本文主要是介绍阿里巴巴最新研究突破:自我演化大模型,打破性能天花板,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读
AI论文解读 原创作者 | 柏企

引言:自我进化的新篇章
在人工智能领域,大型语言模型(LLMs)的发展正迎来一场革命性的变革。传统的训练模式依赖于大量的数据预训练和精细的监督调优,这不仅成本高昂,而且随着任务复杂性的增加,模型性能的提升也逐渐遭遇瓶颈。然而,最近的研究开始探索一种全新的训练范式——自我进化。这一概念借鉴了人类的经验学习过程,使得LLMs能够自主获取、精炼经验并从中学习,从而突破现有限制,向超级智能迈进。
自我进化的核心在于模型能够通过自生成的经验进行迭代学习,这一过程不需要外部的数据标注或人工干预。这种自主学习的能力不仅能够显著降低训练成本,还能使模型在处理更为复杂和多样化的任务时表现出更高的效率和适应性。通过这种方式,LLMs可以不断地自我完善,逐步提升其智能水平,最终实现与人类智能相媲美甚至超越人类智能的目标。
本文将深入探讨自我进化在LLMs中的应用,分析其概念框架、实现机制以及面临的挑战,并提出未来的研究方向。通过这一全面的概述,我们希望能够为研究人员提供有价值的见解,推动自我进化LLMs的发展,开启智能系统自主学习和进化的新篇章。
论文标题、机构、论文链接和项目地址
论文标题: A Survey on Self-Evolution of Large Language Models
机构:
- Key Lab of HCST (PKU), MOE; School of Computer Science, Peking University
- Alibaba Group
- Nanyang Technological University
论文链接:https://arxiv.org/pdf/2404.14387.pdf
项目地址:DAMO-ConvAI/Awesome-Self-Evolution-of-LLM at main · AlibabaResearch/DAMO-ConvAI (github.com)
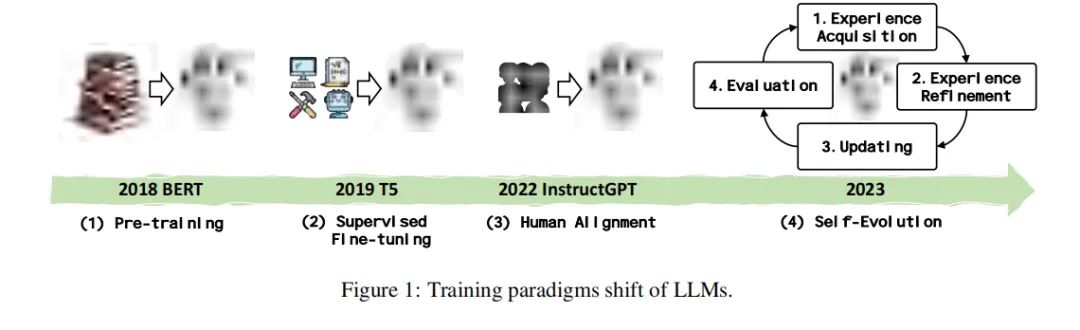
自我进化的概念框架
自我进化是指大型语言模型(LLM)通过自主学习、更新和改进,以适应不断变化的环境和任务的能力。这一概念源于人类的经验学习过程,即通过不断的尝试和错误来适应和掌握新技能。在LLM的自我进化中,这一过程被形式化为一个迭代的循环,涵盖了经验获取、经验精炼、更新和评估四个阶段。
