选举专题
分布式系统理论进阶:选举、多数派和租约
GitHub:https://github.com/wangzhiwubigdata/God-Of-BigData 关注公众号,内推,面试,资源下载,关注更多大数据技术~大数据成神之路~预计更新500+篇文章,已经更新50+篇~ 选举(election)是分布式系统实践中常见的问题,通过打破节点间的对等关系,选得的leader(或叫master、co

【大数据哔哔集20210124】有人问我Kafka Leader选举?我真没慌
一条消息只有被ISR中所有Follower都从Leader复制过去才会被认为已提交。这样就避免了部分数据被写进了Leader,还没来得及被任何Follower复制就宕机了,而造成数据丢失。而对于Producer而言,它可以选择是否等待消息commit,这可以通过request.required.acks来设置。这种机制确保了只要ISR中有一个或者以上的follower,一条被commit的消息就不

hashicorp/raft 介绍与源代码分析(二): 领导人选举(二)
回顾 上章提到,基于节点的 keyCurrentTerm 、LastLogTerm 、 LastLogIndex 3 个持久化数据,在选举时,可以确定领导者 选择领导者的依据是哪个节点 log 最全,选谁 但是有附加条件的,该节点 log 最全,并且其他节点已经应用到状态机的 log ,该节点必须有 因此,不是所有情况下选举一定能成功的 最坏的情况下,找不到符合条件的 log 落地日志拥

vrrp协议,主备路由器的选举
当VRRP备份组中的所有备份路由器(BACKUP)具有相同的优先级时,选举新的主路由器(MASTER)的过程将基于以下规则: IP地址优先:如果备份路由器的优先级相同,那么具有最高IP地址的路由器将被选举为新的主路由器。这是因为在VRRP协议中,IP地址作为一种简单的选举机制,可以决定在优先级相同的情况下哪个路由器将成为主路由器。选举过程: 当主路由器失效,或者备份路由器没有接收到来自主路由器

fabric 主节点选举过程
1. 静态指定主节点2. 动态选举主节点3. 参考资料 每个组织都有一个或多个主节点与排序节点进行连接,但是过多的节点与排序节点进行通讯无疑会占用过多的带宽。为了灵活利用带宽,Fabric 提供两种方式指定主节点: 静态指定:系统管理员可以自定义配置一个或多个节点作为该组织的主节点;动态选举:节点可以通过选举选择一个节点作为主节点。 这两种方式都可以通过修改 core.yaml 的 useL

Kafka 不同步的副本首领选举探究
测试版本模拟场景测试结果相关建议 测试版本 kafka 1.1.1 模拟场景 依次挂掉集群每一台机器,但是中间不间断发消息,然后按照挂掉的顺序依次重启 测试程序采用每10s发送一批消息,在中间停顿这10s有序停止副本。然后再顺序重启 测试结果 如果启动的是未同步的副本,那么集群就不会处理生产者和消费者的请求。 因为在0.11版本默认改为关闭不完全副本首领选举。需要
![[etcd]raft总结/选举/数据同步,协议缺陷与解决/Multi Raft](https://i-blog.csdnimg.cn/blog_migrate/d647e80325d7ae7cffcb4081a74b6e75.jpeg)
[etcd]raft总结/选举/数据同步,协议缺陷与解决/Multi Raft
raft协议是multi paxos协议的实现.Etcd、Consu都使用了raft 1.角色 raft协议中包含这几种角色 领导者:带头大哥1.提出提议,但是不需要确认,因为我是大哥;2.复制日志,数据以大哥为准,3,领导者会定时发送心跳,确定自己的位置.告诉小弟老实呆着,一旦心跳超时,小弟就会重新选举大哥. 跟随者:只要大哥发送心跳,我就老实的同步日志.一旦没有心跳,我就变成候选人,开

ZooKeeper 的选举原理
ZooKeeper 可以通过两种方式实现 Master 选举,分别利用了 ZooKeeper 的临时节点和临时有序节点。以下是它们的具体实现方式及原理: 1. 基于临时节点的 Master 选举 在这种方法中,所有参与选举的节点会尝试在 ZooKeeper 中创建一个临时节点,比如 /master-election。由于 ZooKeeper 保证同一层级下节点名称的唯一性,因此只有一个节点能够

Kafka运行机制(一):Kafka集群启动,controller选举,生产消费流程
前置知识 Kafka基本概念https://blog.csdn.net/dxh9231028/article/details/141270920?spm=1001.2014.3001.5501 1. Kafka集群启动 Kafka在启动集群中的各个broker时,broker会向controller注册自己,并且从controller节点同步集群元数据。 broker是Kafka集群中的

