本文主要是介绍开源模型应用落地-LangSmith试炼-入门初体验-数据集评估(三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
LangSmith是一个用于构建生产级 LLM 应用程序的平台,它提供了调试、测试、评估和监控基于任何 LLM 框架构建的链和智能代理的功能,并能与LangChain无缝集成。通过使用LangSmith帮助开发者深入了解模型在不同场景下的表现,让开发者能够更高效地进行模型相关的开发、调试和管理。
本篇将学习 Evaluate 功能,主要用于评估和衡量在多样化数据上的性能和完整性。它提供了集成的评估和追踪框架,允许用户检查回归问题、比较系统,并轻松识别和修复错误来源及性能问题。
二、术语
2.1.LangChain
是一个全方位的、基于大语言模型这种预测能力的应用开发工具。LangChain的预构建链功能,就像乐高积木一样,无论你是新手还是经验丰富的开发者,都可以选择适合自己的部分快速构建项目。对于希望进行更深入工作的开发者,LangChain提供的模块化组件则允许你根据自己的需求定制和创建应用中的功能链条。
LangChain本质上就是对各种大模型提供的API的套壳,是为了方便我们使用这些 API,搭建起来的一些框架、模块和接口。
LangChain的主要特性:
1.可以连接多种数据源,比如网页链接、本地PDF文件、向量数据库等
2.允许语言模型与其环境交互
3.封装了Model I/O(输入/输出)、Retrieval(检索器)、Memory(记忆)、Agents(决策和调度)等核心组件
4.可以使用链的方式组装这些组件,以便最好地完成特定用例。
5.围绕以上设计原则,LangChain解决了现在开发人工智能应用的一些切实痛点。
2.2.LangSmith
是一个用于构建生产级 LLM 应用程序的平台,它提供了调试、测试、评估和监控基于任何 LLM 框架构建的链和智能代理的功能,并能与 LangChain 无缝集成。其主要作用包括:
- 调试与测试:通过记录langchain构建的大模型应用的中间过程,开发者可以更好地调整提示词等中间过程,优化模型响应。
- 评估应用效果:langsmith可以量化评估基于大模型的系统的效果,帮助开发者发现潜在问题并进行优化。
- 监控应用性能:实时监控应用程序的运行情况,及时发现异常和错误,确保其稳定性和可靠性。
