本文主要是介绍大模型的灵魂解读:Anthropic AI的Claude3 Sonnet可解释性研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于构建生产级别架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。
Anthropic的模型可解释性团队,一直想和大模型的灵魂交流,最近在研究Claude 3 Sonnet的内部的参数结构和工作原理时,获得十分有趣的结论。总所周知,大模型基于人工神经网络,里面的神经元的激活模式运用十分广泛。研究人员认为研究这些激活模式以及对应神经元的分布就可以大致的将神经网络的学习和掌握到的知识概念可视化。

研究思路
大模型理解一行诗词或者意境主要是基于线性表示假设和叠加假设。从更抽象以及更高维度上,线性表示假设表明神经网络将具有一定意义的知识概念表示为其激活空间(N维)中的方向。而叠加假设则在线性表示假设的基础上,并进一步提出了神经网络是利用高维空间中的各种方向(几乎正交的向量)的叠加来表示比N维数量更多的特征。这两种假设的前提下诞生了一种研究标注方法就是字典学习(Dictionary learning)。
有论文表明这种解释对于Transformer语言模型来说非常有效,例如一种称为稀疏自动编码器就非常有效,它近似的等同于字典学习。
稀疏自动编码器在标准自动编码器的基础上增加了稀疏性约束。稀疏性约束通过在隐藏层中引入额外的惩罚项,限制隐藏单元的激活数量,使得大多数隐藏单元的激活值接近零。
假设有一个简单的稀疏自动编码器,输入层有4个单元,隐藏层有3个单元,输出层有4个单元。目标是学习一个稀疏的3维隐藏层表示,同时稀疏性的约束让隐藏层的大多数单元的激活值接近零。
具体来说,研究人员使用了一种“字典学习”的技术。该技术主要是训练一个单独的神经网络B,以尽可能紧凑重建被研究模型某些特定层的激活场景。然后,网络B经过训练后,权重会形成一个激活模式的“词典”,称为特征。每个特征代表模型已学习的一个知识概念。
上面这段话的意思就是看下图,用一个稀疏的自动编码器将激活层进行分解,形成特征。分解成的特征比神经元的数量还多。这是因为MLP层可能使用叠加示比神经元更多的特征。事实上在最大的实验中,可以扩展到比神经元多256倍(131072)的特征。

换句话说,它利用大模型的激活值来训练一个类似等同的稀疏自动编码器,因为是稀疏自动编码器,所以可以比较直观的观察激活情况。注意下面的图表,它采集了mlp的激活值大约8B进行训练。


Sparse AutoEncoders(SAE)
本次研究人员使用的SAE是“稀疏字典学习”算法系列的一个实例,旨在将数据分解为稀疏的激活组件的加权和。
本次的SAE由两层组成,第一层(“编码器”)通过学习的线性变换和ReLU激活函数将输入映射到更高维度空间。我们将这个高维的层称为“特征(feature)”。第二层(“解码器”)尝试通过激活的“特征”的线性变换来重建模型激活。当然训练模型的过程是采用最小化重建误差和鼓励稀疏的“特征”激活为目标进行迭代训练。
一旦SAE 训练完成,它就会提供一个模型激活的近似分解,将其分解为“特征方向”(SAE解码器权重)的线性组合,其系数等于“特征”激活。稀疏性惩罚确保对于模型的许多给定输入,只有极小一部分特征具有非零激活。因此,对于任何给定上下文中的任何给定标记,模型激活都由一小部分活动特征(从大量可能特征中)“解释”。
本次训练三个不同大小SAE:1,048,576(~1M)、4,194,304(~4M)和 33,554,432(~34M)个特征。对于三个SAE,给定 token 上活跃的特征(即具有非零激活)的平均数量少于 300,并且 SAE 重构至少解释了模型激活方差的 65%。在训练结束时,1M SAE 的死特征比例约为 2%,4M SAE 为 35%,34M SAE 为 65%。

