本文主要是介绍AI原生嵌入式矢量模型数据库ChromaDB-部署与使用指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在人工智能大模型领域, 离不开NLP技术,在NLP中词向量是一种基本元素,如何存储这些元素呢? 可以使用向量数据库ChromeDB

Chroma
Chroma 是 AI 原生开源矢量数据库。Chroma 通过为 LLM 提供知识、事实和技能,使构建 LLM 应用程序变得容易。同时也是实现大模型RAG技术方案的一种有效工具。
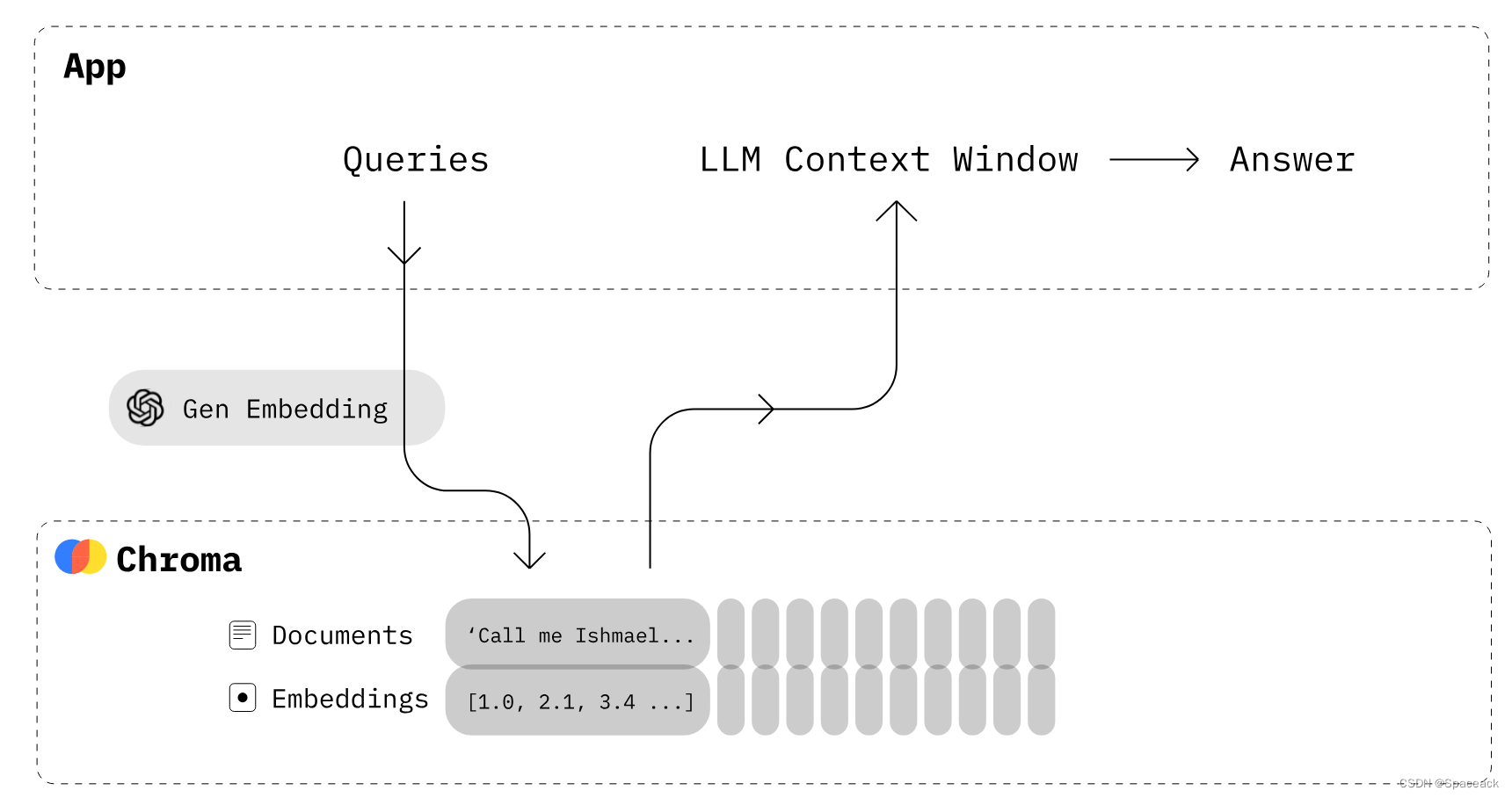
简介
-
Chrome提供以下能力:
- 存储嵌入类型数据(embeddings)和其元数据
- 嵌入(embed)文档和查询
- 对嵌入类型的检索
-
Chrome 的原则:
- 对用户的简单性,并保障开发效率
- 同时拥有较好的性能
-
Chroma 作为服务器运行,同时提供客户端的SDK(支持Java, Go,Python, Rust等多种语言)。
安装与运行
- 首先要确保有安装有
Python运行环境 - 安装
Chroma模块pip install chromadb - 创建数据库存储目录
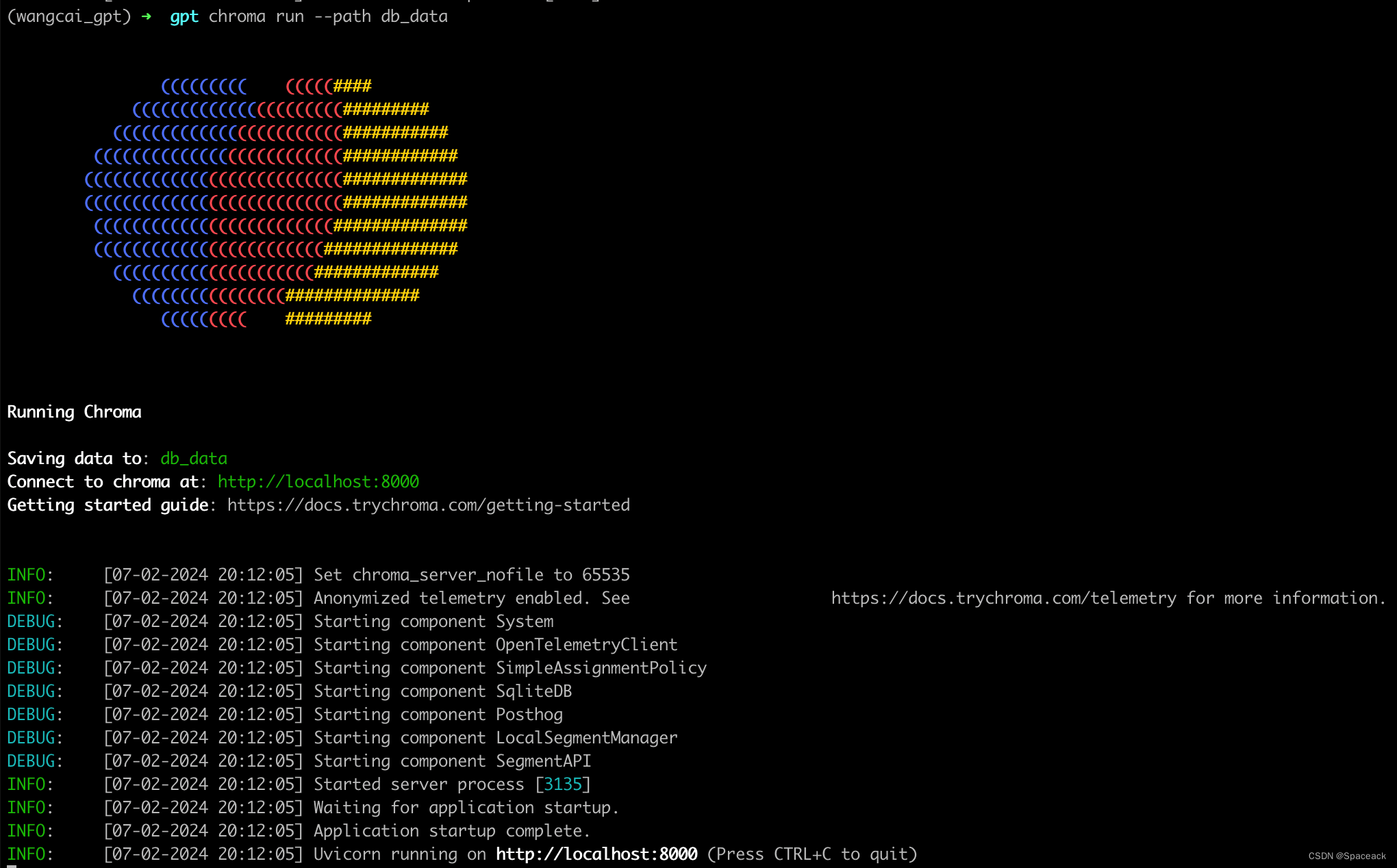
mkdir db_data - 运行
Chroma服务并指定路径chroma run --path db_data
如图所示,Chroma服务就成功启动啦!😄
将Chroma作为服务常态化运行
将chromadb.service配置文件放在/etc/systemd/system/目录并用命令systemctl start chromadb启动服务即可。
附赠一份配置模板,具体参数按实际情况配置即可。
[Unit]
Description=ChromaDB Service
After=network-online.target[Service]
ExecStart=/root/anachonda3/bin/chroma run --path /chromadb/db_data
User=root
Group=root
Restart=always