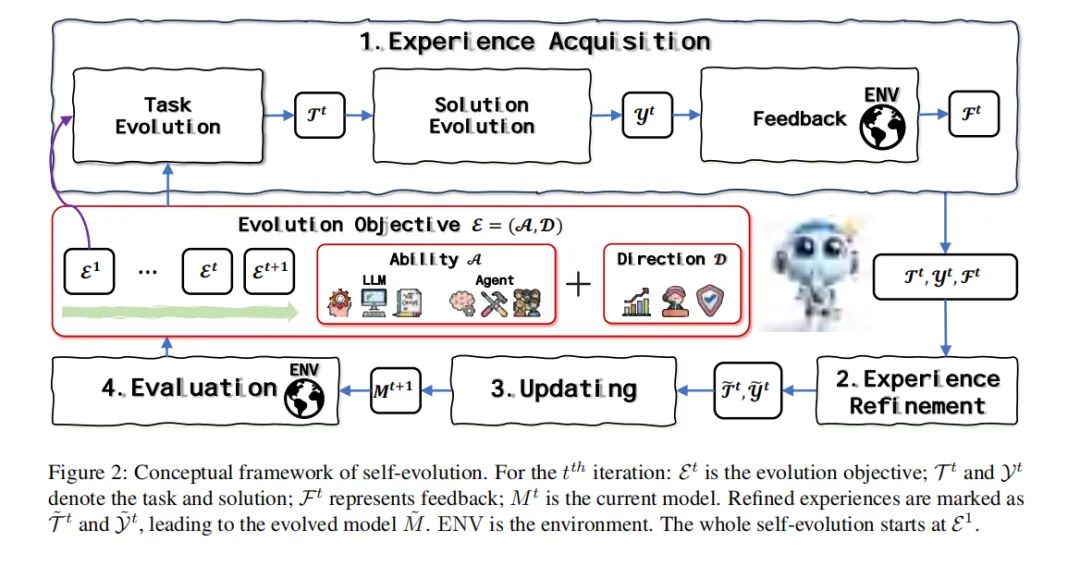
1. 经验获取
在每一次迭代中,模型首先确定一个进化目标(E_t),然后根据这一目标进行新任务(T_t)的生成,解决这些任务并从环境中获得反馈(F_t)。这一阶段的完成标志着新经验的获取。
2. 经验精炼
获取经验后,模型会审查并精炼这些经验,包括丢弃不正确的数据和优化不完美的数据,从而获得精炼后的结果(˜T_t, ˜Y_t)。
3. 更新
利用精炼后的经验,模型进行更新操作,将改进的任务和解决方案集成到其框架中。这确保了模型保持最新状态并进行优化。
4. 评估
迭代周期以评估阶段结束,模型在外部环境中的表现将被评估。这一阶段的结果将为下一次迭代的进化目标(E_t+1)设定基调。
通过这一概念框架,LLM能够类似于人类那样获取、精炼并自主学习,不断适应新的挑战和环境。这一过程不仅突破了传统静态、数据驱动的模型限制,而且标志着向更动态、健壮和智能的系统的转变。
经验获取的策略和方法
经验获取是自我进化过程中的首要步骤,涉及探索和利用两种基本策略。探索(exploration)指的是模型寻求新经验以实现目标,是LLM自我进化的初始阶段。这一过程对于模型自主应对新任务、克服知识限制和提高解决方案有效性至关重要。
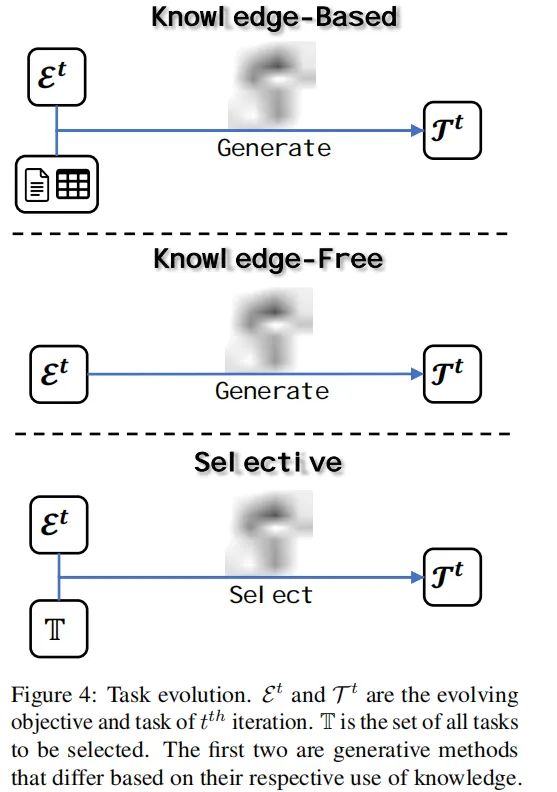
1. 任务进化
模型首先根据当前迭代中的进化目标(E_t)演化新任务。任务进化是启动整个进化过程的关键步骤。我们将现有的任务进化方法归类为基于知识的、无知识的和选择性的三种类型。
- 基于知识的方法:这类方法利用外部知识来演化与进化目标相关的任务,确保任务的相关性和事实的准确性。
- 无知识的方法:这类方法不依赖外部知识,而是使用模型自身生成新任务,提高任务的多样性和创新性。
- 选择性方法:这类方法从已有的大规模任务中选择与当前进化目标最相关的任务,简化任务的策划过程。
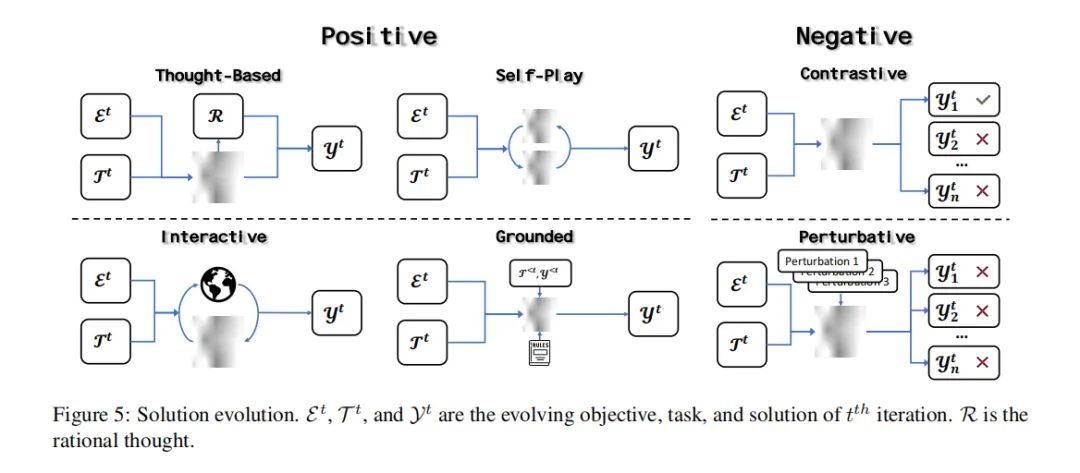
2. 解决方案进化
获取演化任务后,LLM需要解决这些任务以获取相应的解决方案。解决方案的生成直接依据任务的设定。然而,这种直接方法可能会产生与进化目标无关的解决方案,导致次优的进化。因此,解决方案进化使用不同策略来解决任务并通过确保解决方案的相关性和信息性来增强LLM的能力。
通过这些策略和方法,LLM能够有效地获取新经验,并为后续的精炼和更新阶段打下坚实的基础。
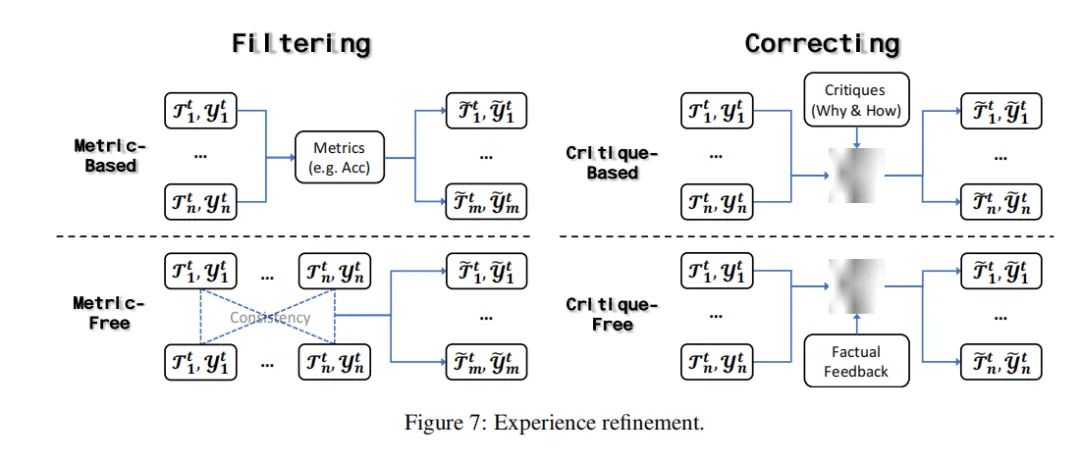