即较小SAE中的特征在较大SAE中“分裂”成多个特征的现象,这些特征在几何上接近且在语义上与原始特征相关,但表示更具体的概念。例如,1M SAE中的“旧金山”特征在4M SAE中分裂成两个特征,在34M SAE中分裂成11个细粒度特征。
除了特征分裂之外,还看到一些示例,其中较大的SAE包含一些特征,这些特征代表了较小的 SAE中的特征无法捕捉到的概念。例如,4M和34M SAE中有一组地震特征,在 1M SAE中没有类似的特征,而且最近的 1M SAE的特征似乎也没有任何关联。

示例:金门大桥
SAE提取的特征涵盖范围广泛,从知名的公众人物、地点、到程序代码中的句法元素,再到同情或讽刺等抽象概念。下面的示例特征展示了来自 SAE 数据集中前 20 个文本输入的代表性示例,按它们激活该特征的强度进行排序。单击特征ID 可以找到更大的随机采样激活集。突出显示的颜色表示每个标记的激活强度(白色:无激活,橙色:最强激活)。

聚焦金门大桥特征周围的一个小街区,会发现其中有与旧金山特定位置相对应的特征,例如恶魔岛和要塞。在更远的地方还看到相关程度降低的特征,例如与太浩湖、优胜美地国家公园和索拉诺县(靠近旧金山)相关的特征。在更远的距离,我们还看到以更抽象的方式相关的特征,例如与其他地区的旅游景点相对应的特征(例如“法国梅多克葡萄酒产区”;“苏格兰斯凯岛”)。总体而言,解码器空间中的距离似乎粗略地映射到概念空间中的相关性,通常是以有趣和意想不到的方式。

紧接着来看看金门大桥特征34M/31164353。其最大激活基本上是对大桥的所有引用,较弱的激活还包括相关的旅游景点、类似的桥梁和其他纪念碑。接下来,脑科学特征34M/9493533激活了神经科学书籍和课程以及认知科学、心理学和相关哲学的讨论。在 1M 训练运行中,我们还发现一个特征强烈激活了各种交通基础设施1M/3,包括火车、渡轮、隧道、桥梁甚至虫洞!最后一个特征1M/887839 响应了热门旅游景点,包括埃菲尔铁塔、比萨斜塔、金门大桥和西斯廷教堂。

X轴代表激活值,蓝色为不相关,红色为直接相关。虽然分析方法仅适用于文本数据,但许多特征对相应概念的文本提及和图像都很敏感。
研究人员发现了一个特征,它对提及金门大桥有特定的反应。当这个特征被人为地激活到最大值的十倍时,模型甚至开始将自己与这座大桥联系起来,并产生诸如“我是金门大桥,我将旧金山与马林县连接起来”这样的陈述。

