本文主要是介绍clusterdata-2011-2 谷歌集群数据分析(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


1、每个测量周期是5分钟(300秒),这也能够佐证时间单位是微秒,因为表中每一行开始时间和结束时间数值相差为300000000。
2、第四个属性即 task index 属性是指将一个Job分成多个Task,对这些Task进行一个编号,一个Job下的多个Task在不同的机器上可以实现并行执行。
3、对于一个Job,可以是顺序执行,不再细分为多个Task ,如下图,Job ID 为6227108810的作业,task index 为0,一直在machine ID 为156767904 的机器上执行,看时间区间没有重叠,是顺序执行。

4、有的 Job 是并行执行,而且细分为多个Task ,如下图,Job ID 为6232112095的作业,task index 为0--49,说明分成了50个task来执行,分布在50个不同的machine ID 的机器上并行执行,并且在一个测量周期内(5700000000--6000000000)并没有执行完,在下一个周期(6000000000--6300000000)中继续50台机器并行执行。

5、有的Job是并行任务和顺序执行任务都包含,如下图,Job ID 为3418375的作业,task index 为0--1,在前几个个测量周期内(5700000000--7500000000)是并行执行,即分成两个任务同时运行,但是在后几个周期(7500000000--8100000000)中只是以一个任务的形式,在一台机器上顺序执行。这种情况应该是分的任务之间长度不一定相同,有的执行时间短,有的执行时间长,这种情形也证明了多余每个细分的 task 来说,只能是顺序执行,每个任务单元不能再分布式并行执行。

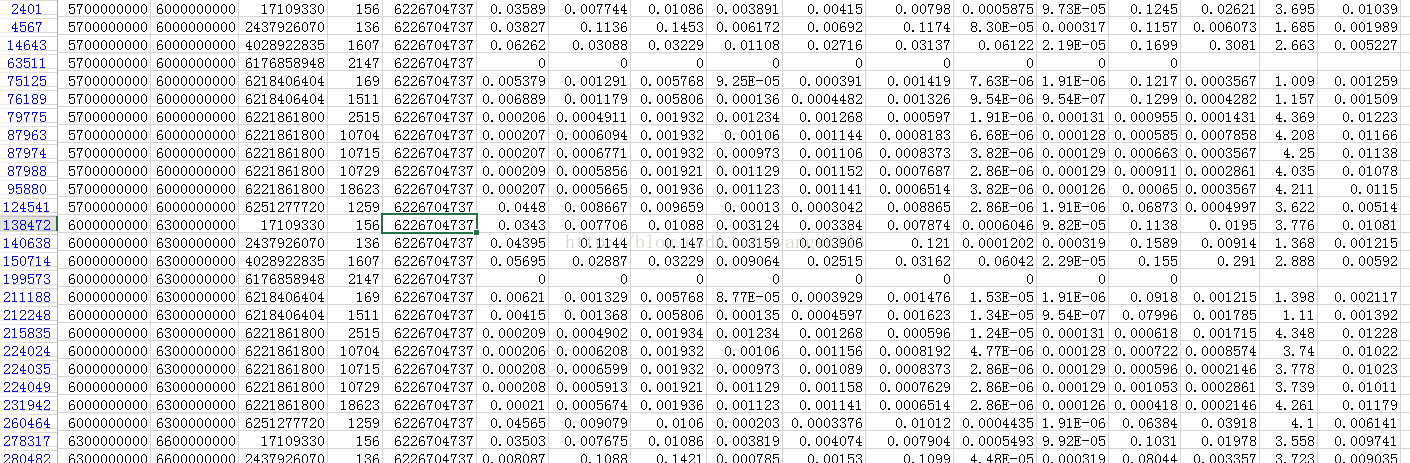
6、对于一个机器来说,在同一时间段可以执行多个不同的任务,这些任务可以来自不同的Job,也可以来自同一个Job,但是同一个任务在一个时间周期中只能执行一次,如下图,machine ID 为6226704737的机器,在一个测量周期中执行了来自12个不同 的task,这些task有的来自同一个Job ID(6221861800),但是同一个Job 下的同一个task(例如6221861800下的10704)在一个测量周期内只能执行一次,没执行完在下个周期继续执行。这里猜想同一时间段中对于不同的任务,应该采用了一些调度算法(类似时间片轮转调度算法),使得这些任务看起来是在一个时间段中并行执行,其实应该是顺序执行,因为就一台机器。
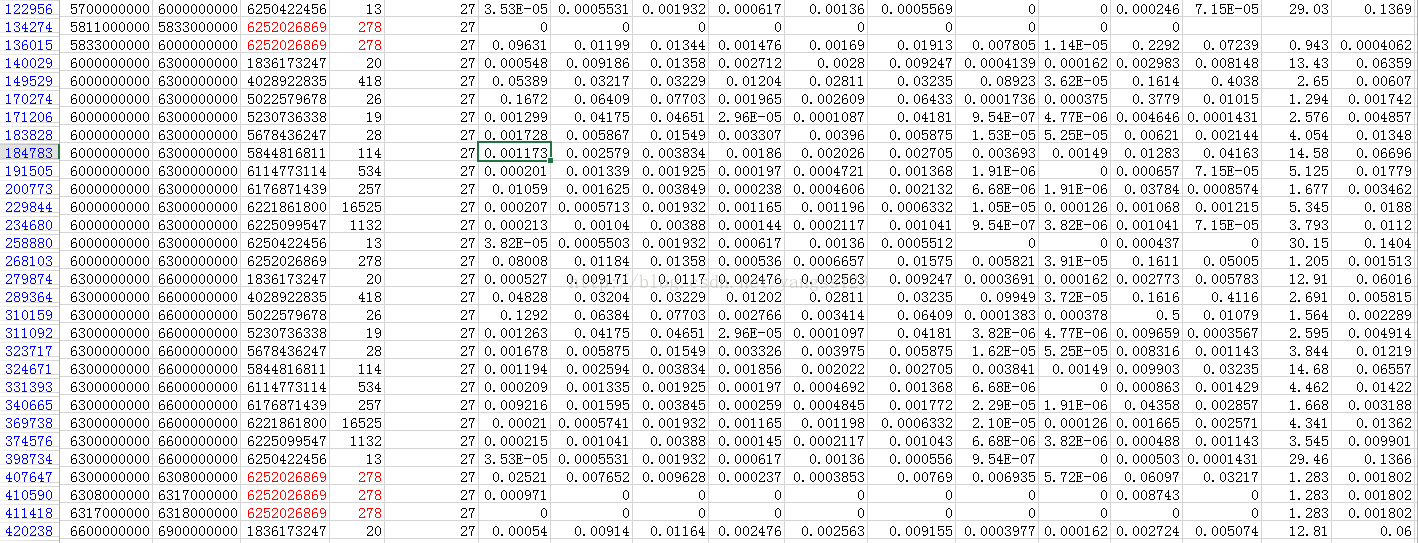
7、有的 task 也没有按照严格的测量周期来执行,如下图,machine ID 为27的机器,标红的五项为Job ID 为6252026869 下的task index 为278的任务,这个任务执行周期不是300秒,但是对于不规则的任务,他们还是顺序执行,这点也更加说明了task是最小单位,不能够再拆分成多个任务并行执行。
这篇关于clusterdata-2011-2 谷歌集群数据分析(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