Kafka第一篇——内部组件概念架构启动服务器zookeeper选举以及底层原理
目录 引入 ——为什么分布式系统需要用第三方软件? JMS 对比 组件 架构推演——备份实现安全可靠 , Zookeeper controller的选举 controller和broker底层通信原理 BROKER内部组件 编辑 topic创建 引入 ——为什么分布式系统需要用第三方软件? 这里会讨论线程与线程之间的通信以及进程与进程之间的通信。 1.线程与线程之间

每日一练 - IGMP协议与查询器选举机制
01 真题题目 在共享网络中存在多台路由器的情况下,是否是IGMP协议本身负责选举出查询器的角色? A. 正确 B. 错误 02 真题答案 B 03 答案解析 IGMP(Internet Group Management Protocol)互联网组管理协议,主要用于IP多播网络中,帮助主机表达对多播组的兴趣以及让网络设备了解哪些主机(接收者)想要接收特
zookeeper之选举机制 简化易理解
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下: 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,共2票(1票来自自己投票,另一票来自服务器1投票),由于服务器2的编号大所以服务器2胜出,但
POJ 2370选举通过
水题…… #include<iostream>#include<algorithm>using namespace std;int main(){int n,i,a[103],sum1=0,sum2=0;cin>>n;for(i=0;i<n;i++){cin>>a[i];sum1+=a[i];}sum1=(sum1+1)/2;sort(a,a+n);for(i=0;i<(n+1)/2;i
HDU1557权利选举
/*思路:遍历所有2^n个集合,对于每个集合求票和,如果满足票为优胜团体,而再对集合每个成员比较,是否满足变成非优胜团体,是的话,对于该成员对应结果+1。重点:利用二进制思想,所有团体均对应0~2^n-1的一个十进制数对应,而判别团体成员则需要用到位运算,比如团体9,对应的是1001,则包含第四个团体和第一个团体。则判断团体号num,如果((num>>j)&1)==1,则是有该成员。这就是所谓