免疫学特色1M/533737为中心,可以看到这个邻域内有几个不同的聚类。在图的顶部,可以看到一个聚类专注于免疫功能低下的人、免疫抑制、导致免疫功能受损的疾病等等。向下向左移动时,它转变为一个专注于特定疾病(感冒、流感、一般呼吸道疾病)的特征聚类,然后是与免疫反应相关的特征,然后是代表与免疫有关的器官系统的特征。相反,当从免疫功能低下的聚类向右向下移动时,可以看到更多与免疫系统的微观方面(例如免疫球蛋白)相对应的特征,然后是免疫学技术(例如疫苗)等等。
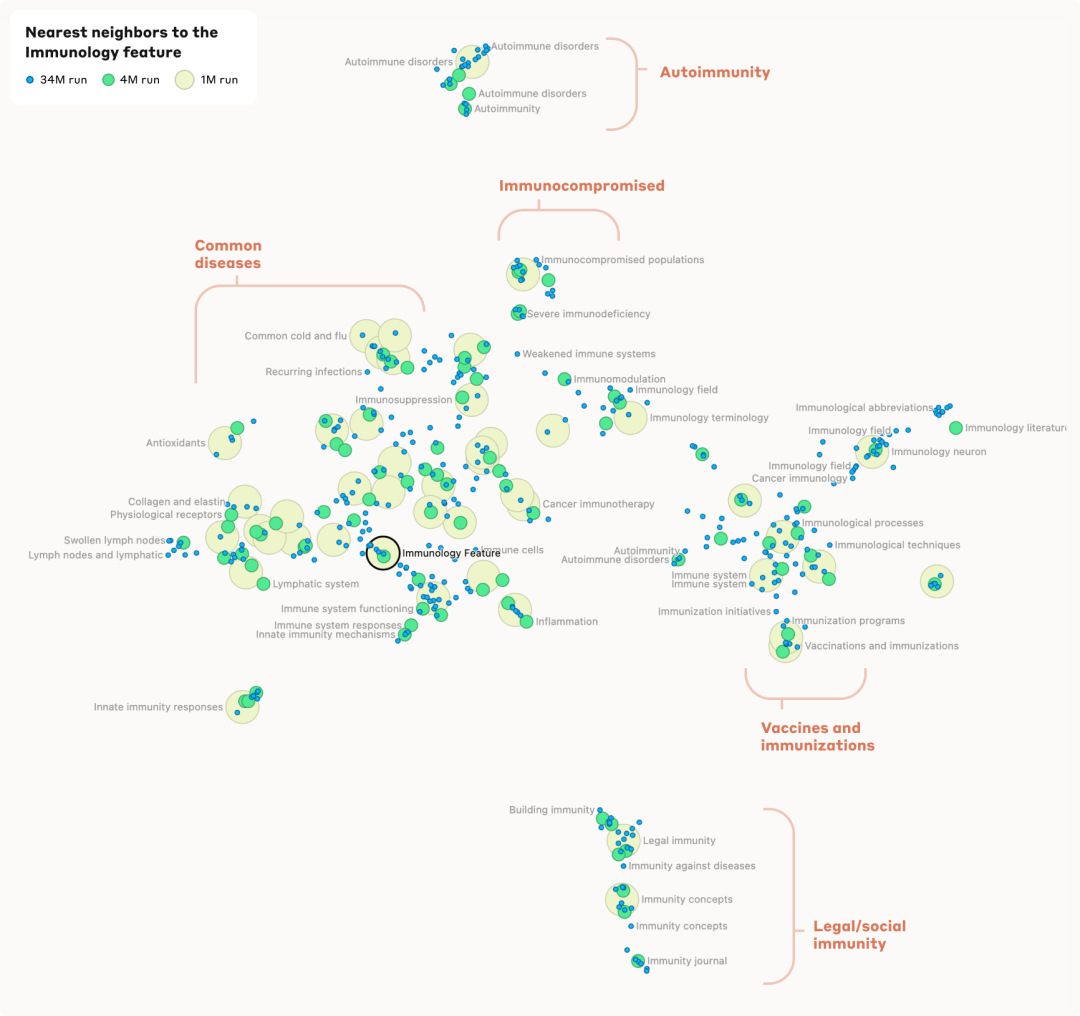
在最底部与其他部分截然不同,看到了一组与非医学背景(例如法律/社会)中的免疫相关的特征。
研究人员还发现了特征层次结构证据。例如在更详细分析时,一般特征“旧金山”会分解为针对单个地标和街区的几个更具体的特征。同样,国家特征(例如“加拿大”或“冰岛”)会分解为“地理”、“文化”和“政治”等子特征。
研究人员表示:“我们发现的特征仅代表模型在训练期间学习到的所有概念的一小部分,而使用我们当前的技术找到一整套特征的成本将非常高昂(我们当前方法所需的计算量将大大超过用于训练模型的计算量)。”
研究人员还发现了该模型的潜在问题特征。例如,有些特征对生物武器的开发、欺骗或操纵很敏感,可能会影响模型的行为。
论文指出,仅仅存在这些特征并不一定意味着模型(更)危险。然而,这表明需要更深入地了解这些特征何时以及如何被激活,然而打开大模型的黑匣子将可以帮助未来更好地理解语言模型。
这篇关于大模型的灵魂解读:Anthropic AI的Claude3 Sonnet可解释性研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







