本文主要是介绍重开之数据结构(二刷),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言:
由于前段时间学习效率不高,导致后面复习前面数据结构没有一个大纲,因此打算重新来学习以下数据结构,期望再次把数据结构学透,并有深刻的印象.并且记录每一次的学习记录 以便于后续复习
二分查找
需求:在有序数组arr内,查找target值
- 如果找到返回索引位置
- 如果找不到返回 -1
基础版
步骤:
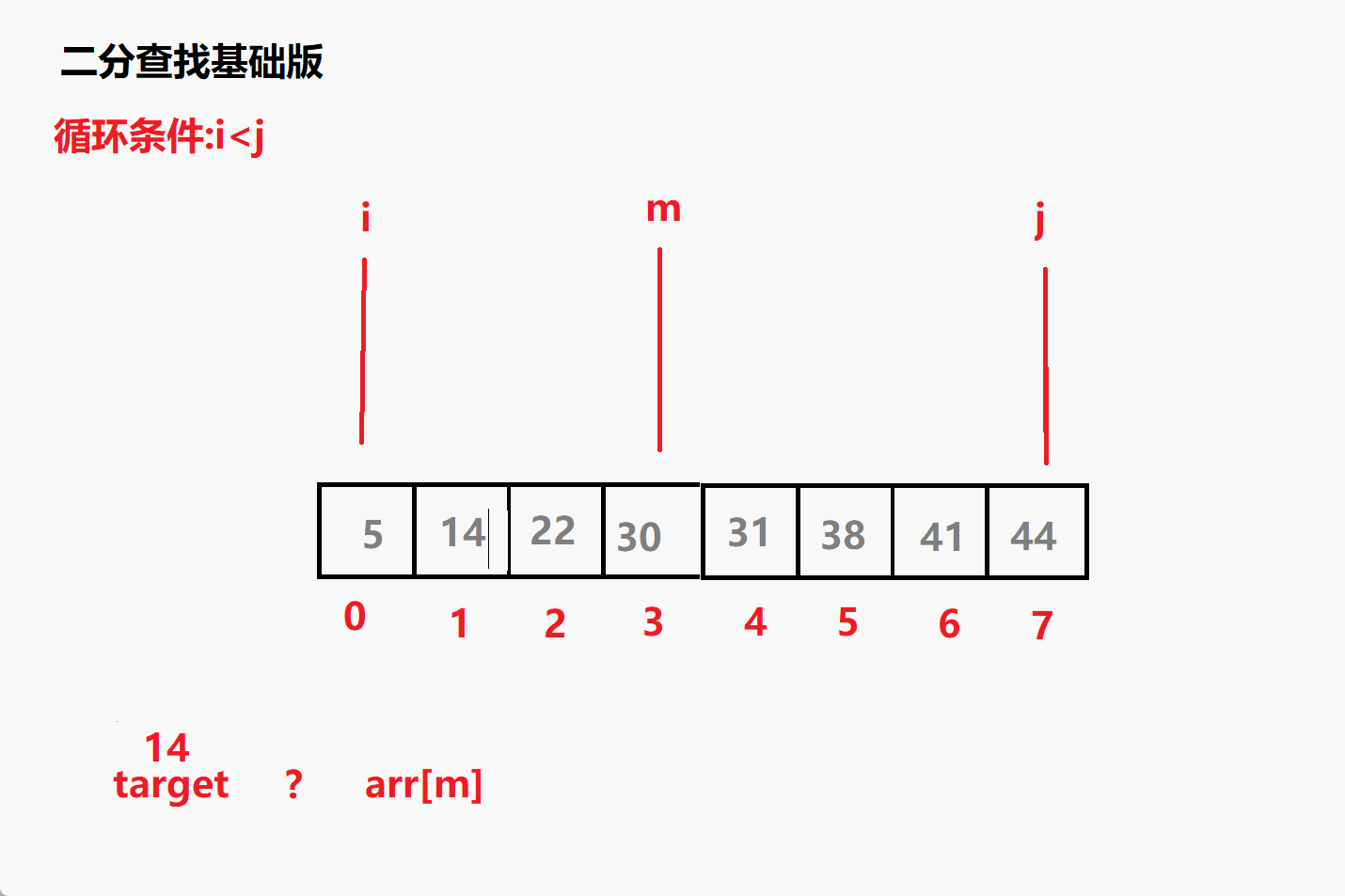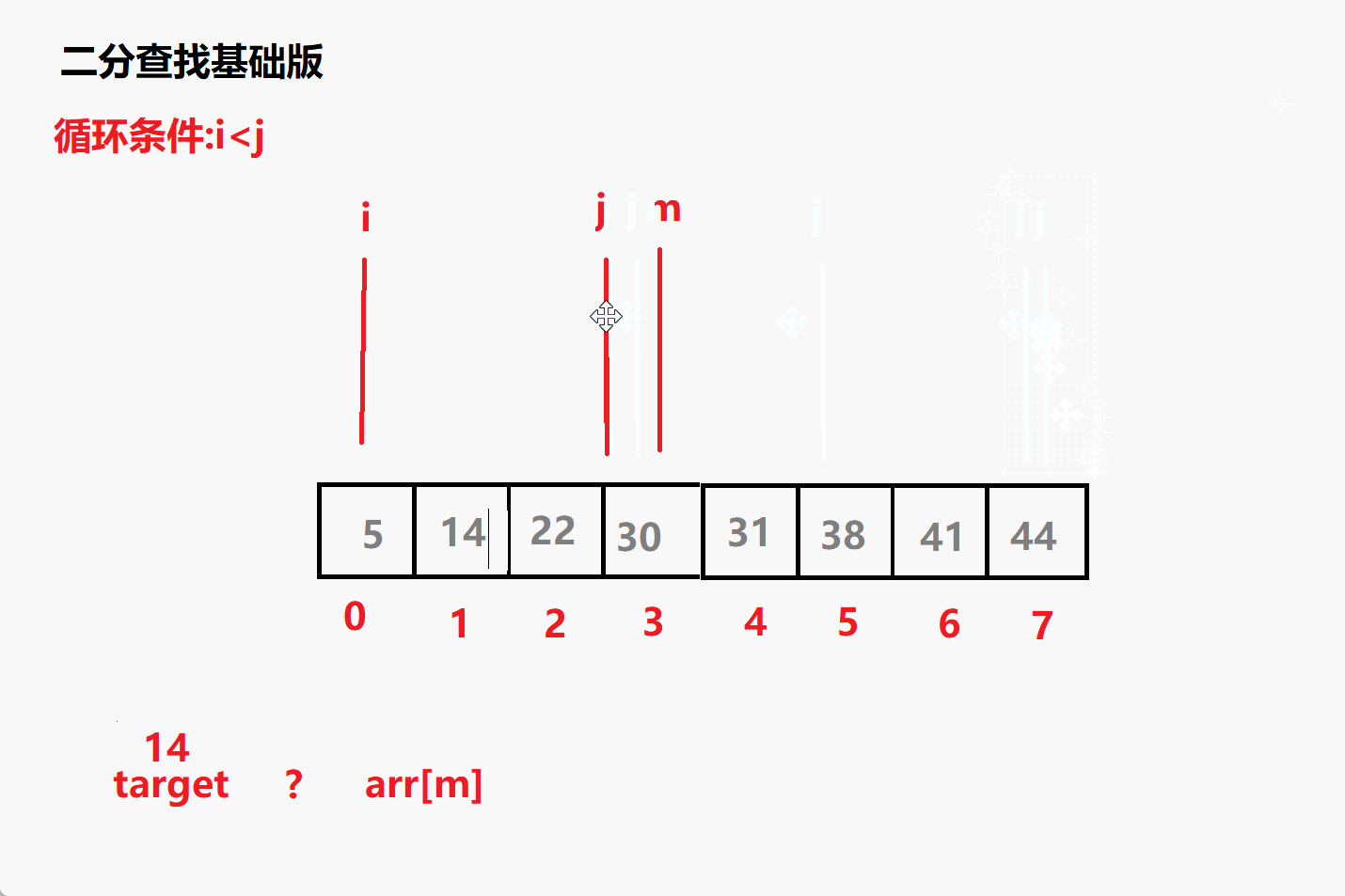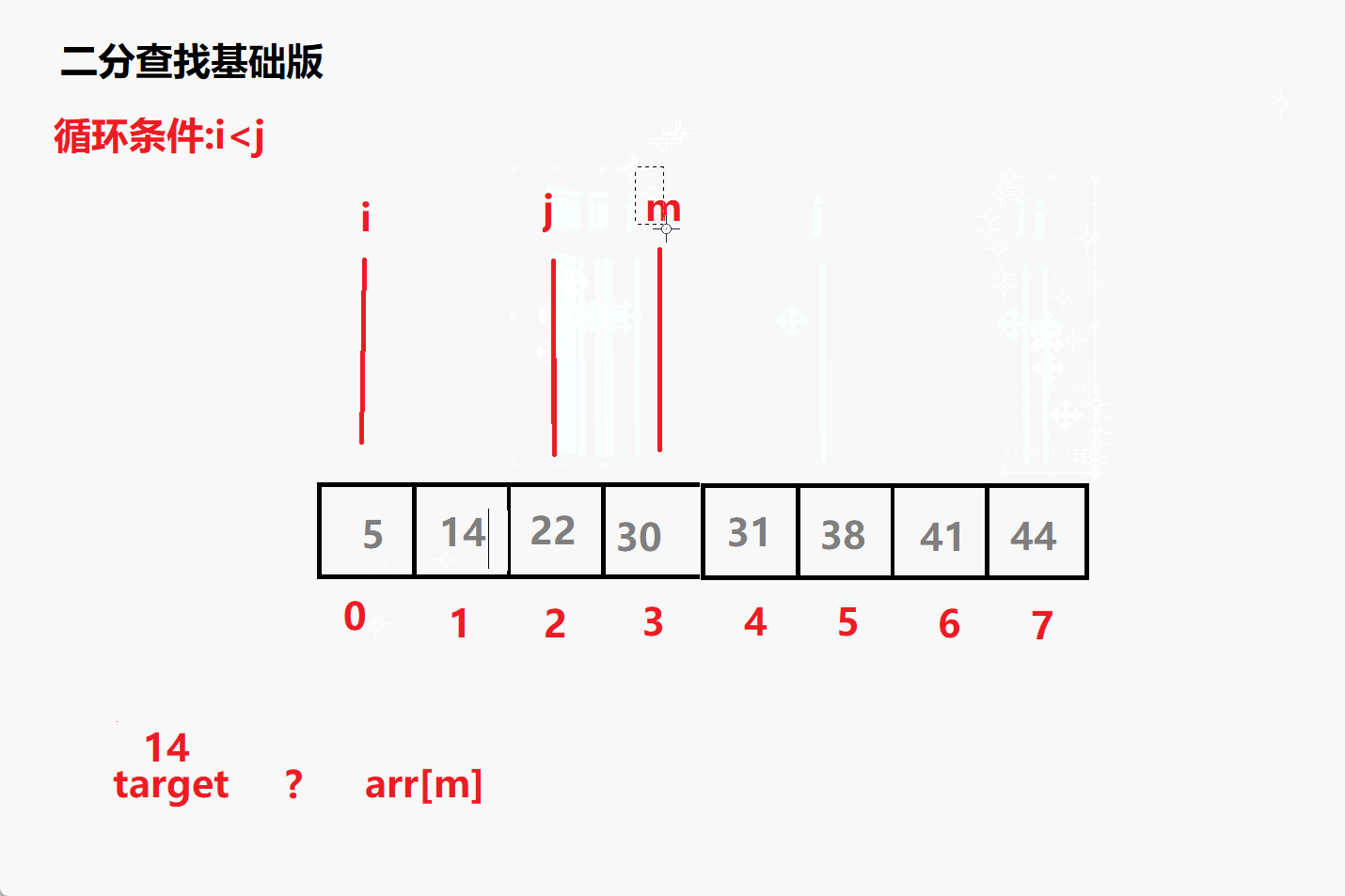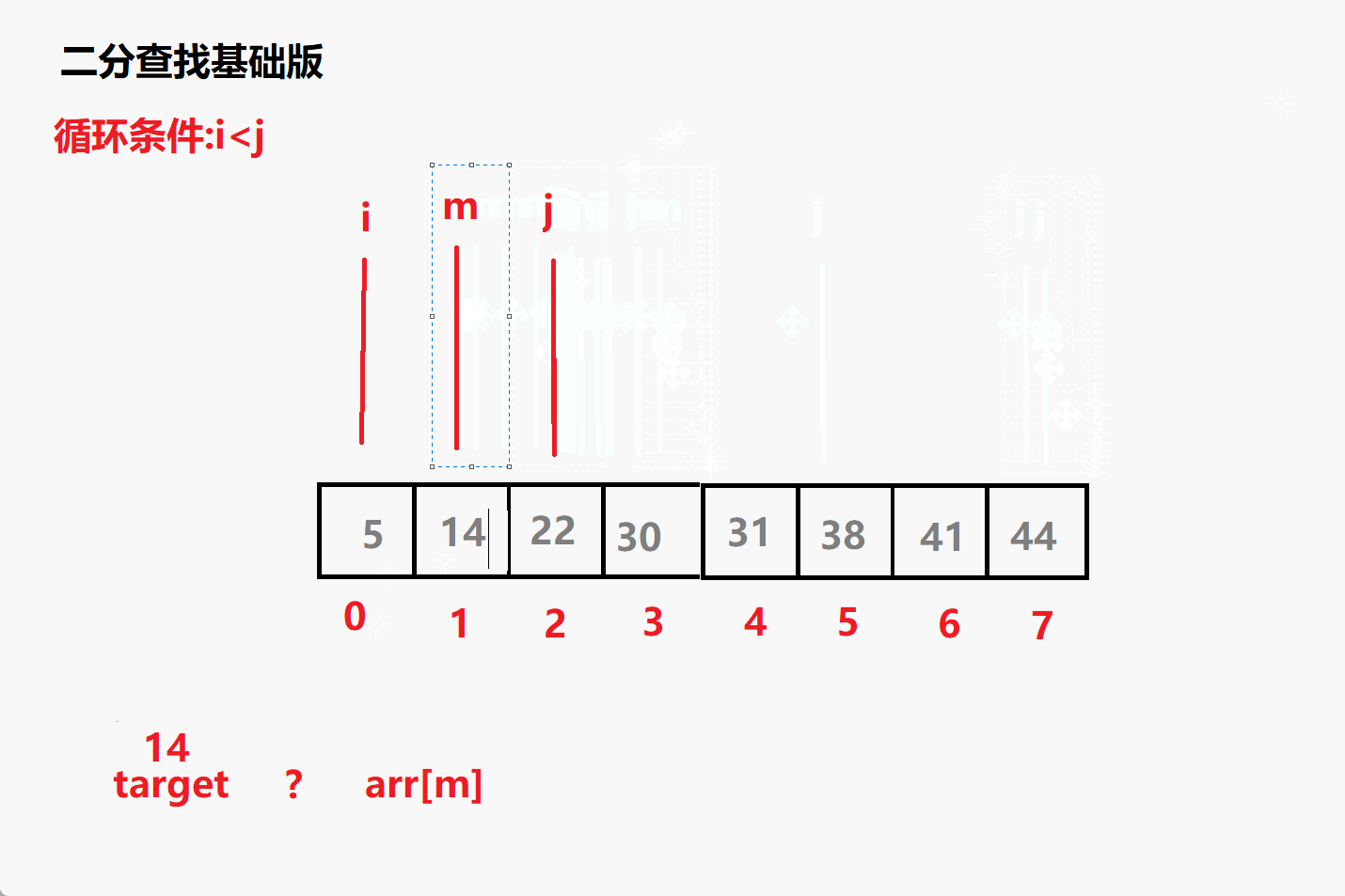
- 设定两个指针(左闭右闭) 分别为 i= 0,j = arr.length-1