MongoDB -- 副本集故障恢复PRIMARY的选举
mongoDB副本集,集群通常为奇数,最少3个节点,满足投票选举机制,这里不详述副本集,下面来说下故障的情况 PRIMARY主节点宕机,副本集的SECONDRY会启动选举机制,选出一个新的PRIMARY节点,保证服务的可用。 当宕机节点恢复启动的时候,有2种情况, 1、 宕机节点正常启动,启动后为SECONDRY,不触发重新选举 2、宕机节点启动后,启动后,根据配置的优先级,重新选举PRI
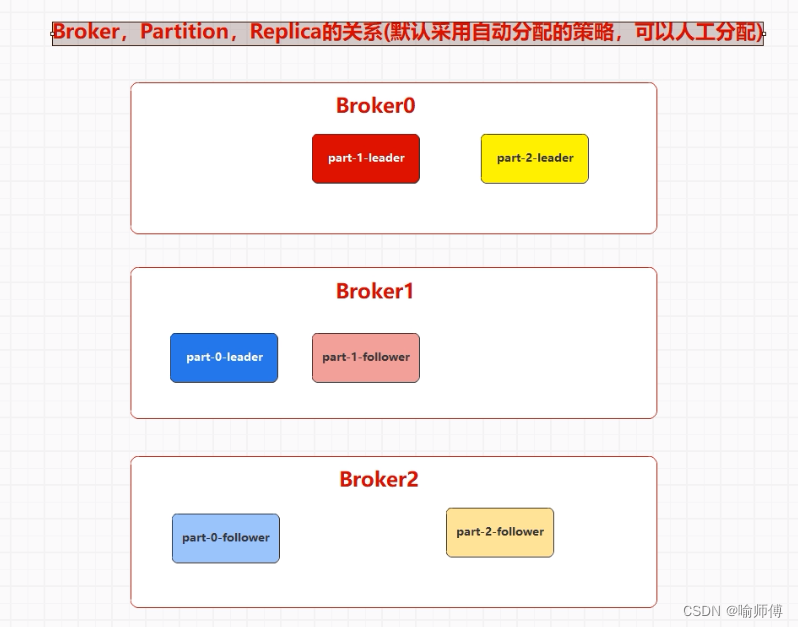
Kafka-核心架构-分区、副本(含副本选举机制)
Kafka概述 Kafka-核心架构-分区 Kafka的分区是将数据在主题(Topic)中逻辑上划分成多个片段的机制。 分区使得数据可以被水平扩展,提高了Kafka的可伸缩性和吞吐量,并允许数据在集群中分布和并行处理。 1.Kafka 分区的作用 (1)数据分布和负载均衡: Kafka通过将数据分割成多个分区并在集群中分布这些分区来实现数据的水平扩展和负载均衡。每个分区可以在集
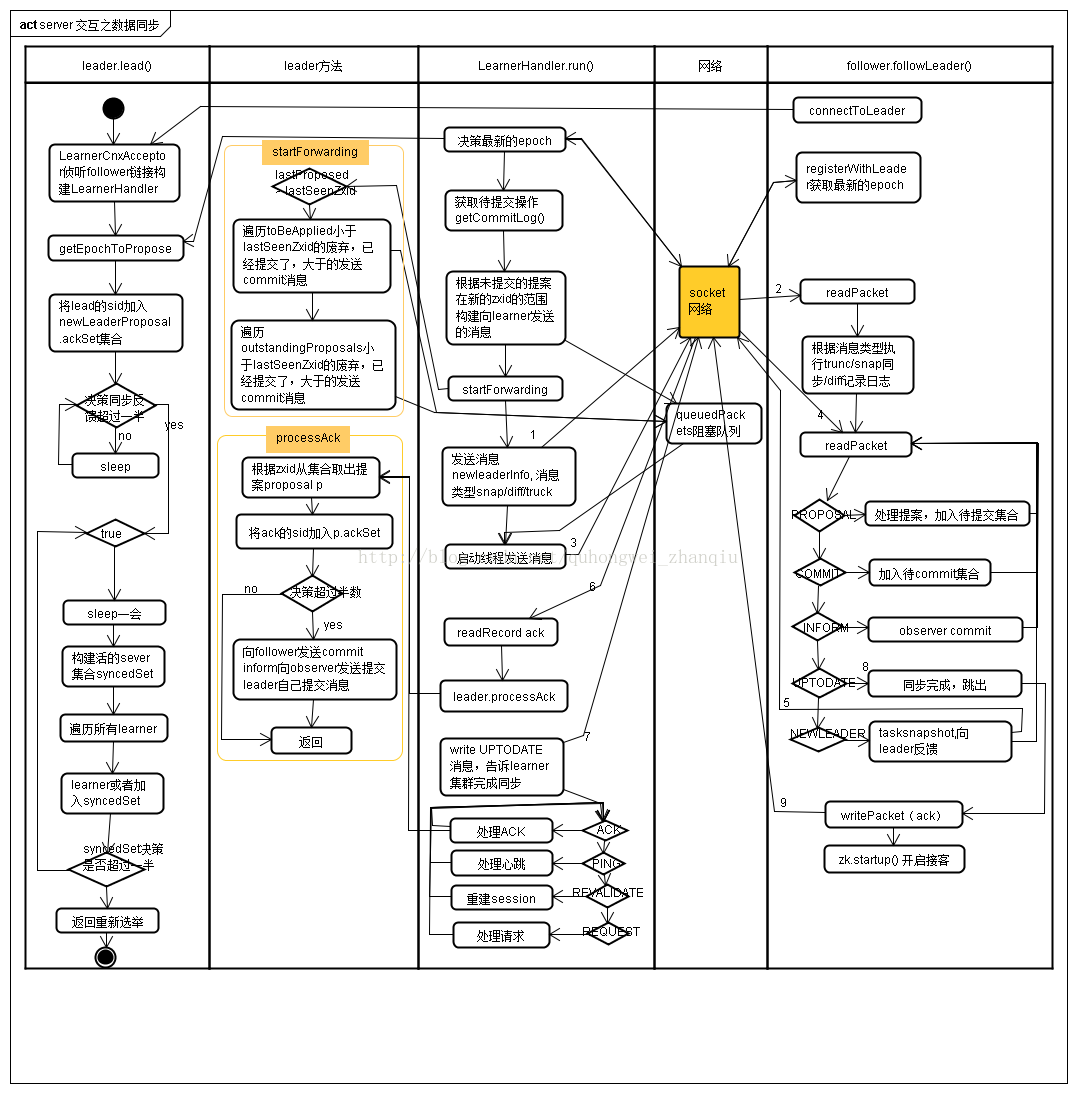
zookeeper原理解析-选举
zookeeper原理解析-选举 1)QuorumPeerMain加载 Zookeeper集群启动的入口类是QuorumPeerMain来加载配置启动QuorumPeer线程。首先我们来看下QuorumPeer, 谷歌翻译quorum是法定人数,定额的意思, peer是对等的意思,那么QuorumPeer中quorum代表的意思就是每个zookeepe
ZooKeeper - Master选举
在分布式系统中,经常会碰到这样的场景:对于一个复杂的任务,仅需要从集群中选举出一台进行处理即可。诸如此类的分布式问题,我们统称为 “Master 选举” ,借助 ZooKeeper,我们可以比较方便的实现 Master选举的功能,其大体思路非常简单: 选择一个根节点,例如 /master_select ,多台机器同时向该节点创建一个 子节点 /master_select/lock,利用 Zoo
面试题:Kafka中Controller的作用是什么?选举流程是怎样的?以及如何避免脑裂问题?
题目来源 网上冲浪:还不懂分布系统,速看深度剖析Kafka Controller选举过程 在查找关于Kafka单机分区的上限以及分区多了会有怎样的问题的时候,发现了这个比较有趣的问题,就记录了下来。 一般所有的分布式系统,都会涉及到这个问题:脑裂、以及如何避免脑裂问题。 题目描述 Kafka中Controller的作用是什么?Kafka中Controller的选举流程是什么?Kafka脑裂是
C++ P1271 【深基9.例1】选举学生会
文章目录 一、题目描述【深基9.例1】选举学生会题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 二、参考代码 一、题目描述 【深基9.例1】选举学生会 题目描述 学校正在选举学生会成员,有 n n n( n ≤ 999 n\le 999 n≤999)名候选人,每名候选人编号分别从 1 1 1 到 n n n,现在收集到了 m m m( m ≤ 2
MongoDB主节点的选举原则
MongoDB在副本集中,会自动进行主节点的选举,主节点选举的触发条件: 主节点故障。主节点网络不可达(默认心态信息为10秒)。人工干预(rs.stepDown(600))。 一旦触发选举,就要根据一定规则来选择主节点。 选举规则是根据票数来决定谁获胜: 票数最高,且获得了“大多数”成员的投票支持的节点获胜。 “大多数”的定义为:假设复制集内投票成员时N,则大多数为N/2+1。例如:3个投票
ZooKeeper 选举机制FasterLeaderElection详解
选举方式选举内容选举机制 ZooKeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是选举模式和同步模式。当服务启动或者在领导者崩溃后,Zab就进入了选举模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,选举模式就结束了。状态同步保证了leader和Server具
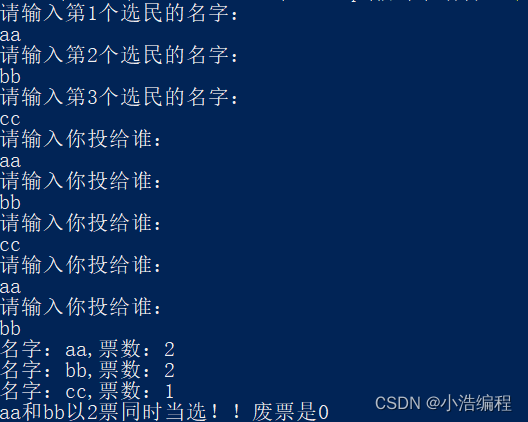
C语言使用结构体模拟选举的小应用
C语言结构体的模拟选举小应用 现在有三个被选举人,五个投票人最后以票高者获胜 小应用中用到了C语言中的结构体作为主要编写主体 上代码 #include <stdio.h>#include <string.h>struct XuanMin{char name[32];int tickets;};int main(){struct XuanMin xm[3];struct XuanMin

