本文主要是介绍文科论文,使用AI写作时能够提供实证数据吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

人工智能时代,为了撰写论文提供思路及高效,利用AI撰写论文已是常态,可撰写文科论文通常研究中都需要实证数据,而AI撰写论文时能够提供这样的数据吗?
一、什么是实证数据
实证数据是指从研究报告、财务报表、新闻报道以及权威机构等渠道获取的各类真实数据,例如“国内生产总值(GDP)”、“贸易量”、“人口统计数据"等。这些数据可以用来支持或反驳某个观点。在文科领域,实证数据通常包括历史文献、统计数据、案例分析等,并具有客观性、可靠性和有效性等特点,因此在学术研究中具有重要意义。
二、实证数据在论文中的作用
1、增强论据的说服
实证数据可以为论文的观点提供有力的支持,使论证更加充分和有说服力。
2、提高研究的客观性
实证数据可以帮助研究者避免主观臆断,使研究结果更加客观和可靠。
3、拓展研究视野
实证数据可以帮助研究者发现新的研究问题和视角,从而拓展研究的视野。
4、促进学术交流
实证数据可以作为学术交流的基础,帮助研究者更好地理解和评价他人的研究成果。
三、AI生成包含实证数据论文
我们可以通过“AI导师写作”生成包含实证数据的文科论文,操作如下:
1、通过浏览器进入“AI导师写作”(www.daoshixiezuo.com)网页。
2、选择毕业论文或者期刊论文,并填写标题、学历、专业、字数等信息后,点击立即生成。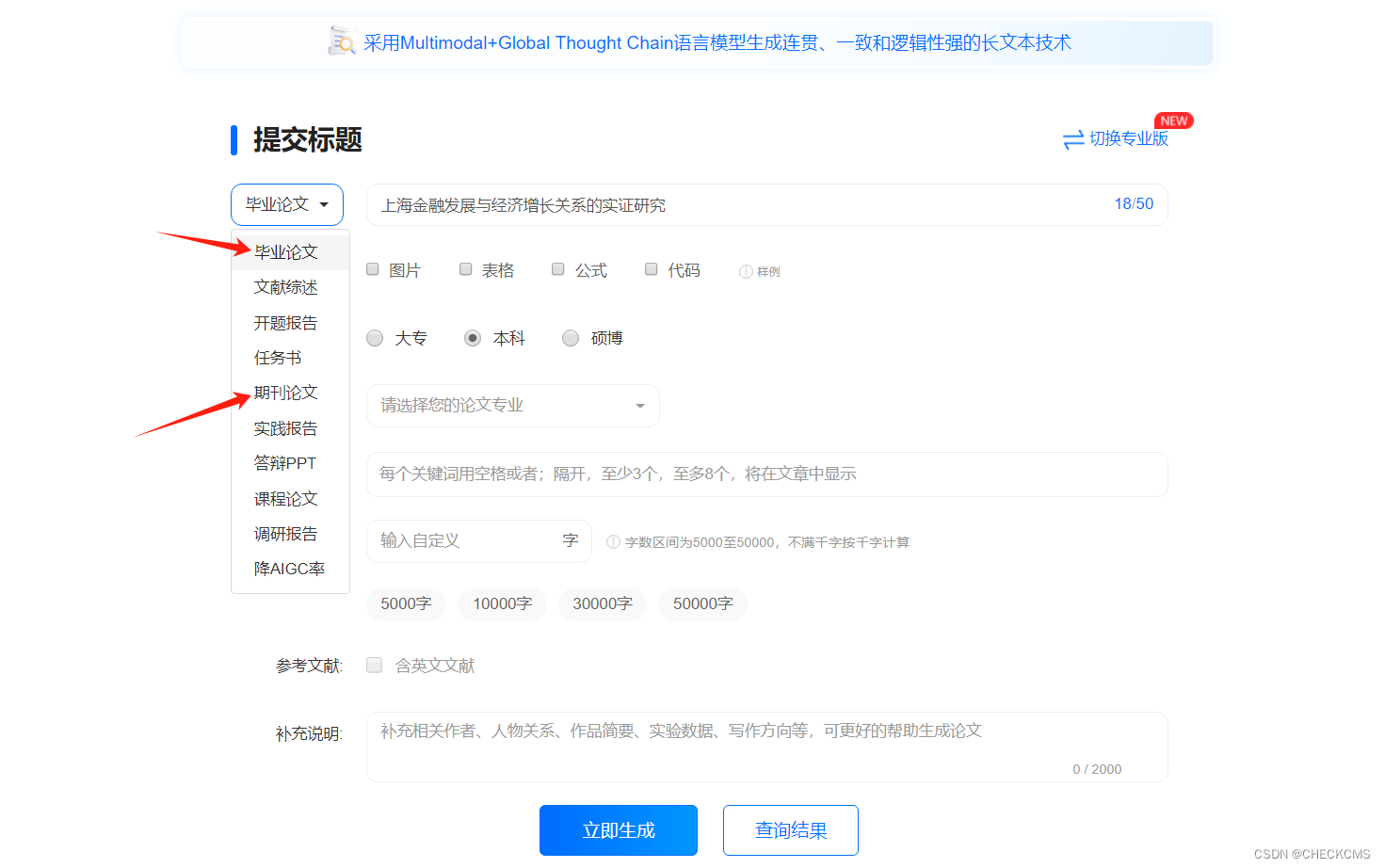
3、确认订单时,在增值服务里面对“实证数据”进行勾选,即可生成一篇带有实证数据的论文。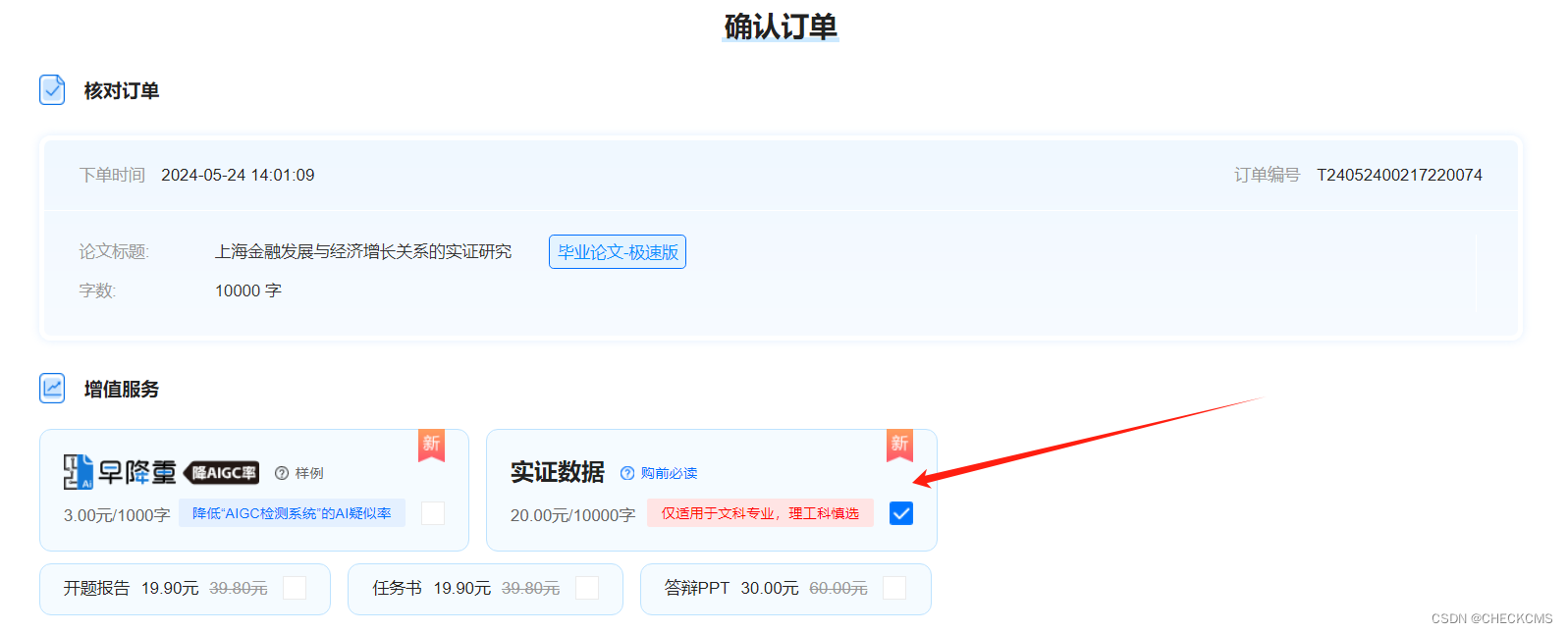
虽然AI生成的论文,无法完全取代人类的思考和创作,但AI可以通过大数据分析和机器学习算法,从海量的数据中提取出符合逻辑关系的实证数据,有着它独特优势,为学者的研究快速地获取所需的数据支持。
这篇关于文科论文,使用AI写作时能够提供实证数据吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





