aiohttp专题

Python 中 requests 与 aiohttp 在实际项目中的选择策略详解
《Python中requests与aiohttp在实际项目中的选择策略详解》本文主要介绍了Python爬虫开发中常用的两个库requests和aiohttp的使用方法及其区别,通过实际项目案... 目录一、requests 库二、aiohttp 库三、requests 和 aiohttp 的比较四、requ
【python 异步编程】10分钟快速入门aiohttp教程
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。人工智能教程 一、先搞清楚什么是同步编程和异步编程? 同步编程:接到上峰指令:有两件事当天要处理完成,越快越好。那么同步是怎么工作呢,第一时间接到指令后,先处理第一件事情,等第一件事情做完了,再做第二件事情,通俗讲就是有点类似工

【python 异步编程】python异步编程之asyncio+aiohttp
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。人工智能教程 asyncio 这个库是官网非常推荐的一个实现高并发的一个异步编程模块。 在学习asyncio之前,我们先来理清楚同步/异步的概念: ·同步是指完成事务的逻辑,先执行第一个事务,如果阻塞了,会一直等待,直到这个
python install aiohttp
在python3.6.3下,windows系统中最后成功安装’aiohttp==1.3.3’的步骤如下: pip3 install multidict pip3 install chardet pip3 install yarl==0.9.8 pip3 install aiohttp==1.3.3 pip install aiohttp

aiohttp遇到非法字符的处理(UnicodeDecodeError: 'utf-8' codec can't decode bytes in position......)
这个问题困扰了我将近一天时间,如果使用text()函数会一直报“UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 24461-24462: invalid continuation byte”的错误,如果使用read()函数以二进制输出在后面解析的时候中文是乱码,网上查了很多资料,主要也是自己的疏忽自己看了源码,一直纠
Python随记:【Python异步编程(四)】——aiohttp
如果需要并发http请求怎么办呢,通常是用requests,但requests是同步的库,如果想异步的话需要引入aiohttp。这里引入一个类,from aiohttp import ClientSession,首先要建立一个session对象,然后用session对象去打开网页。session可以进行多项操作,比如post, get, put, head等。 aiohttp异步实现实例: i

python爬虫之aiohttp多任务异步爬虫
python爬虫之aiohttp多任务异步爬虫 爬取的flash服务如下: from flask import Flaskimport timeapp = Flask(__name__)@app.route('/bobo')def index_bobo():time.sleep(2)return 'Hello bobo'@app.route('/jay')def index_jay():
异步爬虫:aiohttp 异步请求库使用:
使用requests 请求库虽然可以完成爬虫业务,但是对于异步任务来说,它是做不到的, 这时候我们需要借助 aiohttp 异步请求库来完成异步爬虫的编写: 话不多说,直接看示例: 注意:楼主使用的python版本是最新的,3.12的py版本, 另外pycharm使用的也是最新版的 2024版本的。 请务必与我保持一致, 否则会报很多莫名其妙的异常信息。 下载: 使用aiohttp 异步请
【Python】探索Python中的aiohttp:构建高效并发爬虫
后来 我总算学会了 如何去爱 可惜你 早已远去 消失在人海 后来 终于在眼泪中明白 有些人 一旦错过就不再 🎵 HouZ/杨晓雨TuTu《后来》 在数据密集和网络密集的任务中,提高程序的执行效率是非常重要的。Python作为一门强大的编程语言,提供了多种并发处理的解决方案,其中asyncio库是处理异步IO操作的标准库之一,而aiohttp则是
涛哥聊Python | aiohttp,一个有趣的 Python 库!
本文来源公众号“涛哥聊Python”,仅用于学术分享,侵权删,干货满满。 原文链接:aiohttp,一个有趣的 Python 库! 大家好,今天为大家分享一个有趣的 Python 库 - aiohttp Github地址:https://github.com/aio-libs/aiohttp 在Python异步编程领域中,aiohttp库以其强大的功能成为构建高效可扩展的Web应用程序的重

