本文主要是介绍ISCC2024个人挑战赛WP-MISC,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(非官方解,以下内容均互联网收集的信息和个人思路,仅供学习参考)
where is flag
下载附件,解压出pyc,然后到下面网址反编译
python反编译 - 在线工具

记住c,是密文,
Key是 k5fgb2eur5styn0lve3t6r1s
AES ecb解密

解密网址:https://www.lddgo.net/encrypt/aes
成语学习
压缩包密码:57pmYyWt
解压后把解压出的文件改后缀为.zip,再次解压,O7avZhikgKgbF下有个flag.txt,去https://www.mklab.cn/utils/hmac解密,成语是明文,密钥是食物

Hash包上ISCC{}
钢铁侠在解密
解题思路
把图片放进工具,可以提取c1 c2

然后生成文件
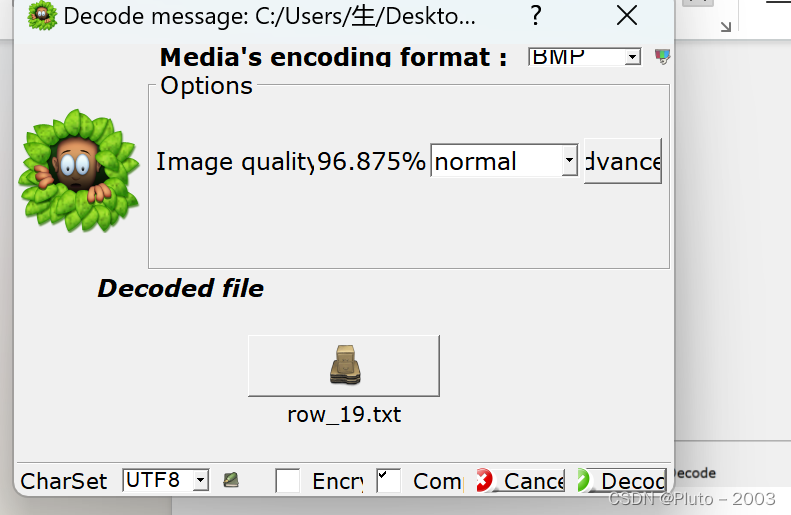
 打开小字条可以ne
打开小字条可以ne
然后写脚本
def HGCD(a, b):
if 2 * b.degree() <= a.degree() or a.degree() == 1:
return 1, 0, 0, 1
m = a.degree() // 2
a_top, a_bot = a.quo_rem(x ^ m)
b_top, b_bot = b.quo_rem(x ^ m)
R00, R01, R10, R11 = HGCD(a_top, b_top)
c = R00 * a + R01 * b
d = R10 * a + R11 * b
q, e = c.quo_rem(d)
d_top, d_bot = d.quo_rem(x ^ (m // 2))
e_top, e_bot = e.quo_rem(x ^ (m // 2))
S00, S01, S10, S11 = HGCD(d_top, e_top)
RET00 = S01 * R00 + (S00 - q * S01) * R10
RET01 = S01 * R01 + (S00 - q * S01) * R11
RET10 = S11 * R00 + (S10 - q * S11) * R10
RET11 = S11 * R01 + (S10 - q * S11) * R11
return RET00, RET01, RET10, RET11
def GCD(a, b):
print(a.degree(), b.degree())
q, r = a.quo_rem(b)
if r == 0:
return b
R00, R01, R10, R11 = HGCD(a, b)
c = R00 * a + R01 * b
d = R10 * a + R11 * b
if d == 0:
return c.monic()
q, r = c.quo_rem(d)
if r == 0:
return d
return GCD(d, r)
#填入你的
c1 = 772167432990792284909246503485373564827423662851242942936975255372049079405922631297290251556585973686934890832849659590583140085382968742093943770675428869862385498404594511153139222640717296752471214514504131745657446656125557844901271640715066516885103781839826160994115784487472680768100661183394705879985459364111608990579323275737784566381691336604304955278256883423529263632439800163659992975948190325138106290810250677692972270138775860224366956601449524284187574453201455615890650328671385208998671350863314115885591106853229807982994778140445245927435098328511597441847163210560193373848931171804024813203
c2 = 2185342810520022586336689385344512546273762827830100178019097650928259687501314269853262487551357398728297194586835620643774892721766418892806910363445011749061907166747343507608781390978770926747094305381146737393535026687526960319434536017583904894554530861557175239362345485251281115748843999781275445445703433894295561819134209833028751302490721592934170848146618432688497403964700464690490125298139227095348433433890543904289070662974904820444031627359763396201976863505823922710618734646465997511025062911757600571747673908775617096321384264403844217607622754902280707445209499295488447523319414362500287112323
N=14333611673783142269533986072221892120042043537656734360856590164188122242725003914350459078347531255332508629469837960098772139271345723909824739672964835254762978904635416440402619070985645389389404927628520300563003721921925991789638218429597072053352316704656855913499811263742752562137683270151792361591681078161140269916896950693743947015425843446590958629225545563635366985228666863861856912727775048741305004192164068930881720463095045582233773945480224557678337152700769274051268380831948998464841302024749660091030851843867128275500525355379659601067910067304244120384025022313676471378733553918638120029697
e = 52595
pad1 = 1769169763
pad2 = 1735356260
PR.<x>=PolynomialRing(Zmod(N))
g1 = (x*2^32+pad1)^e - c1
g2 = (x*2^32+pad2)^e - c2
X=584734024210292804199275855856518183354184330877
print(g1(X),g2(X))
res = GCD(g1,g2)
m = -res.monic().coefficients()[0]
print(m)
print(bytes.fromhex(hex(m)[2:]).decode().replace("flag{",'ISCC{'))
需要去docker pull一个sagemath环境,然后去sage运行

