本文主要是介绍【高时效通路】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一 高时效通路
1.1 pathchdumper
实时数据拉取、实时数据处理、5分钟微批dump来加速时效性,具体来说:
- 实时数据拉取(Fetcher):基于Databus Fetcher基建,直接对接F0层实时拉取最新数据,保证该节点常态秒级延迟;
- 实时数据处理(AdTable):面向Databus数据格式,有效实践是类似于BS广告库服务,基于AdTable实时加载和用户UDF能力保证数据处理秒级延迟;
- 5分钟微批dump(Logger):新增Logger功能,通过记录增量数据触发的表结构变化,并经过数据格式转换形成下游所需增量文件;
- 数据固化(Uploader):复用Databus Uploader基建,将5分钟级Patch文件写入AFS。
说人话:
-
定时执行heart_beat操作(可配置),对全局idea_map进行遍历(跟随ideatable更新),根据status对大宽表进行insert、remove
-
insert/remove的过程中执行logger,将大宽表数据存入buffer,buffer以idea_id为key,在dump固化到磁盘前,再次logger,新数据可覆盖旧数据
-
loader读增量文件至文件切换时dump buffer中数据,固化到磁盘
-
uploader上传文件至afs
1.1.1 为何使用大宽表
-
一条完整的广告增量是<winfo, idea>,而不是某个单一层级,这就决定了高时效通路中需要有可做层级join的能力。一条广告是基于idea层级从同unit下优选出一条winfo
-
ann建库时最终用户(数据使用方)拿到的是一条完整Join好的有效数据。这意味着,下游拿到的一条Patch数据Record中,包含了有效的Idea层级、Unit层级、Plan层级数据
1.1.2 Heartbeat如何工作
custom_heart_beat的具体逻辑:
定期执行heart_beat操作(可配置),对全局idea_map进行遍历,根据其status对大宽表进行增删改
主函数 custom_heart_beat(FeedBsTables* p_handle)
遍历全局创意map, for (auto& [idea_id, status] : context._global_idea_map)
然后判断idea对应的状态标记
1. 状态为需要移除
- 从宽表中删除该广告
- 从全局的创意映射表中移除该创意
2、状态为其他
- 插入、更新、无变化,调用completeness_check方法进行检查, completeness_check(p_handle, status.first, idea_id);
其中,completeness_check函数
-
get_common_info读取广告基础信息(user_id、plan_id、unit_id、user_main_version、plan_main_version、unit_main_version、winfo_main_version)
-
校验USER、PLAN、UNIT、WINFO 四个层级的version,通过check_version函数进行主辅表verison状态判断:
-
辅表version不存在(辅表已下发删除增量),需要删除业务宽表VERSION_UNEQUAL_REMOVE
-
主辅表version相同,表示字段没有变动VERSION_EQUAL
-
主辅表version不相等, 需要更新业务宽表VERSION_UNEQUAL_UPDATE
-
-
判断主辅表状态
-
如果结果是VERSION_UNEQUAL_REMOVE
-
表示辅表join失败不做操作
-
return 0;
-
-
如果结果是VERSION_UNEQUAL_UPDATE
-
如果在宽表中的一定不是新广告, 仅更新version
-
1. winfo优选choose_best_winfo_id
-
优选条件 target_type == 32 && intent_type == 16 && intent_name_id == 999999, 表示智能定向广告
-
不符合则随机抽一条
-
-
2. 业务宽表字段填充fill_wide_idea_tuple
-
3. 多样性控制winfo_customer_control
-
get_freq, 使用map实现频率计数,并设定key的过期时间
-
-
4. 新广告插入到业务宽表中 p_handle->wide_idea_table()->insert(tuple);
-
5. version更新update_version
-
-
dump服务中,dump的框架需要能够实现周期性 dump base,patch数据的能力,以及根据业务需求可以根据定期(按照处理条数或时间间隔)触发提条heartbeat消息的能力,这样业务可以根据 heartbeat 消息来实现一些特定的业务逻辑。
那么 trigger 应该由谁来触发呢?