异步爬虫实践攻略:利用Python Aiohttp框架实现高效数据抓取
在当今信息爆炸的时代,数据是无处不在且变化迅速的。为了从海量数据中获取有用的信息,异步爬虫技术应运而生,成为许多数据挖掘和分析工作的利器。本文将介绍如何利用Python Aiohttp框架实现高效数据抓取,让我们在信息的海洋中快速捕捉所需数据。 异步爬虫介绍 异步爬虫是指在进行数据抓取时能够实现异步IO操作的爬虫程序。传统的爬虫程序一般是同步阻塞的,即每次发送请求都需要等待响应返回后才能进行
Python中requests、aiohttp、httpx性能对比
在Python中,有许多用于发送HTTP请求的库,其中最受欢迎的是requests、aiohttp和httpx。这三个库的性能和功能各不相同,因此在选择使用哪个库时,需要考虑到自己的需求和应用场景。 首先,让我们来了解一下这三个库的基本介绍。 requests 是一个简单易用的HTTP库,它可以发送HTTP请求和处理HTTP响应。它的API简单易用,可以轻松地实现HTTP请求和响应的处理。
python爬虫--aiohttp使用
1.aiohttp的简单使用(配合asyncio模块) import asyncio,aiohttp async def fetch_async(url): print(url) async with aiohttp.request(“GET”,url) as r: reponse = await r.text(encoding=“utf-8”) #或者直接await r.read()

aiohttp 目录遍历漏洞(CVE-2024-23334)
免责声明:文章来源互联网收集整理,请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该文章仅供学习用途使用。 Ⅰ、漏洞描述 aiohttp是一个用于异步网络编程的Python库,支持客户端和服务器端的网络通信。它利用Python的asyncio库来实现异步IO操作,这意味着它

利用aiohttp异步爬虫实现网站数据高效抓取
前言 大数据时代,网站数据的高效抓取对于众多应用程序和服务来说至关重要。传统的同步爬虫技术在面对大规模数据抓取时往往效率低下,而异步爬虫技术的出现为解决这一问题提供了新的思路。本文将介绍如何利用aiohttp异步爬虫技术实现网站数据抓取,以及其在实际应用中的优势和注意事项。 一、aiohttp简介 aiohttp是一个基于asyncio的异步HTTP客户端/服务器框架,它提供了一种简单而
aiohttp的异步爬虫使用方法
aiohttp是python3的一个异步模块,分为服务器端和客户端。廖雪峰的python3教程中,讲的是服务器端的使用方法。均益这里主要讲的是客户端的方法,用来写爬虫。使用异步协程的方式写爬虫,能提高程序的运行效率。 1、安装 Python pip install <span class="wp_keywordlink_affiliate"
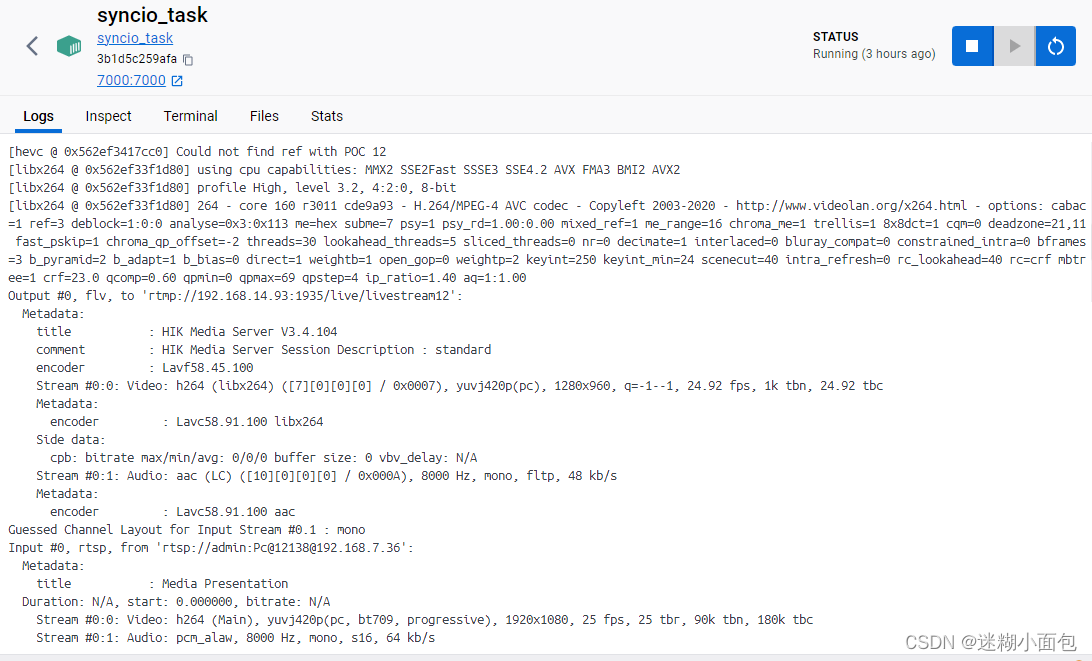
(aiohttp-asyncio-FFmpeg-Docker-SRS)实现异步摄像头转码服务器
1. 背景介绍 在先前的博客文章中,我们已经搭建了一个基于SRS的流媒体服务器。现在,我们希望通过Web接口来控制这个服务器的行为,特别是对于正在进行的 RTSP 转码任务的管理。这将使我们能够在不停止整个服务器的情况下,动态地启动或停止摄像头的转码过程。 Docker部署 SRS rtmp/flv流媒体服务器-CSDN博客文章浏览阅读360次,点赞7次,收藏5次。SRS(Simple Rea
python爬虫控制aiohttp并发数量
前言 在使用aiohttp并发访问多个页面时效率,明显比串行requests快很多,但是也存在一个问题,就是网站检测到短时间内请求的数量过多会导致页面请求不成成功,页面返回429 (too many requests)。 解决上述问题目前想到两个方法: 1、控制请求的时间,用sleep延时,来消耗每一次访问的时间,减少单位时间内的访问量,这样肯定是可以,但效率太低 2、控制并发数量,控制并发数量,
【小沐学Python】Python实现Web服务器(aiohttp)
文章目录 1、简介2、下载和安装3、代码测试3.1 客户端3.2 服务端 4、更多测试4.1 asyncio4.2 aiohttp+HTTP服务器4.3 aiohttp+爬虫实例4.4 aiohttp+requests比较 结语 1、简介 https://github.com/aio-libs/aiohttp https://docs.aiohttp.org/en/stable/
asyncio oracle 异步,Python使用asyncio+aiohttp异步爬取猫眼电影专业版
asyncio是从pytohn3.4开始添加到标准库中的一个强大的异步并发库,可以很好地解决python中高并发的问题,入门学习可以参考官方文档 并发访问能极大的提高爬虫的性能,但是requests访问网页是阻塞的,无法并发,所以我们需要一个更牛逼的库 aiohttp ,它的用法与requests相似,可以看成是异步版的requests,下面通过实战爬取猫眼电影专业版来熟悉它们的使用: 1. 分