最后获取flag ISCC{}
工业互联网模拟仿真数据分析
第一问
在某些网络会话中,数据包可能保持固定大小,请给出含有此确定性特征的会话IP地址和数据包字节大小值。
答案:IP地址:XX.XX.XX.XX,XX.XX.XX.XX,…,数值:XX
补充说明:IP顺序从小到大排列,涉及的IP个数由选手自己判断
只有192.168.1.2
192.168.1.4的Length大小不变
192.168.1.2,192.168.1.4,24
第二问
题目二:通信包数据某些字段可能为确定的,请给出确定字节数值。
tshark -r a.pcap -T fields -e data.data -Y "data.len==12"
2024f7b039ae1f546c8e8b1b
2024b939b6fdd3a92dacee64
2024fd300d3fd17b85d1ae51
20249cf615176e00d3fde264
20247b5207a1d2b639fe1e55
202432b3b42ff36424a15d01
2024f2122ad847094be81d58
2024e866d7ec7b7d5ae618bf
20244057c7e66ca371b2c938
202433b4fba38bac7e29bc6a
2024796986cd9b1fc559ad61
20248c6b6efd392e9839a3eb
202462434670e7e76d766c58
20241cc66ab532ff8c8f1d2e
很明显就是前面的2024
第三问
一些网络通信业务在时间序列上有确定性规律,请提供涉及的IP地址及时间规律数值(小数点后两位)
答案:IP地址:XX.XX.XX.XX,XX.XX.XX.XX,…,数值:XX
看文末的流量分组
第五组 - 192.168.1.3 192.168.1.5, 这一组的时间间隔固定
192.168.1.3,192.168.1.5,0.06第四问
一些网络通信业务存在逻辑关联性,请提供涉及的IP地址
答案:XX.XX.XX.XX,XX.XX.XX.XX,…
看文末的流量分组,就能看出这三个IP是有业务关联性的
192.168.1.3 --> 192.168.1.2 --> 192.168.1.6192.168.1.2,192.168.1.3,192.168.1.6第五问
网络数据包往往会添加数据完整性校验值,请分析出数据校验算法名称及校验值在数据包的起始位和结束位(倒数位)
答案:XXXXX,X,X
五个字符的校验算法,先假设是 CRC16 或者 CRC32
倒数位必为1
尝试CRC16 CRC32并尝试0-10为起始位
为CRC16,4,1时成功提交
192.168.1.2,192.168.1.4,24
2024
192.168.1.3,192.168.1.5,0.06
192.168.1.2,192.168.1.3,192.168.1.6
CRC16,4,1
ISCC{192.168.1.2,192.168.1.4,24,2024,192.168.1.3,192.168.1.5,0.06,192.168.1.2,192.168.1.3,192.168.1.6,CRC16,4,1}
ISCC{192.168.1.2,192.168.1.4,24,2024,192.168.1.3,192.168.1.5,0.06,192.168.1.2,192.168.1.3,192.168.1.6,CRC16,4,1}
FunZip
nwalk分离文件,发现有个sheet1.xml
打开看看发现