RestartSec=3
export CHROMA_SERVER_HOST=127.0.0.1
Environment=CHROMA_SERVER_HTTP_PORT=8881
ANONYMIZED_TELEMETRY=False
[Install]
WantedBy=default.target
Python客户端使用指南
- 导入模块并创建数据库连接
import chromadb chroma_client = chromadb.Client() # chroma_client = chromadb.HttpClient(host='localhost', port=8000) - 创建数据库
集合(collection)
因为collection = chroma_client.create_collection(name="my_collection") #chroma_client = chromadb.PersistentClient(path="/path/to/save/to") # 设置持久化路径Chroma在 url 中使用集合名称,因此命名有一些限制:- 名称的长度必须介于 3 到 63 个字符之间。
- 名称必须以小写字母或数字开头和结尾,并且中间可以包含点、破折号和下划线。
- 名称不得包含两个连续的点。
- 名称不得是有效的 IP 地址。
- 集合的一些便捷方法
# 返回集合中前10项的一个列表
collection.peek()
# 返回集合中的项目个数
collection.count()
# 重命名集合
collection.modify(name="new_name")
- 添加
文档(documents)到集合(collection)中collection.add( embeddings=[[1.2, 2.3, 4.5], [6.7, 8.2, 9.2]], documents=["This is a document", "This is another document"], metadatas=[{"source": "my_source"}, {"source": "my_source"}], ids=["id1", "id2"] ) - 查询文档 n 个最相近的结果
results = collection.query( query_texts=["This is a query document"], n_results=2 ) - 便捷方法
chroma_client.heartbeat() # 纳秒级心跳,确保与服务端连接状态 chroma_client.reset() # 重置数据库,清除已有信息
查询集合
使用.query方法查询集合
collection.query(query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],n_results=10,where={"metadata_field": "is_equal_to_this"},where_document={"$contains":"search_string"}
)更新集合数据
使用.update方法更新集合
collection.update(ids=["id1", "id2", "id3", ...],embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],documents=["doc1", "doc2", "doc3", ...],
)
使用upsert更新数据,若不存在则新增。
collection.upsert(ids=["id1", "id2", "id3", ...],embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],documents=["doc1", "doc2", "doc3", ...],
)
从集合中删除数据
使用delete方法删除数据
collection.delete(ids=["id1", "id2", "id3",...],where={"chapter": "20"}
)
总结
通过这次学习,了解到了使用ChromeDB的基本方法,真是太好啦。

欢迎关注 公-众-号【编程之舞】,获取更多技术资源。

这篇关于AI原生嵌入式矢量模型数据库ChromaDB-部署与使用指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