- 数据管理与分析:对大语言模型此次的运行的输入与输出进行存储和分析,以便开发者更好地理解模型行为和优化应用。
- 团队协作:支持团队成员之间的协作,方便共享和讨论提示模板等。
- 可扩展性与维护性:设计时考虑了应用程序的可扩展性和长期维护,允许开发者构建可成长的系统。
2.3.LangChain和LangSmith的关系
LangSmith是LangChain的一个子产品,是一个大模型应用开发平台。它提供了从原型到生产的全流程工具和服务,帮助开发者构建、测试、评估和监控基于LangChain或其他 LLM 框架的应用程序。
LangSmith与LangChain 的关系可以概括为:LangChain是一个开源集成开发框架,而 LangSmith是基于LangChain 构建的一个用于大模型应用开发的平台。
三、前提条件
3.1.安装虚拟环境
conda create --name langsmith python=3.10
conda activate langsmith
pip install -U langsmith -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple3.2.创建API key
操作入口:LangSmithhttps://smith.langchain.com/settings未登录的需要先进行登录:
登录成功:
点击Settings:
点击Create API Key:
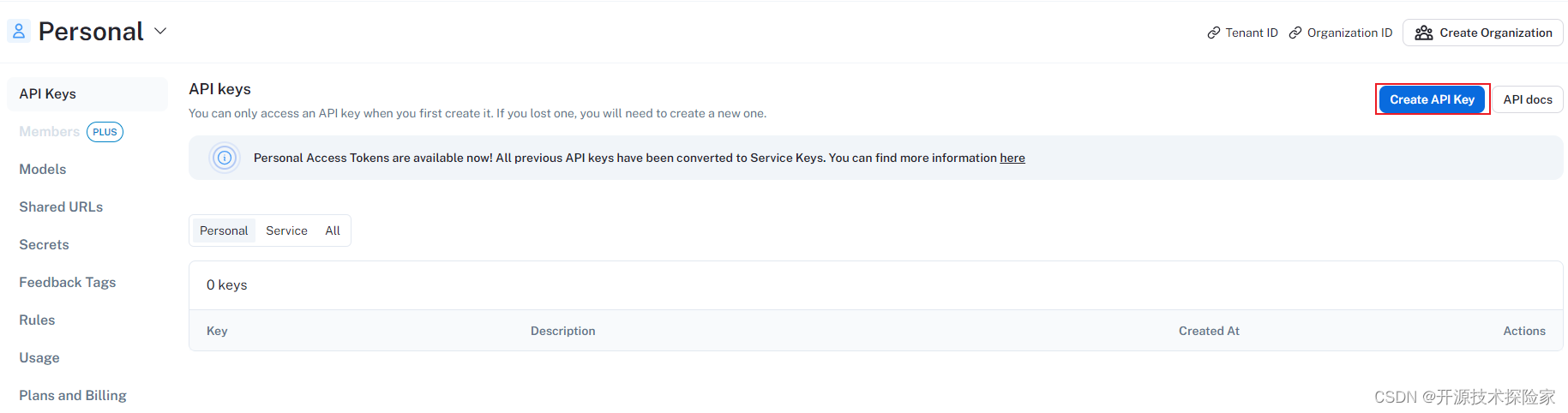
记录API Key:
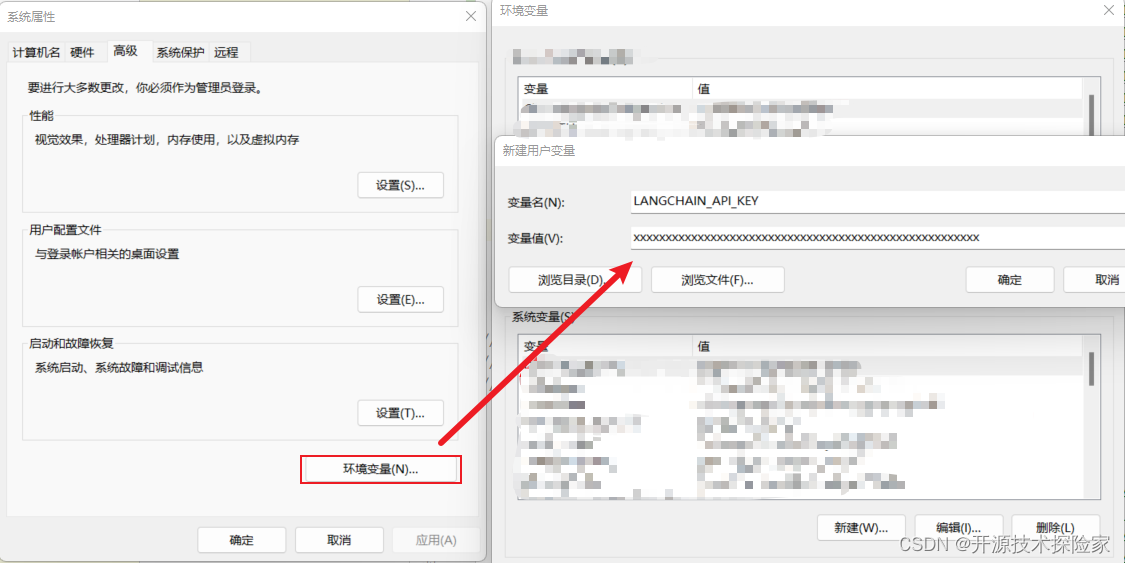
3.3.设置环境变量
windows:
linux:
export LANGCHAIN_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxps:
1.需要替换3.2创建的API Key
3.4.生成样例数据
建议使用GPT去生成,例如:输入“请生成10条酒店的评论,需要包含好评和差评的标识,数据以JSON格式返回,具体参见示例:{"comment":"这个酒店设施太老旧,房间有异味,下次都不来了","reviews":"差评"}”
[
{
"comment": "这家酒店环境很好,交通便利,服务员非常友好,下次还会来!",
"reviews": "好评"
},
{