经验精炼的技术和实践
在大型语言模型(LLM)的自我演化过程中,经验精炼是至关重要的一环。这一阶段,模型通过筛选和修正初步获得的经验,提高数据的质量和可靠性,从而更好地适应新信息和环境,无需依赖外部资源。
1. 经验筛选
经验筛选分为基于指标的筛选和非基于指标的筛选两种主要策略。基于指标的筛选依赖于外部评价标准来评估和筛选输出,确保只有最可靠和高质量的数据被用于后续的模型更新。例如,ReSTEM项目通过正确性的二元奖励函数来筛选数据集,而AutoAct项目则利用F1分数和准确率作为奖励来收集正确的答案。
非基于指标的筛选则更加灵活,通常涉及对输出进行抽样,并基于模型内在的一致性标准或其他标准进行评估。例如,Self-Consistency项目通过多个生成的推理路径的一致性来筛选最终答案,高一致性表明高可靠性。
2. 经验修正
经验修正的方法可以分为基于批评的修正和非基于批评的修正。基于批评的修正依赖于额外的评判过程来获取经验的批评,然后根据这些批评来修正经验。例如,Self-Refine项目允许模型在没有额外训练的情况下,根据自我反馈迭代地修正其输出。
非基于批评的修正方法直接利用客观信息来修正经验,这种方法的优势在于它不依赖于可能引入偏见的详细反馈。例如,STaR项目通过迭代生成理由来回答问题,如果答案错误,则提示模型用正确答案生成更有信息量的理由。
模型更新的新策略
模型更新是自我演化过程中的关键阶段,通过利用精炼后的经验来提升模型性能。更新方法主要分为权重内更新和上下文内更新。
1. 权重内更新
权重内更新涉及到模型权重的调整,是传统训练范式的一部分,包括持续预训练、监督微调等。在自我演化的迭代训练过程中,关键挑战在于如何在保留原有技能的同时获得新能力。解决这一挑战的策略包括重放基础、正则化和合并方法。例如,AMIE项目通过自我对弈模拟学习环境进行迭代改进,并通过内部和外部自我对弈循环混合生成的对话和监督微调数据。
2. 上下文内更新
上下文内更新利用外部或工作记忆来学习经验,使模型能够在不进行昂贵训练的情况下快速适应。例如,MemoryBank项目通过插入、反思和遗忘操作更新外部记忆,存储过去的经验和反思出的规则,帮助模型在不同任务和环境中提高性能和适应性。

通过这些先进的经验精炼技术和模型更新策略,LLMs能够更有效地适应新环境和挑战,推动自我演化的研究和应用向前发展。
性能评估与未来方向
1. 性能评估
性能评估是自我演化大型语言模型(LLMs)发展中的关键环节,它不仅衡量模型当前的能力,还为未来的学习提供方向。评估方法可以分为定量和定性两种。