-
对于业务需求的 heartbeat 而言,则需要单独增量一个条数和时间的计数器,以便在到达用户配置的条件时,生成一条heartbeat数据,该逻辑在 loader 中实现也比较合理。
综上,需要在 loader 中增加 trigger 的能力,来 cover 上述场景。
trigger 只需要在加载增量时进行触发即可(应该会有返回值,告诉上游,什么时候可以开始启动服务了)
1.1.3 Logger是如何实现的
对于patch 数据,我们是需要记录下对 table 的修改,相当于记录一个 log。 log则是以5分钟的粒度(和增量文件的粒度对接)进行组织。
增量数据到来后,会对两类Table 进行修改: MemDataTable 和 IndexTable,因此我们只需要对这两类 Table 的 modify接口进行封装,在数据更新时,将数据同时也更新到patch logger 中,就可以实现对table的修改记录。
-
MemDataTable的 modify 接口包括:
-
insert(tuple)
-
remove(tuple)
-
-
IndexTable 的 modify接口包括:
-
insert(key, tuple)
-
remove(key)
-
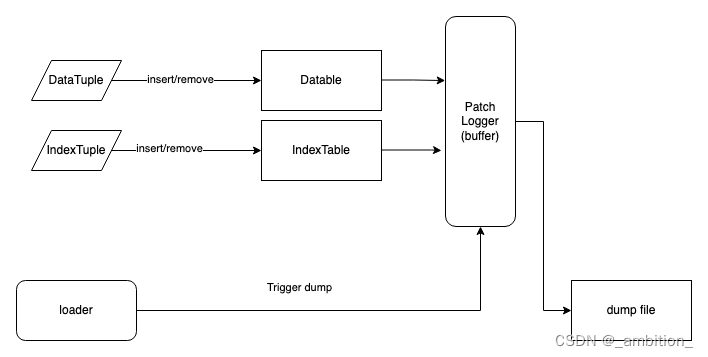
为了保证数据记录Patch Logger的性能,需要在内部为每个需要 dump 的table 配置一个buffer(buffer 大小可配,不同 table可以配不同的 buffer size)。当 buffer满时,可以自动 spill 到本地磁盘。在 trigger patch dump 时,会将 buffer全部 flush 到本地磁盘。因为 Loader 在处理增量时是单线程的,所以当 Loader 触发 dump 时,上一条数据已经被处理完,不会有数据丢失的问题。
Buffer 用HashMap来实现,这样,对于同一个 key 对应的数据,我们可以只保留最新的一个修改,以实现一定程度的 compaction。注意:这里如果一次 patch数据量过多,可能生成多轮 buffer,那么最终的dump 文件中还是可能造成数据的重复的。
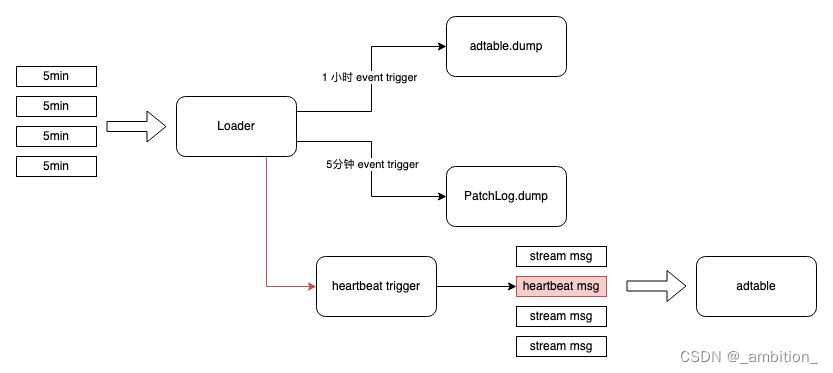
1.1.4 patchdump何时工作
5分钟增量文件读完后开始dump
-
我们希望 patch的粒度可以和databus 的增量文件对齐,那么loader 来触发 adtable 的 dump 是一个很直接的想法。当loader可以识别到增量文件的切换,当文件发生切换时,向 PatchLog 发送一次 dump 请求,PatchLog将本次Patch的数据 flush到本地目录。
-
对于base dump,为了可以和 patch 的时间对齐,同样也使用增量文件的切换来触发 base 数据的 dump,即,当前一个5分钟的增量文件处理完成后,此时满足需要 dump 的周期,则触发一次table表的dump到本地目录。
-
1.1.3 不同表的版本同步问题
CDC(Change Data Capture)数据同步:
-
https://en.wikipedia.org/wiki/Change_data_capture
-
Change Data Capture (CDC): The Complete Introduction | Confluent
基准:ETL
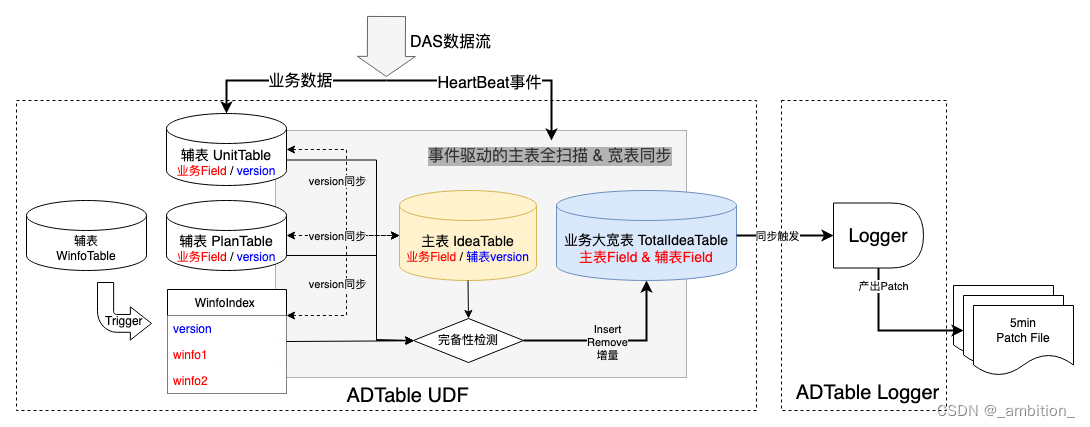
独立业务宽表的方案,将主表和基于主表的业务宽表独立。
[流程图]
如图所示,在这种方案中,我们一共有三种表:
-
主表:IdeaTable。该表包含所有主表的业务字段,此外还需要存储相关Right Join辅表的数据版本version。
-
辅表:Right Join的业务表,如UnitTable,PlanTable。该表包含辅表自身的业务字段,此外还包含没调记录的数据version。
-
业务大宽表:业务大宽表为最终的业务方也需要的物理实体宽表,该表对接Logger,用于产出最终分片,其上挂载了业务方所需要的所有主表和辅表Field。
1.2 processor
1.3 xct
1.4 indexplus
这篇关于【高时效通路】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