有表格像素的标签,且有不一致的地方 想到可能存在二维码
脚本跑
import openpyxl
from PIL import Image
def extract_bold_cells(file_path):
bold_cells = []
wb = openpyxl.load_workbook(file_path)
sheet = wb.active
for row in sheet.iter_rows():
for cell in row:
if cell.font.bold:
bold_cells.append((cell.column, cell.row))
return bold_cells
def generate_image(bold_cells):
max_x = max(cell[0] for cell in bold_cells)
max_y = max(cell[1] for cell in bold_cells)
img = Image.new("1", (max_x, max_y), color=1) # 生成白色的图像
pixels = img.load()
for cell in bold_cells:
x, y = cell[0] - 1, cell[1] - 1 # Excel中的列和行是从1开始的,而图像的像素是从0开始的
pixels[x, y] = 0 # 将加粗单元格对应的像素点设置为黑色
return img
if __name__ == "__main__":
excel_file_path = "attachment-1.xlsx"
bold_cells = extract_bold_cells(excel_file_path)
img = generate_image(bold_cells)
img.show() # 显示图像
img.save("generated_imag.png") # 保存图像
print("Image generated successfully!")
时间刺客
1.得到流量为usb
放入kali,进行数据提取
tshark -r 6.pcap(修改为你的文件名字) -T fields -e usb.capdata | sed '/^\s*$/d' > usbdata.txt

- 分离出来发现没有带冒号,用以下脚本加上冒号
f=open('usbdata.txt','r')
fi=open('out1.txt','w')
while 1:
a=f.readline().strip()
if a:
if len(a)==16: # 鼠标流量的话len改为8
out=''
for i in range(0,len(a),2):
if i+2 != len(a):
out+=a[i]+a[i+1]+":"
else:
out+=a[i]+a[i+1]
fi.write(out)
fi.write('\n')
else:
break
fi.close()
- 再使用以下脚本对加上冒号的usb'数据进行提取
#最后用脚本提取
# print((line[6:8])) #输出6到8之间的值
#取出6到8之间的值
mappings = { 0x04:"A", 0x05:"B", 0x06:"C", 0x07:"D", 0x08:"E", 0x09:"F", 0x0A:"G", 0x0B:"H", 0x0C:"I", 0x0D:"J", 0x0E:"K", 0x0F:"L", 0x10:"M", 0x11:"N",0x12:"O", 0x13:"P", 0x14:"Q", 0x15:"R", 0x16:"S", 0x17:"T", 0x18:"U",0x19:"V", 0x1A:"W", 0x1B:"X", 0x1C:"Y", 0x1D:"Z", 0x1E:"1", 0x1F:"2", 0x20:"3", 0x21:"4", 0x22:"5", 0x23:"6", 0x24:"7", 0x25:"8", 0x26:"9", 0x27:"0", 0x28:"\n", 0x2a:"[DEL]", 0X2B:" ", 0x2C:" ", 0x2D:"-", 0x2E:"=", 0x2F:"[", 0x30:"]", 0x31:"\\", 0x32:"~", 0x33:";", 0x34:"'", 0x36:",", 0x37:"." }
nums = []
keys = open('out1.txt')
for line in keys:
if line[0]!='0' or line[1]!='0' or line[3]!='0' or line[4]!='0' or line[9]!='0' or line[10]!='0' or line[12]!='0' or line[13]!='0' or line[15]!='0' or line[16]!='0' or line[18]!='0' or line[19]!='0' or line[21]!='0' or line[22]!='0':
continue
nums.append(int(line[6:8],16))
keys.close()
output = ""
for n in nums:
if n == 0 :
continue
if n in mappings:
output += mappings[n]
else:
output += '[unknown]'
print(output)
运行得到
FLAGPR3550NWARDSA2FEE6E0
压缩密码为:PR3550NWARDSA2FEE6E0
- 解压之后得到空白txt,发现是时间戳隐写,直接用以下脚本进行提取
(记得把脚本和解压的放在同一目录下),跑出来加上ISCC得到flag
import os
un_time=1728864000.0
for i in range(18):
filename = ".{}.txt".format(i)
file_attr = os.stat(filename)#读取文件属性
dtime = str(file_attr.st_mtime)#获取创建时间
print(chr(int(float(dtime)-un_time)),end='')
有人让我给你带个话
打开附件得到两个文件,用010打开png文件,直接查看png文件尾
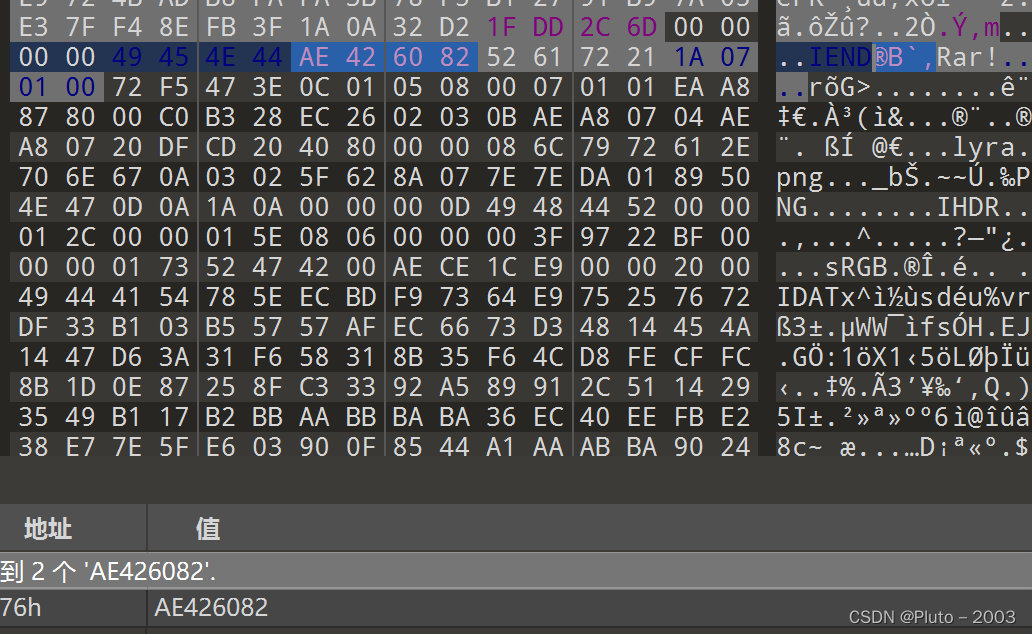
发现文件尾后还藏了文件
使用binwalk分离文件
得到名字为lyra的png

