本文主要是介绍Elasticsearch 分析器的高级用法一(同义词,高亮搜索),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Elasticsearch 分析器的高级用法一(同义词,高亮搜索)
- 同义词
- 简介
- 分析使用
- 同义词案例
- 高亮搜索
- 高亮搜索策略
- unified
- plain
- vh
同义词
简介
在搜索场景中,同义词用来处理不同的查询词,有可能是想表达相同的搜索目标。
例如:查询“北京大学”和“北大”时,其实时想搜索同一个内容。
在ES内置的分词过滤器中,有两个同义词分词过滤器(synonym 和 synonym_graph)
官网:
synonym: https://www.elastic.co/guide/en/elasticsearch/reference/7.10/analysis-synonym-tokenfilter.html
synonym_graph: https://www.elastic.co/guide/en/elasticsearch/reference/7.10/analysis-synonym-graph-tokenfilter.html
synonym_graph 相对于 synonym 对于多词同义词有更精确的效果

官方建议,在索引时使用 synonym ,在 查询时 使用 synonym_graph
分析使用
可以借助同义词过滤器实现 同义词分析器
指定同义词内容,有两种方式
- 直接通过synonyms 指定,同义词用 , 分割
# synonym
POST _analyze
{"tokenizer": "ik_smart","filter": {"type": "synonym","synonyms": ["北京大学, 北大"]},"text": "北京大学"
}
- 通过文件方式指定 同义词
- 在 es/config 目录下 创建文件 analysis/synonym.txt
- 在 synonym.txt 中编辑同义词内容

# 通过文件方式指定同义词
POST _analyze
{"tokenizer": "ik_smart","filter": {"type": "synonym","synonyms_path": "analysis/synonym.txt"},"text": "北京大学"
}
上述两种请求方式,结果相同,如下:

从结果可以看出,北京大学 和 北大 都被当做同义词分析。
同义词案例
案例要求:通过大学简称或全称都能搜索到对应大学的内容
-
创建大学索引
# 创建一个索引 # 包含一个text字段,索引分析器为 ik_smart # 搜索分析器为自定义的 同义词分析器,同义词内容在analysis/synonym.txt 中 # "updateable": true 表示允许动态修改同义词 PUT /college {"settings": {"index": {"analysis": {"analyzer": {"my_synonyms": {"tokenizer": "ik_smart","filter": [ "synonym" ]}},"filter": {"synonym": {"type": "synonym_graph","synonyms_path": "analysis/synonym.txt", "updateable": true }}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "ik_smart","search_analyzer": "my_synonyms" }}} } -
指定同义词
在 analysis/synonym.txt 文件中 写入同义词 ”北京大学,北大“
-
初始化数据
POST /college/_bulk {"index":{}} {"content":"北大,国内最高学府"} {"index":{}} {"content":"北外,中华人民共和国教育部直属的全国重点大学,211"} -
测试搜索
GET /college/_search {"query": {"match": {"content": "北京大学"}} }
-
修改同义词文件
上述同义词文件中,没有指定 北外 和 北京外国语。所以直接搜索北京外国语大学是没有结果的。
这时,我们需要动态的添加新的 同义词。
ES官方提供了 修改分析器资源的 APIPOST /{index}/_reload_search_analyzers
并要求必须指定"updateable": true我在创建索引时 ,已经指定了
"updateable": true,这里可以直接修改 synonym.txt 文件a. 添加 同义词
echo 北京外国语大学,北外,北京外国语 >> synonym.txt
b. 发送请求 重新加载分析器资源
POST /college/_reload_search_analyzers -
测试搜索
GET /college/_search {"query": {"match": {"content": "北京外国语大学"}} }
高亮搜索
“高亮显示”的英文为highlight,是指在搜索结果中通过对文档标题的部分匹配字符串进行颜色(如红色)或者字体(如加粗)等处理,在视觉呈现上使匹配的字符串与未匹配的字符串有明显的区分效果。
ES 提供了高亮搜索功能
下面搜索content 字段,并对搜索内容进行高亮显示
PUT /light
{"mappings": {"properties": {"content":{"type":"text"}}}
}POST /light/_bulk
{"index":{}}
{"content":"北京大学,国内最高学府,211,985"}
{"index":{}}
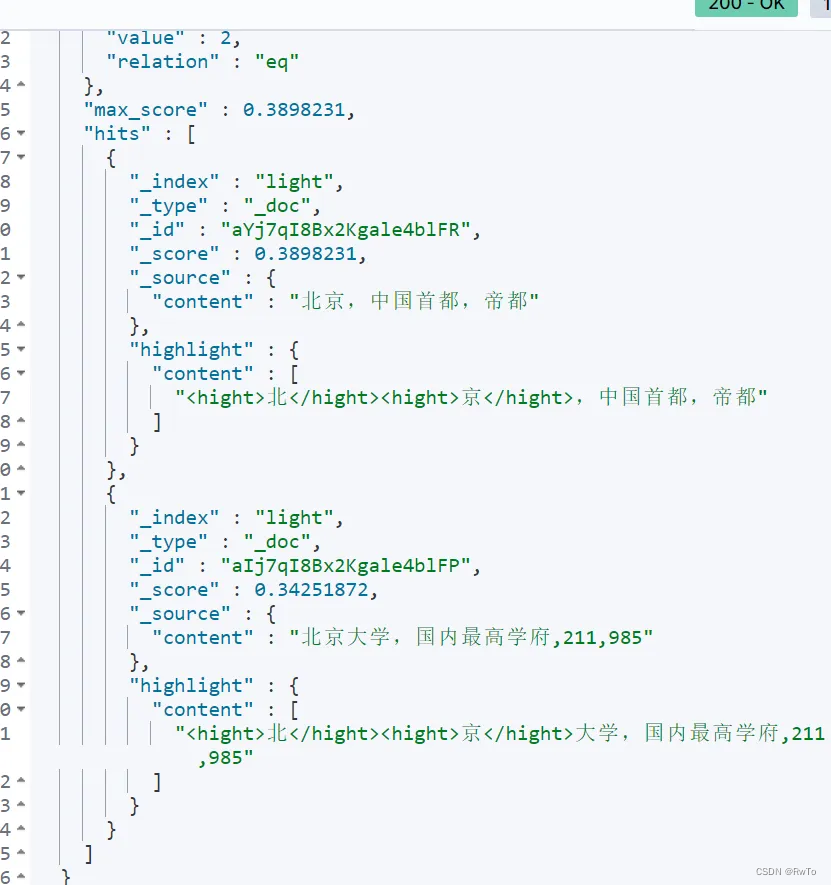
{"content":"北京,中国首都,帝都"}GET /light/_search
{"_source": "content","query": {"match": {"content": "北京"}},"highlight": {"fields": {"content": {// 设定 高亮搜索策略,默认是unified"type":"plain",// 设定 高亮标签,默认是<em></em>"pre_tags": "<hight>","post_tags": "</hight>"}}}
}
高亮搜索策略
ES支持的高亮显示搜索策略有plain、unified和fvh,用户可以根据搜索场景进行选择。
unified
默认策略
unified策略是由Lucene Unified Highlighter来实现的,其使用BM25(Best Match25)算法进行匹配
plain
plain是精准度比较高的策略,因此它必须将文档全部加载到内存中,并重新执行查询分析。由此可见,plain策略在处理大量文档或者大文本的索引进行多字段高亮显示搜索时耗费的资源比较严重。因此plain策略适合在单个字段上进行简单的高亮显示搜索。
vh
为了弥补上述两种策略在大文本索引高亮显示搜索时的速度低问题,Lucene还提供了基于向量的高亮显示搜索策略fvh(fast vector highlighter)。fvh策略更适合在文档中包含大字段的情况(如超过1MB)下使用,如果计算机的I/O性能更好(如使用SSD),则fvh策略在速度上的优势更加明显。
如果要使用fvh策略进行高亮显示搜索,需要设定字段的 term_vector属性值为with positions offsets。
这篇关于Elasticsearch 分析器的高级用法一(同义词,高亮搜索)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