- 循环条件 i<j ,如果i>j 结束查找 没找到
- 定义变量 m = (i+j)/2
- 比较target与m索引的值
(1)target < arr[m] —> j = m-1
(2)target > arr[m] —> i = m+1
(3)target = arr[m] —> return m - 循环结束没找到 返回-1;
public static int binarySearch(int[] arr,int target){int i = 0,j = arr.length-1;//设置指针和初始值while(i<j){int m = (i+j)/2;if(target<arr[m]){j = m-1;}else if(arr[m]<target){i = m+1;}else{return m;}}return -1;}
查找14动态演示
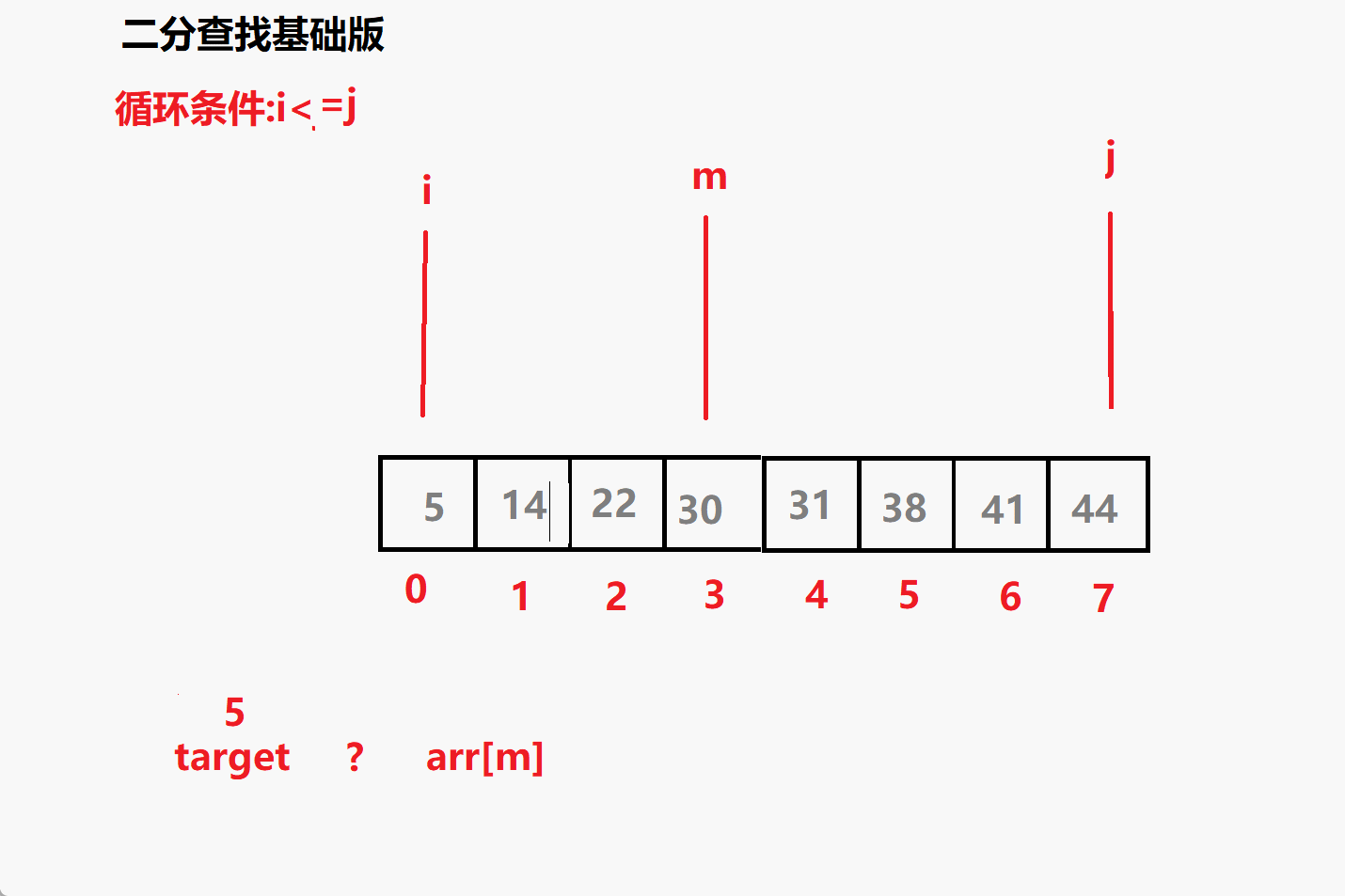