"comment": "房间虽小但很干净整洁,性价比很高,下次还会选择这里。",
"reviews": "好评"
},
{
"comment": "酒店的游泳池和健身房设施一流,住宿体验非常棒,下次有机会一定再来。",
"reviews": "好评"
},
{
"comment": "早餐种类很丰富,味道也不错,服务态度很好,对得起这个价格。",
"reviews": "好评"
},
{
"comment": "酒店位置非常优越,临近著名景点,出行非常方便,下次有机会一定会再入住。",
"reviews": "好评"
},
{
"comment": "房间设施有些陈旧,卫生情况一般,不太符合我的预期,下次不会再选择这里。",
"reviews": "差评"
},
{
"comment": "服务员的态度不太友好,办理入住和退房的效率也比较低下,不太满意。",
"reviews": "差评"
},
{
"comment": "酒店停车场收费很高,且位置不太好找,感觉性价比不太高,不会再来了。",
"reviews": "差评"
},
{
"comment": "房间隔音效果很差,能听到走廊和邻居的声音,影响睡眠质量,希望能够改进。",
"reviews": "差评"
},
{
"comment": "酒店餐厅的菜品种类和口味都一般,性价比不高,下次不会再选择这里。",
"reviews": "差评"
}
]四、技术实现
4.1.准备数据集
# -*- coding = utf-8 -*-
import osfrom langsmith import Client
from langsmith import schemas as ls_schemasos.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_API_KEY'] = 'lsv2_pt_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'if __name__ == '__main__':# 初始化数据from langsmith import Clientfrom langsmith import schemas as ls_schemasclient = Client()# Create a datasetexamples = [{"comment": "这家酒店环境很好,交通便利,服务员非常友好,下次还会来!","reviews": "好评"},{"comment": "房间虽小但很干净整洁,性价比很高,下次还会选择这里。","reviews": "好评"},{"comment": "酒店的游泳池和健身房设施一流,住宿体验非常棒,下次有机会一定再来。","reviews": "好评"},{"comment": "早餐种类很丰富,味道也不错,服务态度很好,对得起这个价格。","reviews": "好评"},{"comment": "酒店位置非常优越,临近著名景点,出行非常方便,下次有机会一定会再入住。","reviews": "好评"},{"comment": "房间设施有些陈旧,卫生情况一般,不太符合我的预期,下次不会再选择这里。","reviews": "差评"},{"comment": "服务员的态度不太友好,办理入住和退房的效率也比较低下,不太满意。","reviews": "差评"},{"comment": "酒店停车场收费很高,且位置不太好找,感觉性价比不太高,不会再来了。","reviews": "差评"},{"comment": "房间隔音效果很差,能听到走廊和邻居的声音,影响睡眠质量,希望能够改进。","reviews": "差评"},{"comment": "酒店餐厅的菜品种类和口味都一般,性价比不高,下次不会再选择这里。","reviews": "差评"}]dataset_name = "Comment Queries"dataset = client.create_dataset(dataset_name=dataset_name, data_type=ls_schemas.DataType.kv)inputs=[]outputs=[]for example in examples:inputs.append({'comment':example['comment']})outputs.append({'reviews':example['reviews']})client.create_examples(inputs=inputs, outputs=outputs, dataset_id=dataset.id)调用结果:

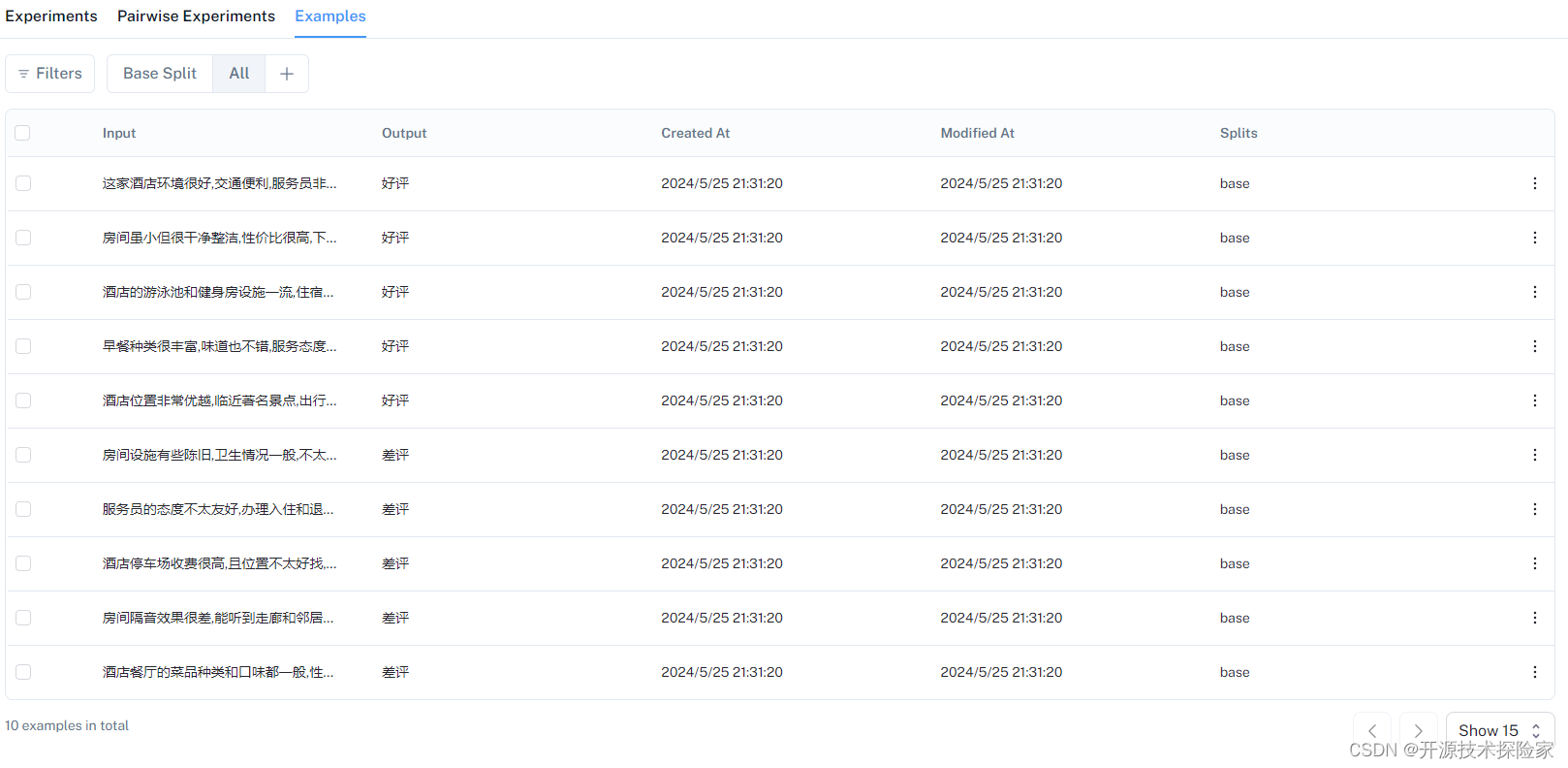
4.2.定义目标任务