zookeeper(三):选举算法
脑裂 网络分区(脑裂): 群集发生管理网络故障时,该群集中的部分主机可能无法通过管理网络与其他主机进行通信。一个群集中可能会出现多个分区。已分区的群集会导致虚拟机保护和群集管理功能降级。请尽快更正已分区的群集。通俗来讲就是一个黑帮中出现了两个老大,所谓一山不容二虎,就造成了领导混乱。我们拿ZooKeeper集群来讲一下脑裂是如何产生的。首先,我们有一个集群,集群里只有一个leader

Zookeeper选举机制 (全程无废话)
🌺个人主页:杨永杰825_Spring,Mysql,多线程-CSDN博客 🎉相关链接:ZooKeeper 有几种角色?-CSDN博客 ⭐每日一句:成为架构师路途遥远 📢欢迎大家:关注🔍+点赞👍+评论📝+收藏⭐️ 目录 前言 第一次选举 非第一次选举 前言 SID: 服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致

raft选举算法和zookeeper选举算法的优略
RAFT(Replicated State Machine)选举算法和ZooKeeper选举算法都是分布式系统中常用的选举算法,用于确定系统中的主节点或领导者。它们有各自的优劣势,下面是对它们进行的简要比较: RAFT选举算法: 优势: 简单易懂:RAFT算法的设计目标之一是易于理解和实现。相比于其他选举算法,它的概念和实现都相对简单,降低了开发和维护的复杂性。 安全性:RAFT算法通过使