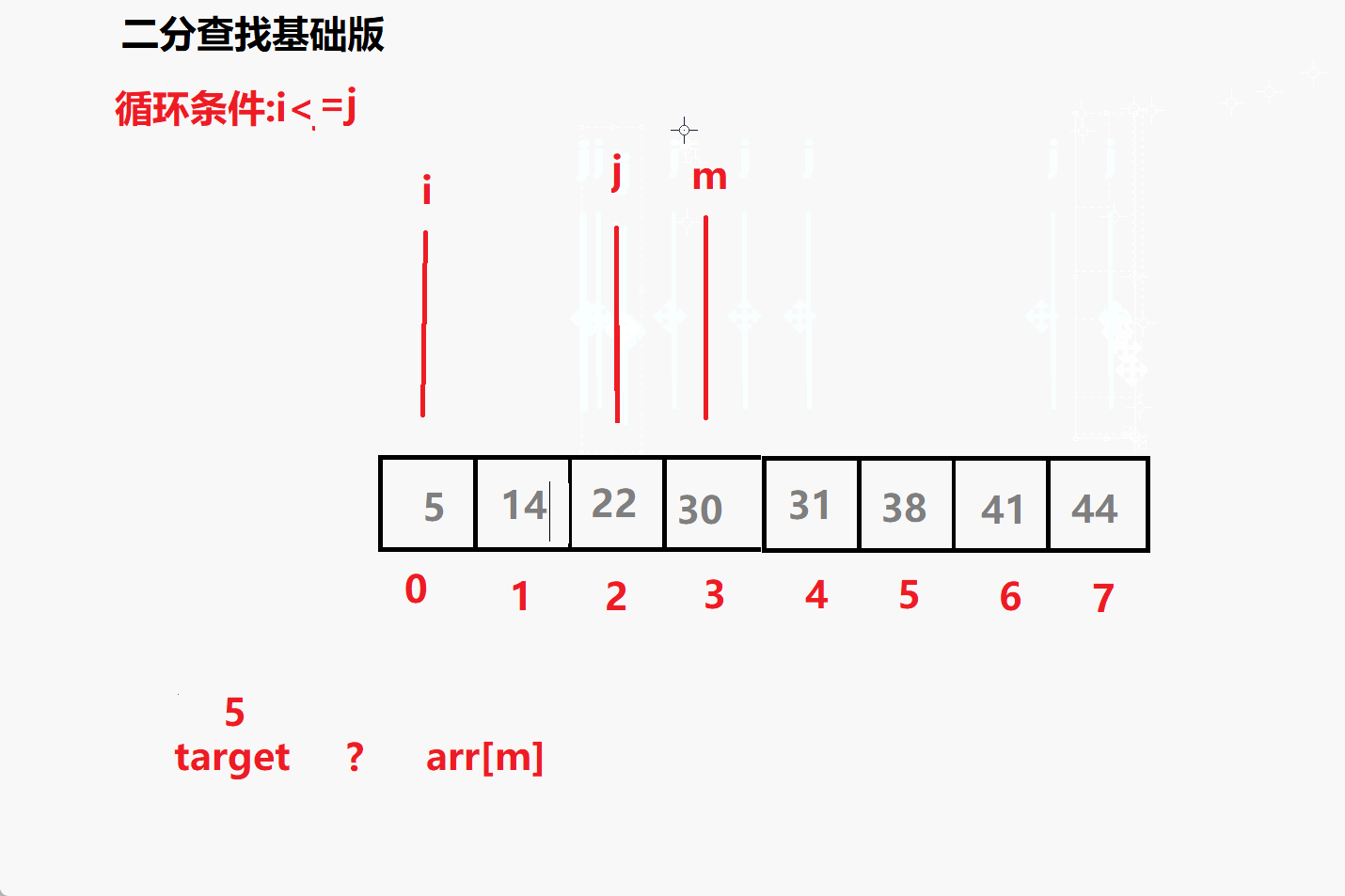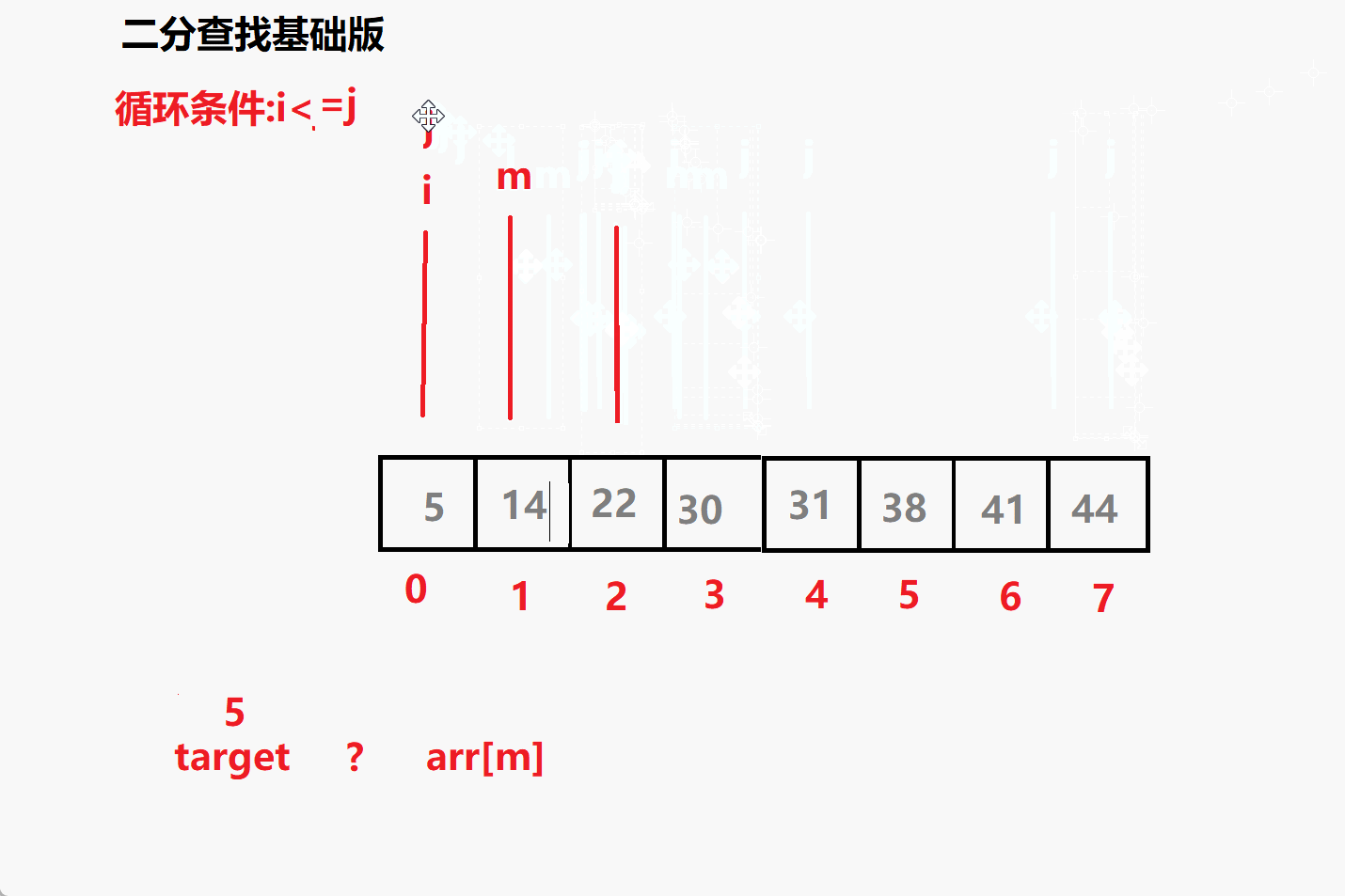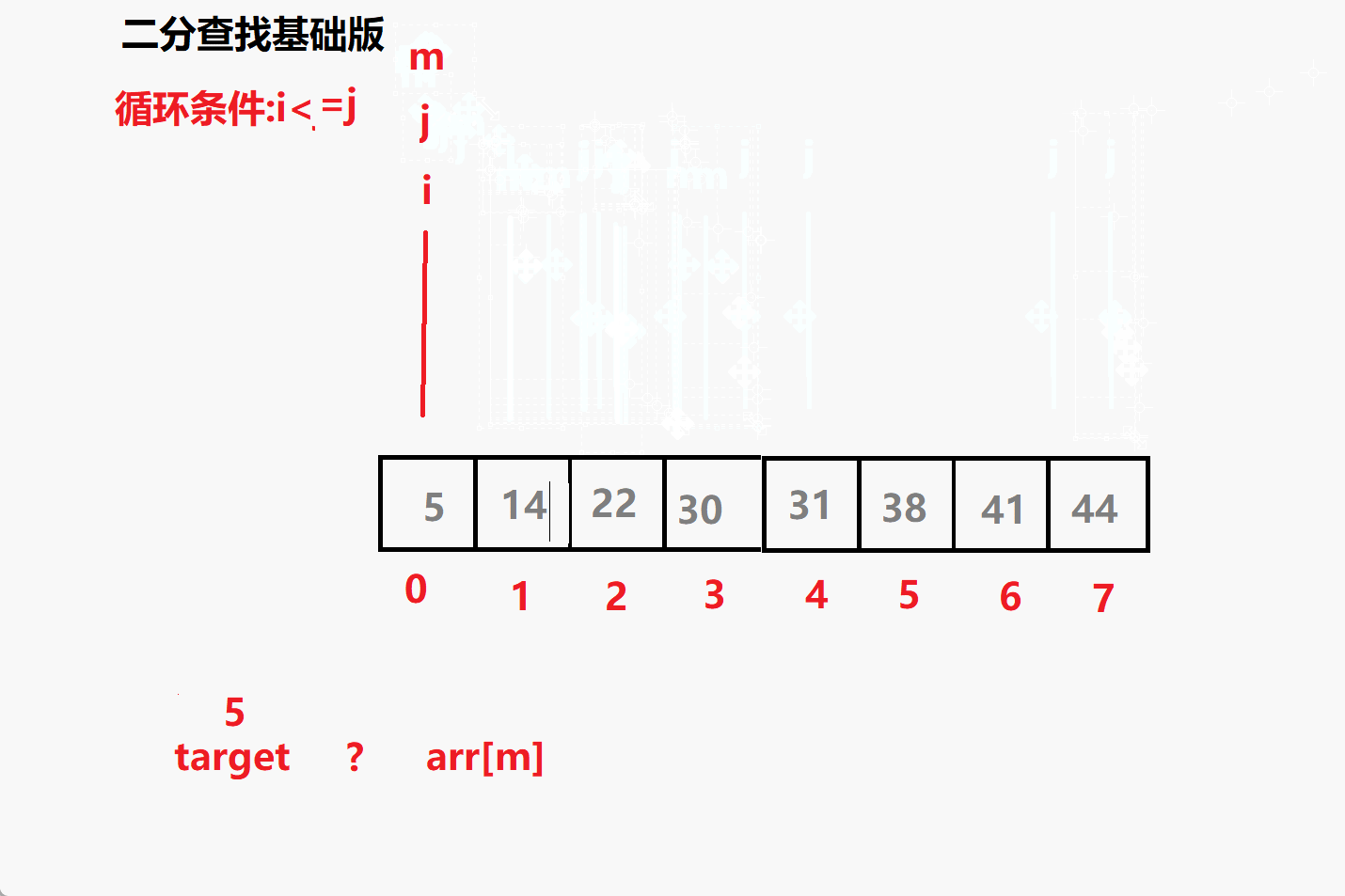
问题一: 循环条件为i<=j 为什么不是i<j?
相当于多了i=j 这个条件 ,意味着但i=j 时这个元素也要参与比较
比如 查找 5 时 最后 i j m 都会指向5 若没有= 就跳出了循环i,j
就没有参与到比较
问题二: (i+j) /2 是否有问题?
从客观来讲,没有问题 但是在极端情况下,数据量达到整型的最大值的(i+j)就会出现问题 由于计算机存储的数据是有一定的范围的,就有可能会导致算出来的结果为负值 所以要用到位运输 (i+j)>>>1 无符号右移可以避免此情况发生
改动版
思维逻辑大概与基础版相似 考虑在算法的优劣 这种方法相当于基础版更优化了一些
public static int binarySearchAlternative(int[] arr,int target){int i = 0,j = arr.length;//变化一:i 作为查找数据的左闭 而j 只是一个边界不参与运输while (i<j){//i<j 表示 j下标的运算不用参与计算了int m = (i+j)>>>1;if (target<arr[m]){j = m;//j始终保持为边界} else if (arr[m]<target) {i = m+1}else{return m;}}return -1;}
总结
基础版和改动版的区别在于 给定的指针的位置不同
基础版在于 包括 i 索引和j索引的以内包括自身数据查找 为左闭右闭
改动版在于 包括 i 索引到j索引前的数据查找 为左闭右开
这篇关于重开之数据结构(二刷)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








