库是开源的。这些库的源代码是公开的,并被用作我们选择的训练数据。如果将PromptFuzz应用于封闭源库,评价结果可能会有差异。然而,微调LLMs可以缓解这些问题。
五、总结
本文提出了覆盖率引导的模糊器PromptFuzz,用于自动生成模糊驱动。PromptFuzz通过在LLMs上构建的新型模糊循环纸张起毛产生模糊驱动。在覆盖率反馈的指导下,PromptFuzz迭代地构建LLMs的提示,以高效地探索广泛的API使用。得益于我们设计的错误程序预言,PromptFuzz可以清理几乎所有由LLM生成的错误程序。PromptFuzz依靠LLMs的代码合成能力,不需要任何消费者代码或领域知识就可以创建模糊驱动程序。PromptFuzz生成的模糊驱动具有更高的分支覆盖率,是OSS - Fuzz的1.61倍,是Hopper的1.67倍。此外,由PromptFuzz生成的模糊驱动程序成功地检测出了44个崩溃中的33个以前未知的真实错误,其中27个已被社区确认。
这篇关于【论文阅读】Prompt Fuzzing for Fuzz Driver Generation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