定量评估主要依赖于可量化的指标,如自动评估和人工评估。然而,传统的自动评估指标往往难以准确评估越来越复杂的任务,而人工评估并不适合自动自我演化的场景。最近的趋势是使用LLMs作为自动评估者,这种方法成本效益高且可扩展,例如使用奖励模型分数来衡量模型或任务的表现。
定性评估涉及案例研究和分析,以提供更深入的见解,帮助模型在后续迭代中更好地自我调整。例如,通过模型自我批评的方式来探讨模型输出的优势和不足,从而为未来的演化提供指导。
2. 未来方向
未来的研究方向主要集中在以下几个关键领域:
2.1 目标的多样性和层次性
目前的演化目标尚不能满足广泛的人类需求。未来的研究需要开发能够全面解决真实世界任务的自我演化框架,这可能涉及将演化目标分解为更易管理的子目标,并分别追求这些子目标。
2.2 自主性的层次
自我演化的自主性分为低、中、高三个层次。目前大多数研究处于低层次,需要人为设计演化过程。中层次和高层次的自我演化框架能够减少对专家的依赖,使LLMs能够根据目标自主演化,这是未来研究的重要方向。
2.3 经验获取与精炼
尽管LLMs能够自我改进或纠正输出,但其背后的机制尚不明确。此外,使用自生成数据进行学习可能会降低语言多样性并导致模型崩溃。未来的研究需要在理论上更深入探讨这些问题,以确保模型能够有效地学习和改进。
2.4 更新:稳定性-可塑性困境
在迭代自我演化过程中,如何平衡保留已学习信息的需要与适应新数据或任务的需求,是一个关键挑战。寻找在获取新技能和保留现有知识之间的平衡,对于实现有效和高效的自我演化至关重要。
2.5 安全性和超级对齐
随着LLMs的发展,确保这些模型与人类价值观和偏好保持一致至关重要,特别是在它们可能达到或超过专家级能力的情况下。开发可扩展的训练方法、验证模型对齐以及通过对抗测试来检验对齐过程的健壮性,是未来研究的重要方向。
总结
本文全面回顾了自我演化大型语言模型(LLMs)的发展,从早期的训练范式到当前的自我演化方法。通过详细介绍经验获取、精炼、更新和评估的迭代周期,本文不仅展示了LLMs在自主学习和改进方面的潜力,还突出了面向未来研究的挑战和方向。这些研究方向包括目标的多样性和层次性、自主性的层次、经验的获取与精炼、更新的稳定性-可塑性困境以及系统性的评估方法。通过解决这些挑战,未来的LLMs将能够更有效地适应复杂的真实世界任务,从而在智能系统的发展中迈出重要一步。
这篇关于阿里巴巴最新研究突破:自我演化大模型,打破性能天花板的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