openai = wrappers.wrap_openai(Client())@traceabledef label_text(text):messages = [{"role": "system","content": "请分析下面的用户评论,并确定它是积极还是消极。如果是积极,用“好评”回答,如果是消极,用“差评”回答。",},{"role": "user", "content": text},]result = openai.chat.completions.create(messages=messages, model="gpt-3.5-turbo", temperature=0)return result.choices[0].message.content4.3.配置评估器对输出进行评分,运行评估并查看结果
# 配置评估器对输出进行评分
def correct_label(root_run: Run, example: Example) -> dict:score = root_run.outputs.get("output") == example.outputs.get("reviews")return {"score": int(score), "key": "correct_label"}dataset_name = "Comment Queries"# 运行评估并查看结果
results = evaluate(lambda inputs: label_text(inputs["comment"]),data=dataset_name,evaluators=[correct_label],experiment_prefix="Comment Queries",description="Testing the baseline system.", # optional
)调用结果:
IDEA输出:

LangSmith 控制输出:
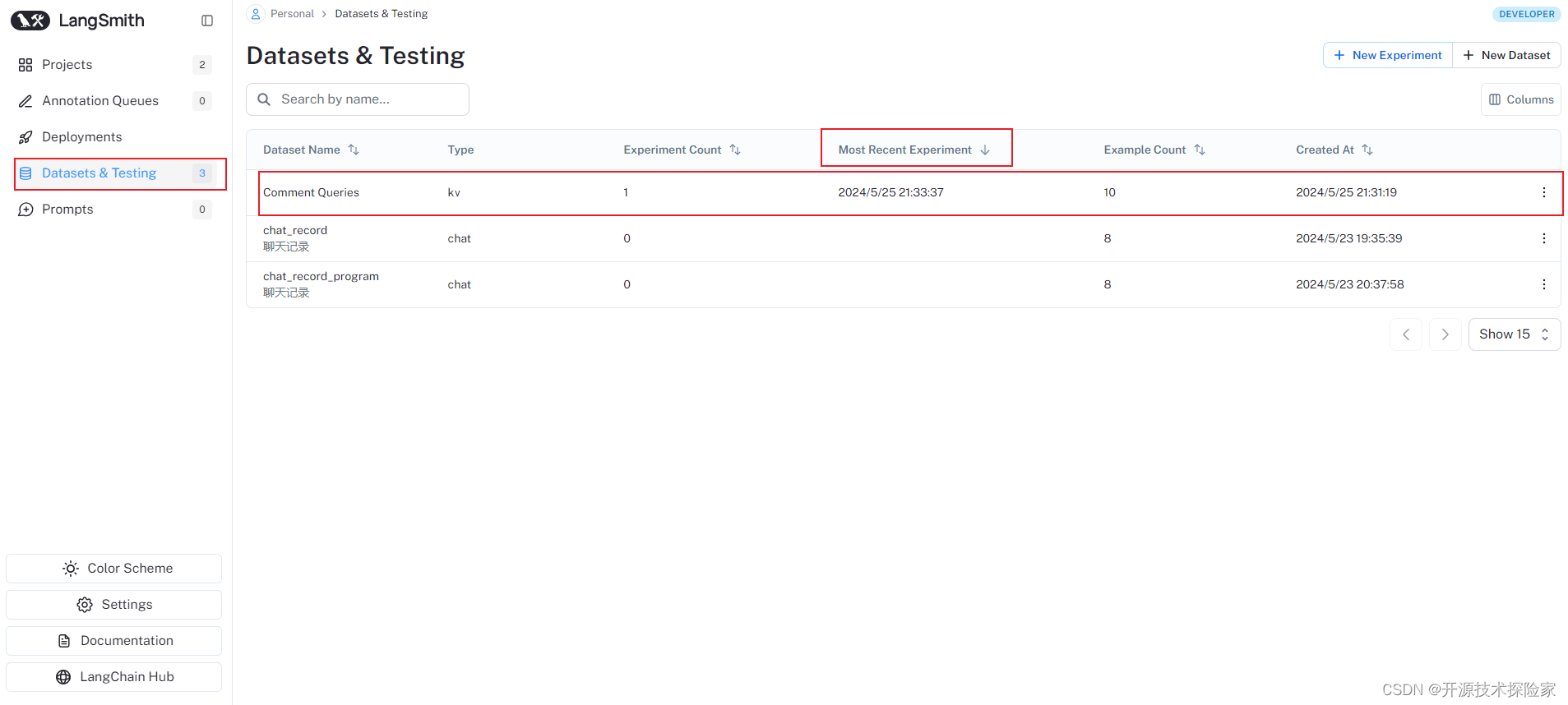
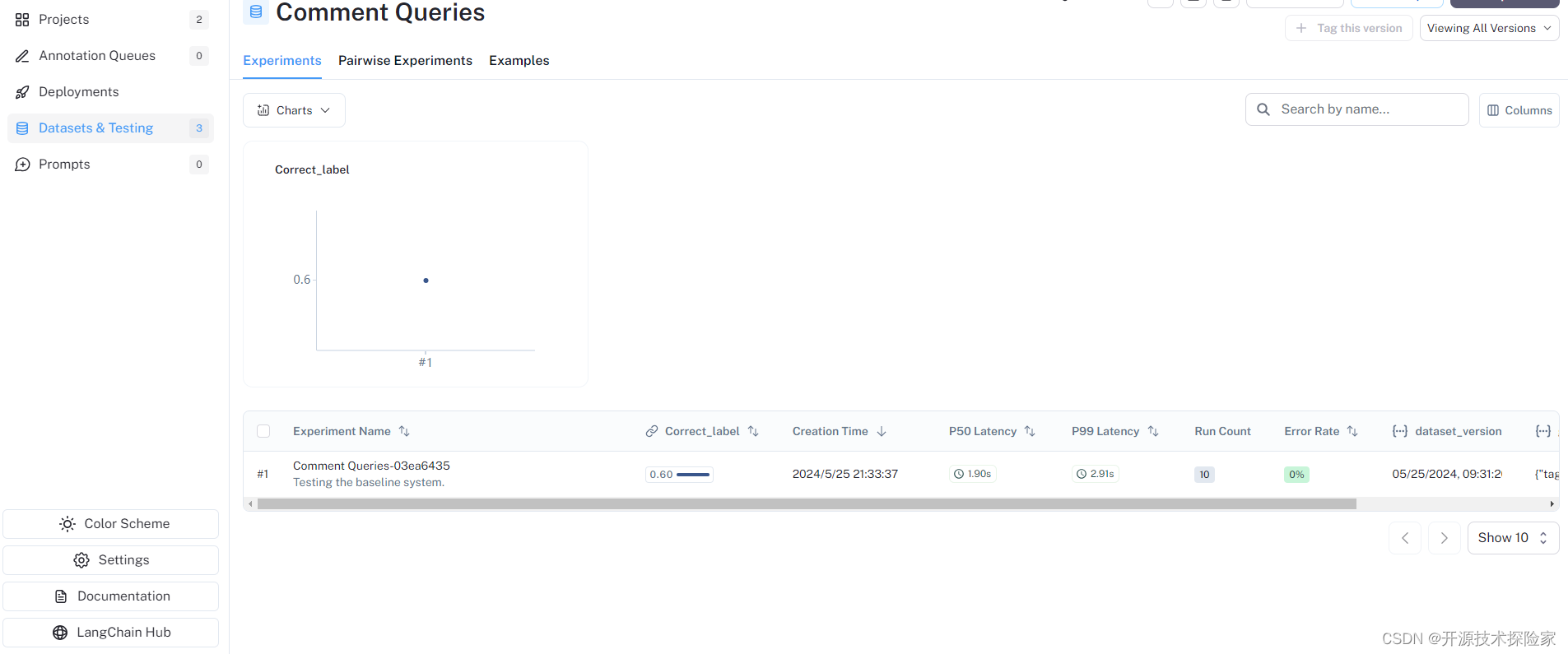
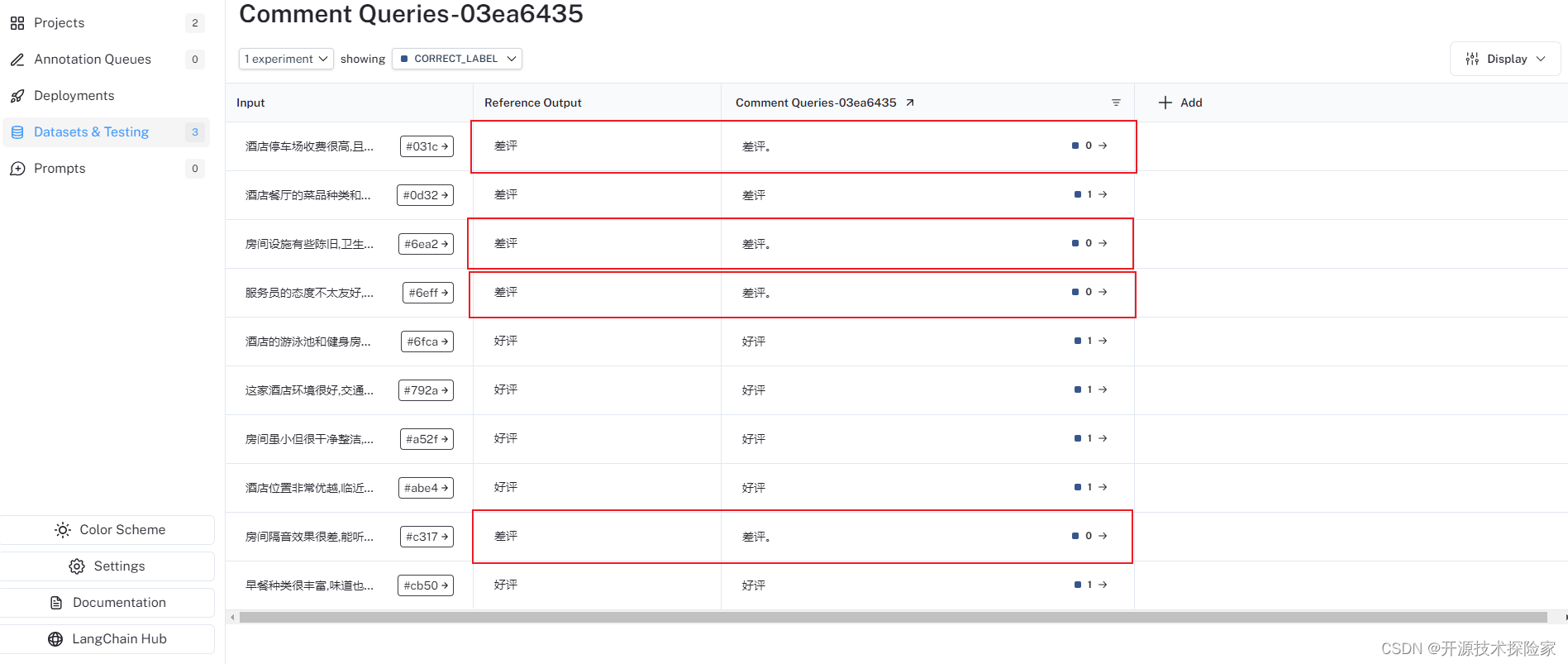
结论:
上面运行的10个样本数据中,有4个模型的输出结果跟预期不一致(期望输出“差评”,实际输出“差评。”),所以正确率为60%。
4.4.代码优化
在上一步评估测试后,正确率只有60%,接下来,尝试优化代码,再次进行评估。