搜索后得知lyra是一种语音的隐写
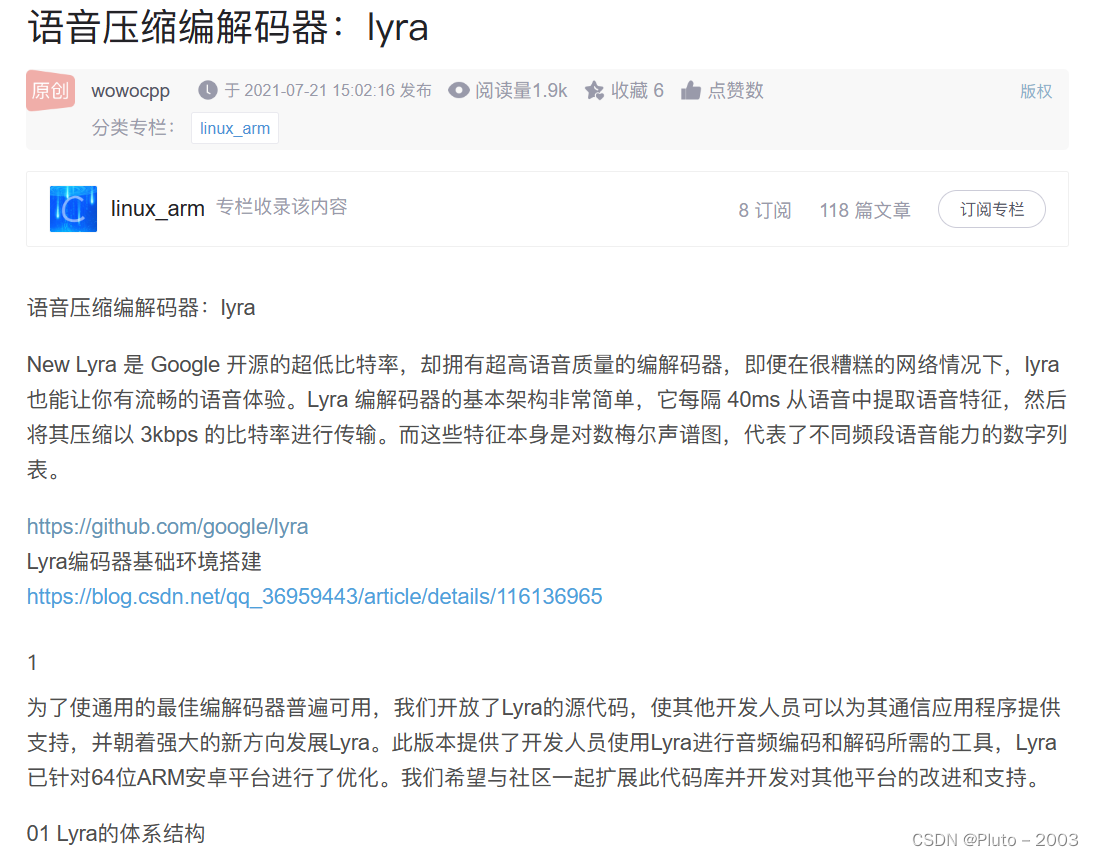
010打开无后缀文件发现符合lyra文件特征

给文件加上后缀
使用bazel对文件进行低频3200HZ采样

得到wav文件,打开后发现是念社会主义核心价值观的语音

语音转文字后解码,得到flag

精装四合一


这篇关于ISCC2024个人挑战赛WP-MISC的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!