Python 利用aiohttp异步流式下载文件
背景 本篇文章为小编翻译文章,小编在查找资料时看到的一篇文章,看了后感觉不错,就翻译过来,供大家参考学习 文章原文地址:https://www.slingacademy.com/article/python-aiohttp-how-to-download-files-using-streams/ Overview 概述 aiohttp 是一个现代库,为Python提供异步(协程)HTTP客

Python中利用aiohttp制作异步爬虫及简单应用
摘要: 简介 asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块。关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架——aiohttp,它可以帮助我们异步地实现HTTP请求,从而使得我们的程序效率大大提高。 简介 asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块。关于asynci

Python异步网络编程利器——详解aiohttp的使用教程
一、引言 在现代Web应用程序开发中,网络请求是非常常见的操作。然而,传统的同步网络请求方式在处理大量请求时会导致性能瓶颈。为了解决这个问题,Python提供了aiohttp库,它是一个基于异步IO的网络请求库,可以实现高效的并发网络请求。本文将详细介绍aiohttp的各种使用方法,帮助你更好地理解和使用这个强大的工具。 二、安装和导入 在开始使用aiohttp之前,我们需要

小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Linux基础入门 小白学 Python 爬虫(4):前置准备(三)Docker基础入门 小白学 Python 爬虫(5):前置准备(四)数据库基础 小白学 Python 爬虫(6

用asyncio和aiohttp异步协程爬取披露易网站港资持股数据
这是本人毕设项目的一部分,也是比较核心的部分。 请自觉遵守相关法律法规,若侵权请联系本人立刻删除。 任务描述 爬取披露易网站上的港资持股A股详细股东数据。点击搜索栏下方的持股名单我们可以看到港资持股的股份名单。 任务分为三部分: 首先需要爬取港资持股名单根据持股名单依次搜索爬取机构详细持股数据将爬取到的数据存入到mysql数据库中 我们以股份【四川成渝高速公路,00107】为例,点击搜

异步爬虫实战:实际应用asyncio和aiohttp库构建异步爬虫
在网络爬虫的开发中,异步爬虫已经成为一种非常流行的技术。它能够充分利用计算机的资源,提高爬虫效率,并且能够处理大量的运算请求。Python中的asyncio和aiohttp库提供了强大的异步爬虫支持,使得开发者能够轻松构建高效的异步爬虫。 什么是异动爬虫?为什么要使用自动爬虫? 异步爬虫是一种高效的爬取网页数据的方式,它可以同时处理多个请求,提高爬取速度,并减少资源的浪费。传统的爬虫是同步的,即