我们修改System Prompt,改为:“请分析下面的用户评论,并确定它是积极还是消极。如果是积极,只需要回答“好评”两字,如果是消极,只需要回答“差评”两字。”
@traceable
def label_text(text):messages = [{"role": "system","content": "请分析下面的用户评论,并确定它是积极还是消极。如果是积极,只需要回答“好评”两字,如果是消极,只需要回答“差评”两字。",},{"role": "user", "content": text},]result = openai.chat.completions.create(messages=messages, model="gpt-3.5-turbo", temperature=0)return result.choices[0].message.content调用结果:
IDEA输出:

LangSmith 控制输出:
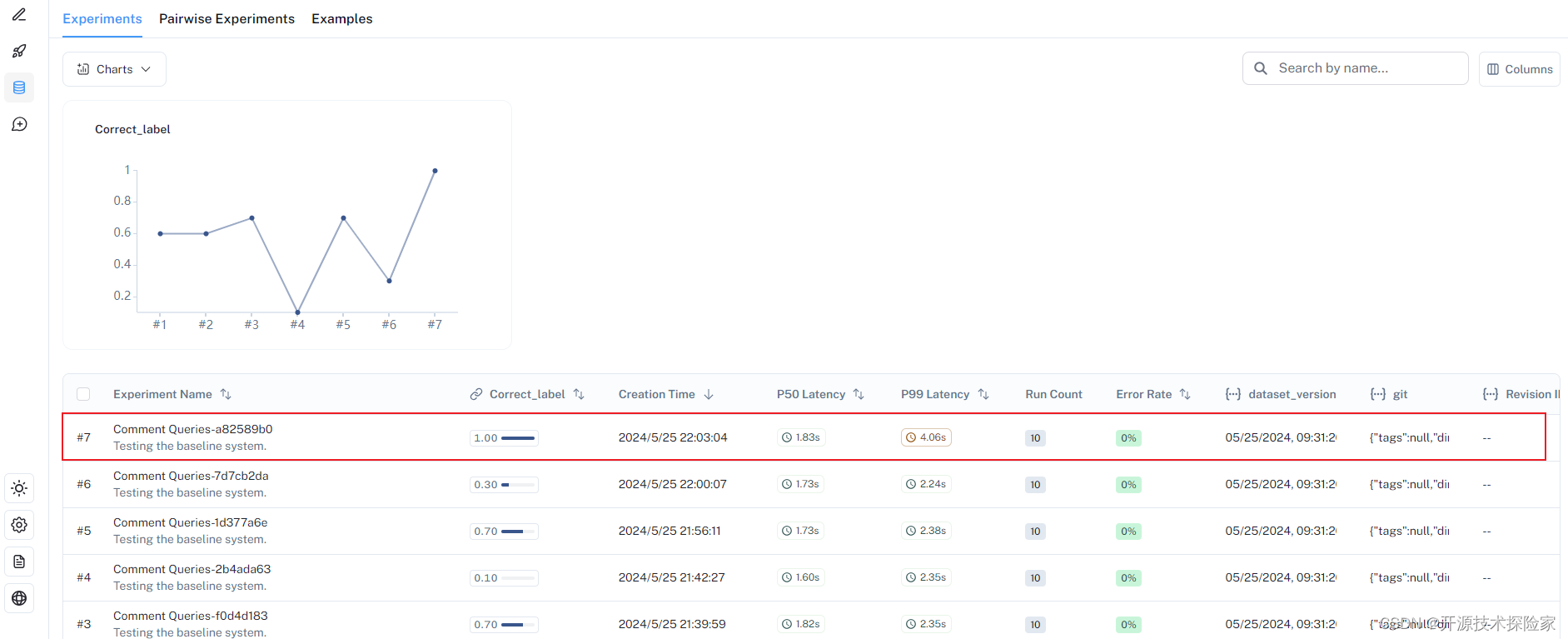
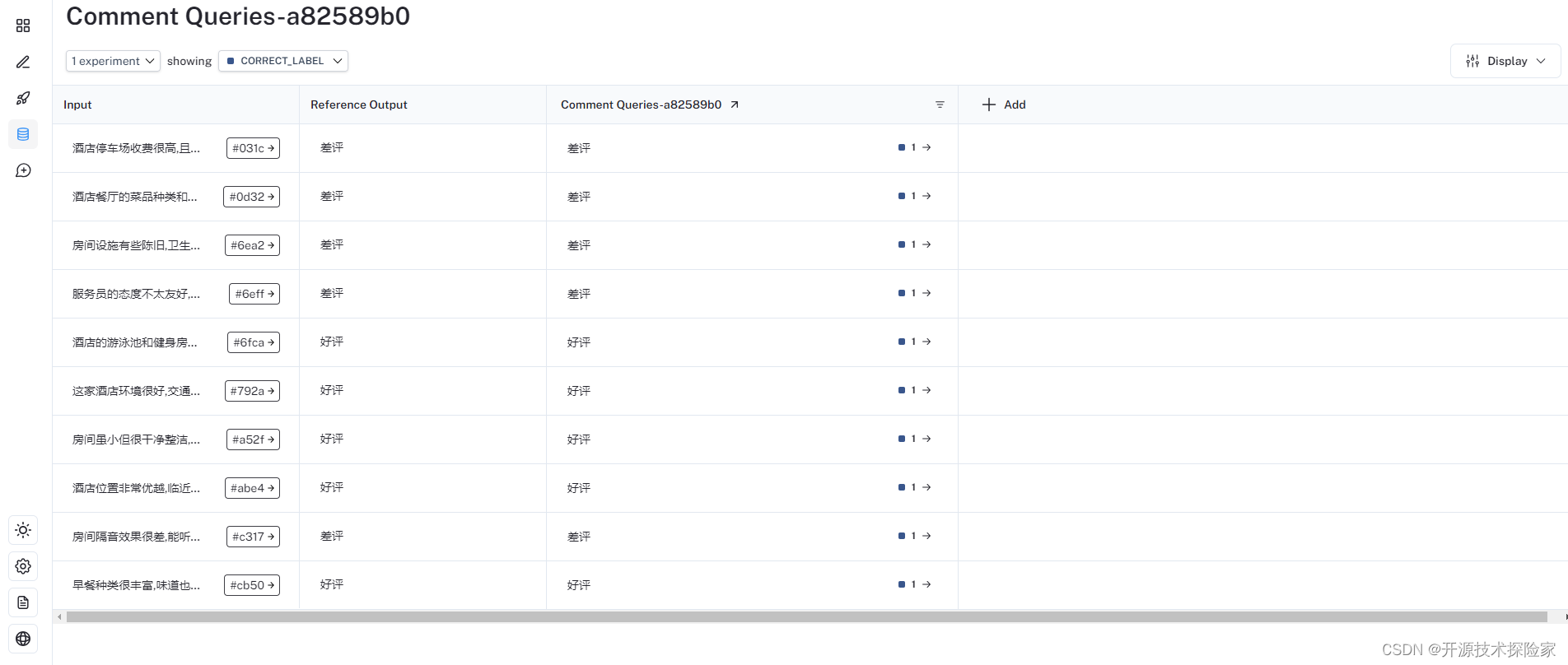
结论:
上面运行的10个样本数据中,所有输出结果跟预期一致,准确率100%。
五、附带说明
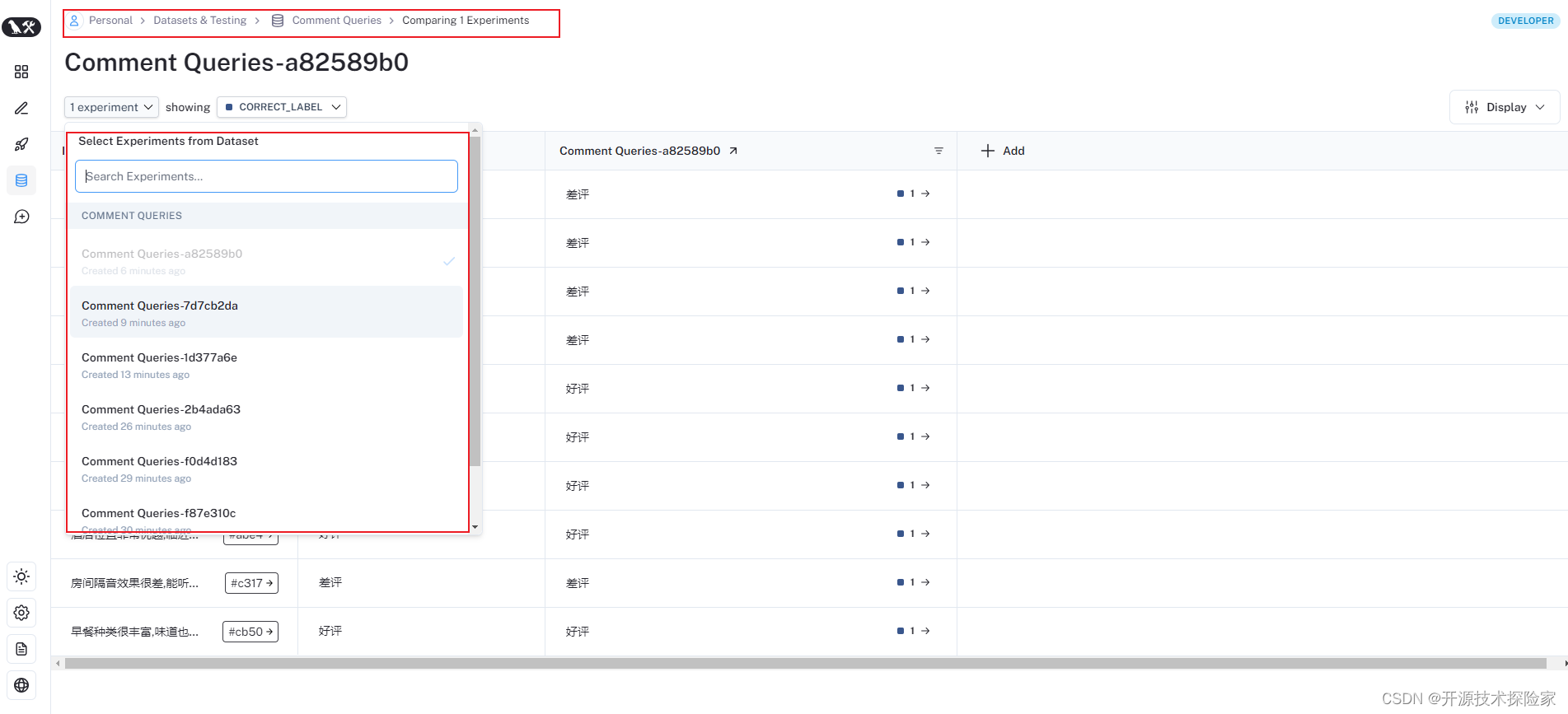
5.1. 如何查看数据下不同的实验结果
5.2. 数据集备选方案
除了按照4.1.准备数据集以外,还可以选用已有的数据集,具体参见:
开源模型应用落地-LangSmith试炼-入门初体验-数据集管理(二)-CSDN博客
5.3. 完整代码
# -*- coding = utf-8 -*-
import os
from langsmith import wrappers, traceable
from langsmith.schemas import Example, Run
from langsmith.evaluation import evaluate
from openai import Clientos.environ["OPENAI_API_KEY"] = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_API_KEY'] = 'lsv2_pt_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'if __name__ == '__main__':# 初始化数据# from langsmith import Client# from langsmith import schemas as ls_schemas# client = Client()## # Create a dataset# examples = [# {# "comment": "房间宽敞明亮,设施很新,服务态度也很好,下次还会来!",# "reviews": "positive"# },# {# "comment": "我预定的房间竟然被打包了,前台也没有解决,太令人失望了。",# "reviews": "negative"# },# {# "comment": "游泳池很干净,健身房设施齐全,总的来说是个不错的酒店。",# "reviews": "positive"# },# {# "comment": "房间有些陈旧,床垫也有些许问题,不太舒服。",# "reviews": "negative"# },# {# "comment": "酒店位置很好,离市中心很近,交通很方便,值得推荐。",# "reviews": "positive"# },# {# "comment": "我订的双人间竟然只给安排了单人房,太不专业了。",# "reviews": "negative"# },# {# "comment": "餐厅的菜品很丰富,味道不错,早餐种类也很多,很满意。",# "reviews": "positive"# },# {# "comment": "酒店走廊一直有一股怪味,让人感觉不太干净。",# "reviews": "negative"# },# {# "comment": "前台服务人员很热情友好,贴心解决了我的问题,很满意。",# "reviews": "positive"# },# {# "comment": "这个酒店隔音效果太差,晚上睡觉都会被吵醒。",# "reviews": "negative"# }# ]## dataset_name = "Comment Queries"# dataset = client.create_dataset(dataset_name=dataset_name, data_type=ls_schemas.DataType.kv)## inputs=[]# outputs=[]# for example in examples:# inputs.append({'comment':example['comment']})# outputs.append({'reviews':example['reviews']})## client.create_examples(inputs=inputs, outputs=outputs, dataset_id=dataset.id)openai = wrappers.wrap_openai(Client())@traceabledef label_text(text):messages = [{"role": "system","content": "请分析下面的用户评论,并确定它是正面评价还是负面评价。如果是正面评价,用“positive”回答,如果是负面评价,用“negative”回答。",},{"role": "user", "content": text},]result = openai.chat.completions.create(messages=messages, model="gpt-3.5-turbo", temperature=0)return result.choices[0].message.contentdef correct_label(root_run: Run, example: Example) -> dict:score = root_run.outputs.get("output") == example.outputs.get("reviews")return {"score": int(score), "key": "correct_label"}dataset_name = "Comment Queries"results = evaluate(lambda inputs: label_text(inputs["comment"]),data=dataset_name,evaluators=[correct_label],experiment_prefix="Comment Queries",description="Testing the baseline system.", # optional)这篇关于开源模型应用落地-LangSmith试炼-入门初体验-数据集评估(三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









